



Oracle has established itself as one of the largest vendors of RDBMS (Relational Database Management System) in the IT market since its inception. The query language that can be used to access data in Oracle’s relational databases is SQL. Databricks is an Enterprise Software company that the creators of Apache Spark founded. It is known for combining the best of Data Lakes and Data Warehouses in a Lakehouse Architecture.
This article talks about the methods you can follow to establish Databricks Oracle integration seamlessly. It also gives a brief introduction to Oracle and Databricks before diving into the Databricks Connect to Oracle database methods.
Table of Contents
What is Oracle?

Oracle offers a multi-model Database Management System popularly leveraged for Data Warehousing, Online Transaction Processing, and mixed database workloads. Oracle database runs on various major platforms like Linux, UNIX, Windows, and macOS. The Oracle database was the first database designed for Enterprise Grid Computing, which is the most cost-effective and flexible way to manage information and applications.
Enterprise Grid Computing develops large pools of industry-standard servers and modular storage. This type of architecture allows a new system to be swiftly provisioned from the pool of components. Since capacity can be easily relocated or added from the resource pool as needed, peak workloads are not required. It differs from the other types of computing through provisioning and virtualization.
Grid Computing aims to solve a few common problems faced by Enterprise IT by producing more resilient and lower-cost operating systems. This style of architecture allows Oracle to deliver a comprehensive database at a lower cost with greater flexibility and a higher quality of service. Oracle delivers on-the-grid computing functionality to focus on providing its users with centralized management, robust security infrastructure, universal access, and powerful development tools.
Key Features of Oracle
Here a some of the key features responsible for the immense popularity of Oracle.
- Cross-Platform Integration: Oracle supports and works on all operating systems (OS), including Windows, macOS, Linux, and others.
- Compliant with ACID Attributes: Oracle DB offers ACID (Atomicity, Consistency, Isolation, and Durability) properties to ensure the Database’s integrity during transaction processing.
- Simple Communication: Communication between applications on different platforms is simple. Oracle’s native networking stack allows you to seamlessly interface your database with applications on a variety of platforms. For example, you can simply link and interact with a Unix-based application with your Oracle database (running on Windows).
- Backup and Recovery: Oracle’s backup and recovery capabilities allow it to retrieve data from any accident or technical failure. Oracle’s RAC architecture ensures that all data and processes are backed up.
- Analytics Solutions: You can use Oracle Advanced Analytics and OLAP (Oracle Analytic Processing) to quickly do analytical computations on business data.
Check out the Top 10 Oracle ETL tools to simplify this integration.
What is Databricks?

Databricks is a Cloud-based Data platform powered by Apache Spark. It primarily focuses on Big Data Analytics and Collaboration. With Databricks’ Machine Learning Runtime, managed ML Flow, and Collaborative Notebooks, you can avail a complete Data Science Workspace for Business Analysts, Data Scientists, and Data Engineers to collaborate. Databricks houses the Dataframes and Spark SQL libraries that allow you to interact with Structured data.
With Databricks, you can easily gain insights from your existing data while also assisting you in the development of Artificial Intelligence solutions. Databricks also include Machine Learning libraries for training and creating Machine Learning Models, such as Tensorflow, Pytorch, and many more. Various enterprise customers use Databricks to conduct large-scale production operations across a vast multitude of use cases and industries, including Healthcare, Media and Entertainment, Financial Services, Retail, and so much more.
Key Features of Databricks
Databricks has carved a name for itself as an industry-leading solution for Data Analysts and Data Scientists due to its ability to transform and handle large amounts of data. Here are a few key features of Databricks:
- Delta Lake: Databricks houses an Open-source Transactional Storage Layer meant to be used for the whole Data Lifecycle. You can use this layer to bring Data Scalability and Reliability to your existing Data Lake.
- Optimized Spark Engine: Databricks allows you to avail the most recent versions of Apache Spark. You can also effortlessly integrate various Open-source libraries with Databricks. Armed with the availability and scalability of multiple Cloud service providers, you can easily set up Clusters and build a fully managed Apache Spark environment. Databricks allow you to configure, set up, and fine-tune Clusters without having to monitor them to ensure peak performance and reliability.
- Machine Learning: Databricks offers you one-click access to preconfigure Machine Learning environments with the help of cutting-edge frameworks like Tensorflow, Scikit-Learn, and Pytorch. From a central repository, you can share and track experiments, manage models collaboratively, and reproduce runs.
- Collaborative Notebooks: Armed with the tools and the language of your choice, you can instantly analyze and access your data, collectively build models, discover and share new actionable insights. Databricks allows you to code in any language of your choice including Scala, R, SQL, and Python.
You should also discover how to connect GCP MySQL to Databricks in simple steps.
Why is Databricks Connect to Oracle Database Important?
Here are a couple of reasons why you should consider moving data from Oracle to Databricks:
- Databricks will virtualize storage, therefore, allowing access to data anywhere.
- Picking Databricks for this migration is a more prudent choice since it leverages Data Science to support decision-making.
- Databricks walks the fine line between being out-of-the-box and being too infrastructure-heavy. In comparison, you couldn’t code complex Spark ETL Spark pipelines within the same platform as your storage. Databricks allows you to easily set up your Spark infrastructure, dealing with a lot of moving parts to connect all the dots with scaling compute and storage for your Oracle data.
Understanding Databricks Connect to Oracle Database Methods
Here are the methods you can leverage to establish Databricks Connect to Oracle Database seamlessly:
- Method 1: Using Hevo Data for Databricks Connect to Oracle Database
- Method 2: Manual Steps for Databricks Connect to Oracle Database
Method 1: Using Hevo Data for Databricks Connect to Oracle Database
The following steps can be implemented to connect Oracle to Databricks using Hevo:
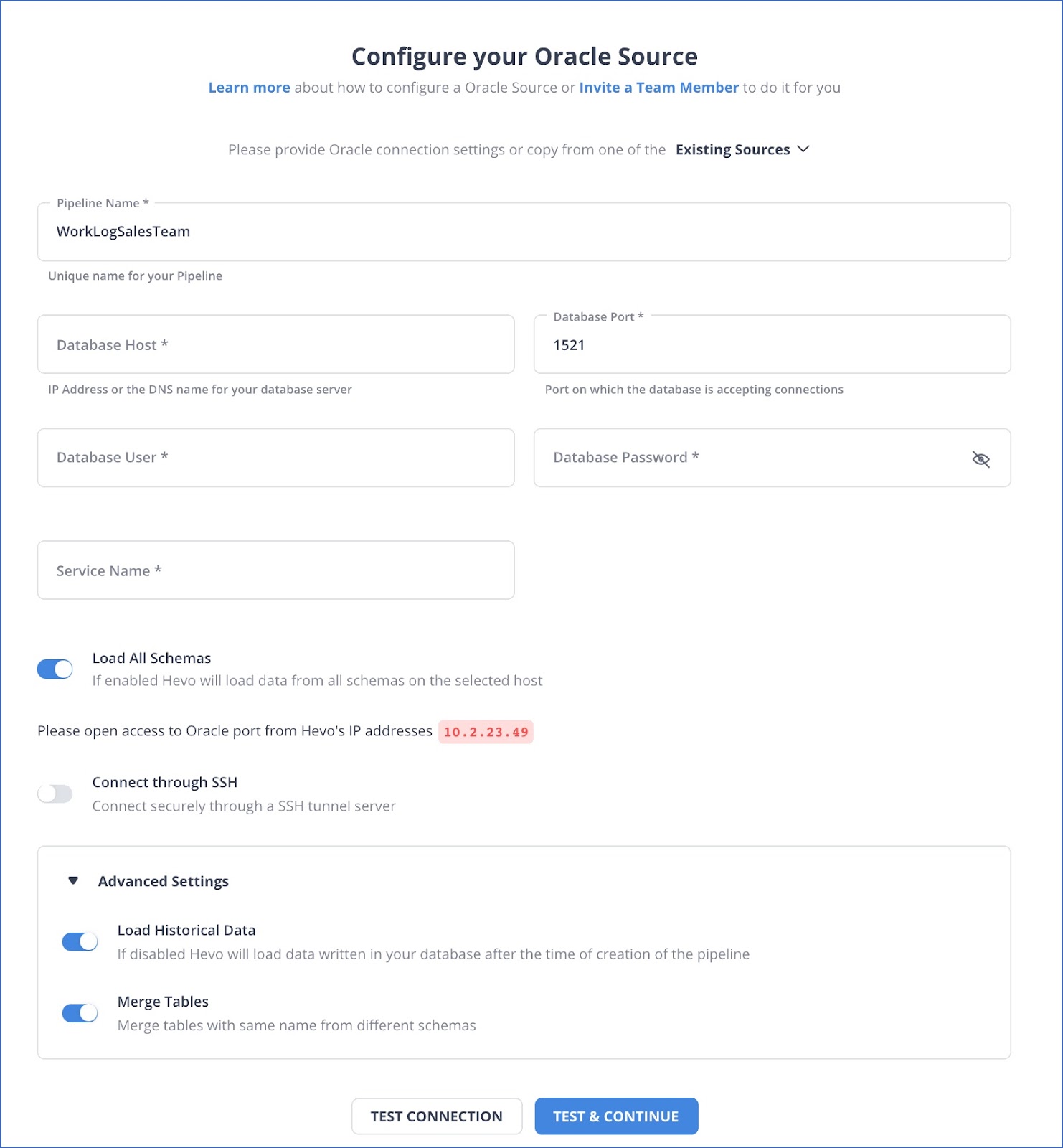
- Configure Source: Connect Hevo Data with Oracle by providing a unique name for your destination along with your database credentials such as username and password. Hevo supports Generic Oracle and Amazon RDS Oracle. To help Hevo connect with your Oracle database, you will also have to provide information such as the host IP, port number, and the name & schema of your database.
- Configure Destination: To connect to your Databricks warehouse you can either create a Databricks SQL endpoint or a Databricks cluster. Next, you need to obtain the Databricks credentials and make a note of the following values:
- Port
- HTTP Path
- Server Hostname
To configure Databricks as a destination in Hevo, execute the following steps:
- Click DESTINATIONS within the Asset Palette.
- Click +CREATE in the Destinations List View.
- Next, on the Add Destination page, choose Databricks.
- In the Configure your Databricks Destination Page, mention the following:
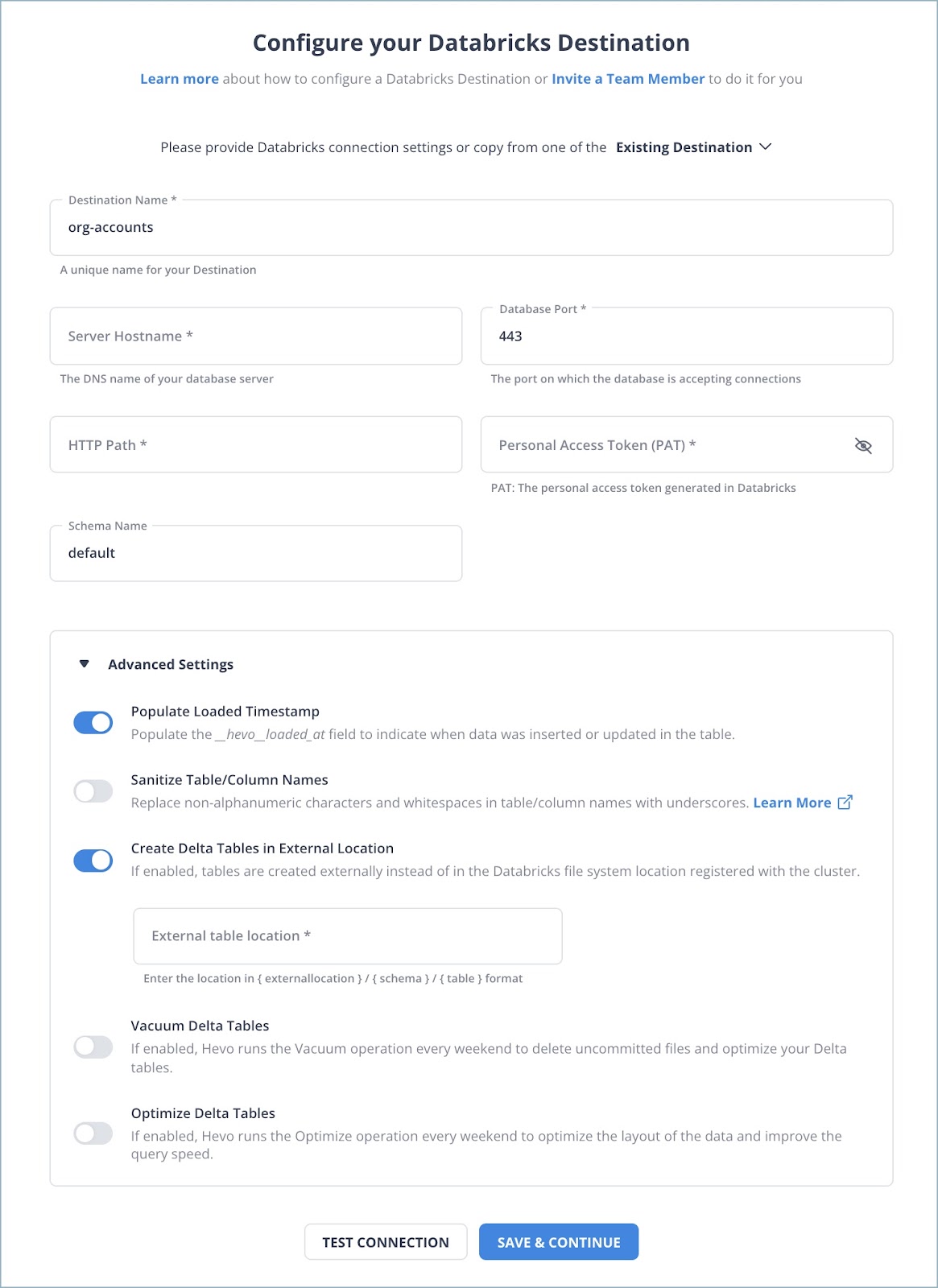
Method 2: Manual Steps for Databricks Connect to Oracle Database
Here are the two steps involved in Databricks Connect to Oracle Database manually:
Step 1: Oracle to CSV Export
For this step, you’ll be leveraging the Oracle SQL Developer.
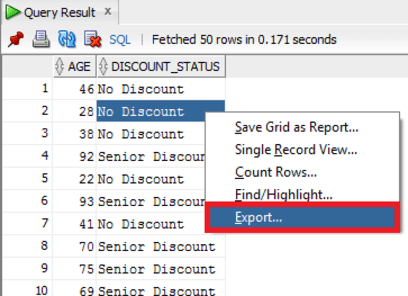
- First, connect to the database and table you wish to export.
- Next, you can open the context menu by right-clicking on the table. Select Export to start the integrated Export Wizard.
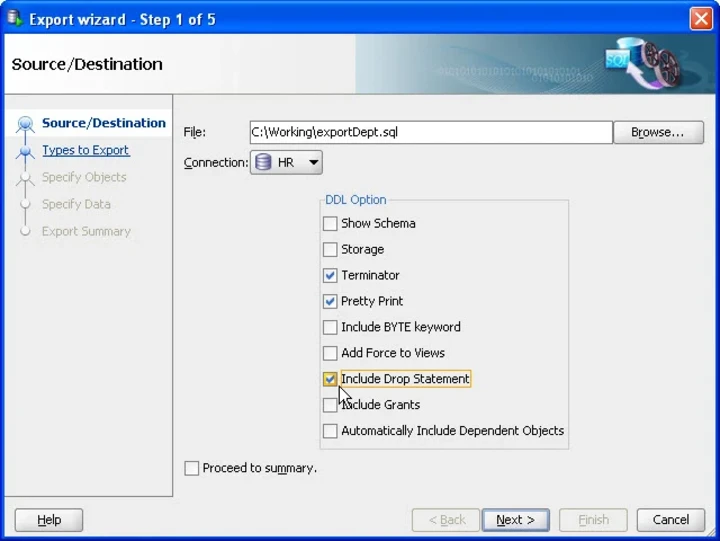
- Configure the DDL options. Check Include Drop Statement, for example. Select Next. Then, change the format to CSV and set the path for the exported file. Click on Next to proceed to the next step.
- In this step, you can select what Object Types to export. We will take the default for all object types. Click Next.
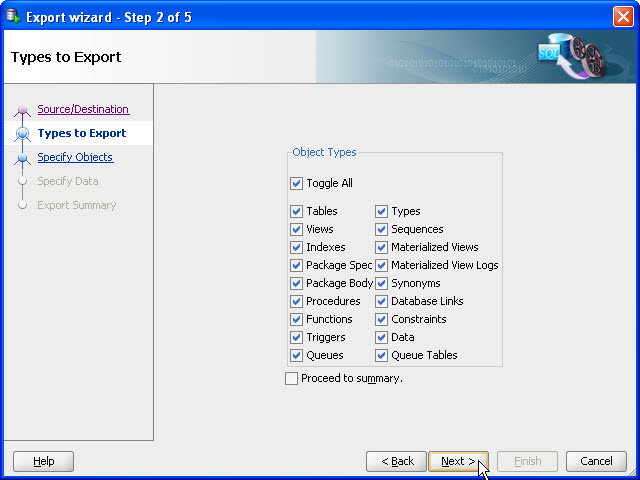
- The following screen lets you specify the columns you wish to export. (SELECT *… By default). Instead of querying all objects by immediately selecting Go, you can enter a restriction criteria. Enter D% and then click Go.
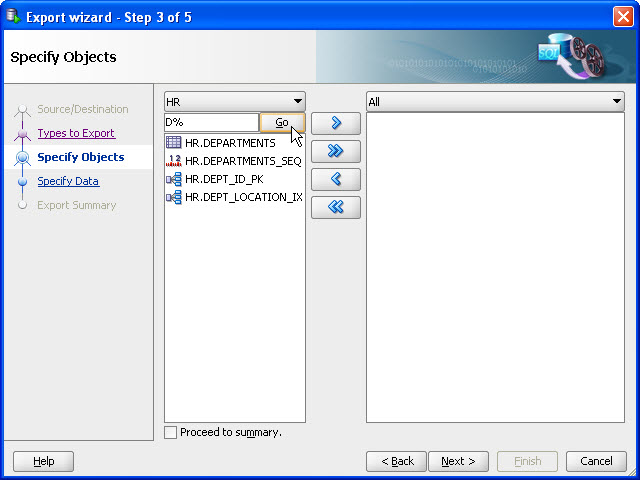
The list now displays tables that start with “D”.
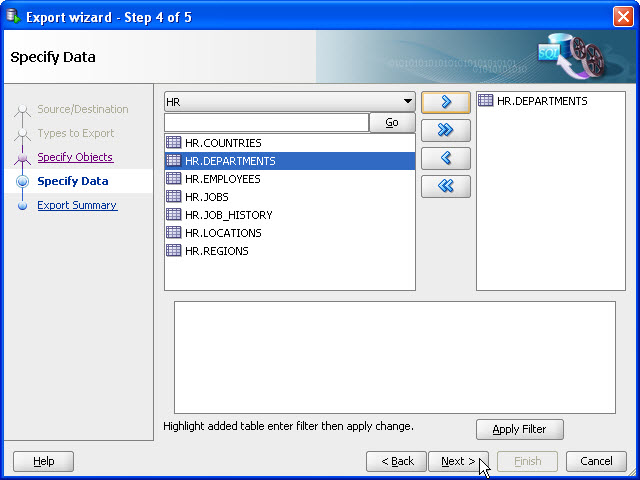
- In this step, you can specify the data that gets exported. Click Go, and a list of tables will appear. Shuttle Departments to the right-hand panel. Click Next. You can leverage the Edit button to change the settings, or you can proceed by clicking Next.
- Next, you’ll get a summary of the export process. You need to check if your settings are valid and complete the export by clicking Finish.
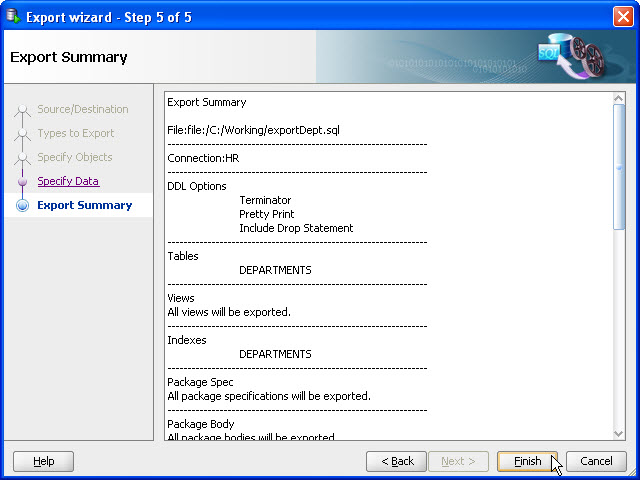
Step 2: Moving CSV Data to Databricks
- There are two ways to move CSV data to Databricks: by using the User Interface or by uploading the data to a table. To import the CSV file using the UI, you first need to click on the Settings icon in the lower-left corner of the Workspace UI and choose the option Admin Console. Next, click on the Workspace Settings tab and scroll to the Advanced section. You need to turn on the Upload Data using the UI toggle and click on Confirm to proceed with Databricks Read CSV.
- Now that you have uploaded data to the table, you can execute the following steps to modify and read the data to migrate CSV data to Databricks.
- Choose a cluster to preview the table and click on the Preview Table button to migrate CSV data to Databricks.
- Now that you’ve configured all the settings, you can click on the Create Table button. To read the data, you simply need to navigate to the Data Section and pick the Cluster where you have uploaded the file. With this, you have successfully moved CSV data into Databricks, also bringing an end to the Databricks Connect to Oracle database process.

You can also read about:
- Migrate AWS RDS Oracle to Databricks
- Set up CDC with Oracle and Debezium
- Oracle GoldenGate real-time replication
- Top Oracle replication tools & pricing
Conclusion
This blog talks about the different methods you can follow to set up Databricks Connect to Oracle database seamlessly. It also covers the salient features of Databricks and Oracle along with the importance of connecting Oracle to Databricks for your Data Pipeline.
Extracting complex data from a diverse set of data sources can be challenging, and this is where Hevo saves the day! Hevo offers a faster way to move data from 100+ Data Sources like Oracle or SaaS applications into your Data Warehouses such as Databricks to be visualized in a BI tool of your choice. Hevo is fully automated and hence does not require you to code.
FAQ on Databricks connect to Oracle
Can we connect Databricks to an Oracle Database?
Yes, you can connect Databricks to an Oracle Database using JDBC.
How do I connect to a database from Databricks?
Use the spark.read.format("jdbc") method, specifying the JDBC URL, driver, and connection properties.
Can spark connect to Oracle Database?
Yes, Apache Spark can connect to Oracle Database via JDBC.
Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



