

Large companies and organizations have started to move most of their data into Non-Relational Databases. They are developed to store hundreds of Petabytes of data and run millions of queries per second. MongoDB is a highly popular and widely used open-source Database, used by developers all over the world. However, it becomes challenging to access and query the Databases with increasing volumes of data. This is where Hibernate MongoDB comes in.
MongoDB is a NoSQL Database that supports a flexible schema approach and is capable of storing large data sets efficiently. NoSQL Databases allow large quantities of unstructured and semi-structured data to be stored and managed. Hibernate sits between Java Applications and the Database layer, and it maps variables in Java classes to Database fields and columns in tables. This article will introduce you to Hibernate and will help you work with Hibernate MongoDB.
Table of Contents
What is Hibernate?

Hibernate is an open-source Object-Relational Mapping (ORM) framework to map object-oriented class models to Relational Databases for Java and other applications. Hibernate sits between Java Applications and the Database layer, it maps variables in Java classes to Database fields/columns in tables. It also maps Java data types to SQL data types and relieves the Developer from most common data persistence-related programming tasks.
Prior to Hibernate, Developers had to write a lot of boilerplate code for Database access, often repeating those programming patterns again and again, across many projects. The primary role of Hibernate is to separate the data access layer from the rest of the application logic. It takes care of your Database queries and update statements on its own, and works well with most RDBMSs.
How does Hibernate work with Relational Databases?
Traditionally, Hibernate maps Java objects, more specifically properties/fields in a Java object to columns in a Database table. For example, let’s consider a hypothetical case where an employee of a company could have multiple addresses.
In Relation Databases, you could model this by having an Employee table and an Address table, where multiple entries in the Address table could map to a single employee record in the Employee table.
Table employee {
id integer(10),
name varchar(100),
designation varchar(50),
department ......
}
Table address {
id integer(10),
addressline1 varchar(50),
addressline2 varchar(50),
city varchar(30),
state ......
}
Table employee_address {
employee_id integer(10),
address_id integer(10)
}This relationship could be represented in your Java class with something similar to:
@OneToMany(cascade=CascadeType.ALL)
@JoinTable(name="employee_address", joinColumns={@JoinColumn(name="employee_id ", referencedColumnName="id")}
, inverseJoinColumns={@JoinColumn(name="address_id", referencedColumnName="id")})
private Set<AddressEntity> addresses;Now making an edit to an address will map your updated Java class variables/properties to columns in the Address table in the underlying Database.
rusted by 2000+ customers across 40+ countries, Hevo elevates your data migration game with its no-code platform. Ensure seamless data migration using features like:
- Seamlessly pull data from HubSpot and over 150+ other sources with ease.
- Utilize drag-and-drop and custom Python script features to transform your data.
- Efficiently migrate data to a data warehouse, ensuring it’s ready for insightful analysis in Tableau.
Experience the simplicity of data integration with Hevo and see how Hevo helped fuel Pelago’s drive for accurate analytics and unified data.
Get Started with Hevo for FreeHow does MongoDB work?

MongoDB is an open-source, cross-platform, and NoSQL Database Management System. Developed in 2009 by MongoDB Inc, MongoDB uses the document-oriented Database Model to group data into documents and collections rather than tables.
MongoDB stores and retrieves data as a key-value pair but the value part is stored as a document in JSON/XML format. This type of Database is also called a Document Store. While working with such a Database, Developers typically write code that embeds/understands the internal structure of the document’s fields and values.
Document Store Database offers more difficult queries as they understand the “value/document” in a key-value pair. For example, in MongoDB, you would store the same information as:
{
id: 1
name: Mary
Addresses: [
{
addressline1:10, Eagle street
addressline2: Sunset Boulevard
city:Newtown
zip: ZipABC
},
{
addressline1:205, Mayfair apts.
addressline2: Hurlington road
city:Newtown
zip: ZipXYZ
}
]
} Your MongoDB Database has nested fields that can go to any depth, as compared to singular data type (and values) in columns of a Relational Table.
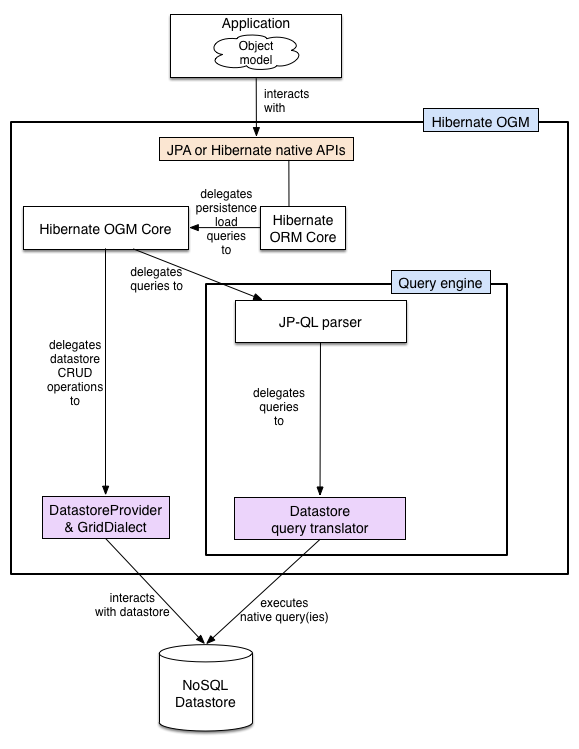
Now, going by traditional methods, you cannot use Hibernate MongoDB to map Java fields to a document (counterpart of a Relational Row/Record) in your MongoDB Database. To solve this problem, Hibernate provides an Object/Grid Mapper (OGM) implementation, that reuses its Object Life Cycle Management and (de)hydration engine but persists entities in a NoSQL Database instead.
OGM also provides the facility to query the data via native language queries of your specific NoSQL Database, as well as Java Persistence Query Language (JPQL). Except for column-based NoSQL Databases like BigQuery, OGM supports Documents/Graph/Key-Value based NoSQL Stores.
This project is mature enough to be used on production systems. For MongoDB, OGM has support for polymorphic entities, embeddable objects, associations & collections, etc. Also, it supports full-text searches, transactional support, and text analysis within MongoDB.
Working with Hibernate MongoDB
This part will take you through various aspects of Hibernate MongoDB that you need to be familiar with to get working.
- How to use Hibernate OGM with MongoDB?
- Properties of MongoDB for the persistence.xml File
- Dynamics of using OGM with an underlying MongoDB Database
- Implementing advanced configuration for MongoDB
How to use Hibernate OGM with MongoDB?
To get started with Hibernate MongoDB, you first need to build the OGM from Source via GitBug.
- You could clone the GitHub repo:
git clone https://github.com/hibernate/hibernate-ogm
cd hibernate-ogm- OR use Maven:
mvn clean install -DskipDocs=true -s settings-example.xml[If you want to build the documentation as well, don’t use the skipDocs switch]
To include OGM in your Hibernate MongoDB project, just include one more dependency in your list of dependencies.
<dependencies>
<!-- 1. Hibernate OGM Infinispan module; pulls in the OGM core module -->
<dependency>
<groupId>org.hibernate.ogm</groupId>
<artifactId>hibernate-ogm-infinispan-embedded</artifactId>
</dependency>
<!-- 2. Optional, needed to run JPQL queries only -->
<dependency>
<groupId>org.hibernate.search</groupId>
<artifactId>hibernate-search-orm</artifactId>
</dependency>
.........
........
<dependencies>Next, to define the persistence unit, create a META-INF/persistence.xml file.
<?xml version="1.0"?>
<persistence xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd"
version="2.0">
<persistence-unit name="ogm-jpa-hevo-tutorial" transaction-type="JTA">
<!-- Use the Hibernate OGM provider: configuration will be transparent -->
<provider>org.hibernate.ogm.jpa.HibernateOgmPersistence</provider>
<properties>
<!-- Here you will pick which NoSQL technology to use, and configure it;
in this example we use mongoDB. -->
<property name="hibernate.ogm.datastore.provider" value="MONGODB"/>
<!-- Define MongoDB access parameters here. -->
<property name="hibernate.ogm.datastore.database" value="empaddress"/>
<property name="hibernate.ogm.datastore.host" value="127.0.0.1"/>
<property name="hibernate.ogm.datastore.port" value="59541"/>
<property name="hibernate.ogm.datastore.username" value="admin"/>
<property name="hibernate.ogm.datastore.password" value="MyAdminPassword"/>
</properties>
</persistence-unit>
</persistence>Properties of MongoDB for the persistence.xml File
- hibernate.ogm.mongodb.connection_timeout: Defines the timeout used by the driver in milliseconds. The default value is 5000.
- hibernate.ogm.mongodb.associations.store: Defines the way OGM stores association information. There are 3 strategies to store association information.
- GLOBAL_COLLECTION stores the association information in a unique MongoDB Collection for all associations.
- COLLECTION stores the association information in a dedicated MongoDB Collection per association.
- IN_ENTITY stores association information from within the entity. IN_ENTITY is the default strategy to store association information.
- hibernate.ogm.mongodb.writeconcern: Possible values are ACKNOWLEDGED, UNACKNOWLEDGED, NONE, NORMAL, SAFE, MAJORITY, ERRORS_IGNORED, JOURNALED, JOURNAL_SAFE, FSYNCED, FSYNC_SAFE, REPLICAS_SAFE. The default value is ACKNOWLEDGED.
Dynamics of using OGM with an underlying MongoDB Database
Coming back to our original Employee <—> Address model, recall that MongoDB would store it as a nested collection. So, within our Java application, OGM will allow us to model it as:
@Entity
public class employee {
@id
id integer(10),
name varchar(100),
designation varchar(50),
department ......
@ElementCollection
private Set<AddressEntity> addresses;
....
}
@Embeddable
public class AddressEntity{
@id
id integer(10),
addressline1 varchar(50),
addressline2 varchar(50),
city varchar(30),
//getters, setters ...
}In the above example, the GLOBAL_COLLECTION strategy/association is created. Here, Hibernate MongoDB OGM creates a single collection, namely the set addresses, in which it will store all navigation information for all Employee <–> Address associations. So, using this strategy, you can get pointers/references to all addresses that belong to a single employee.
Now OGM will take care of the internal workings of mapping your nested Java data types to documents in your MongoDB Database.
If you use the “@id” annotation as above, Hibernate OGM will convert the @Id property into an _id document field and save the corresponding/related document with the same “id“. Hence, your IDs in the Java application will have a one-to-one match with their corresponding documents stored in MongoDB with the same IDs.
There is another way of storing and representing this association, where only Address Entity IDs will be stored in the Employee object (not the whole address).
@Entity
public class employee {
@id
id integer(10),
name varchar(100),
@ManyToMany
public Set<AddressEntity> addresses;
.....
This is called the IN_ENTITY (default) association.
Here, your internal MongoDb JSON object will be something like
{
"_id" : "empID0001",
"addresses" : [
{ "address_id" : "add001" },
{ "address_id" : "add006" },
....
]
}Still, there is one more strategy of storing your objects internally, which is called COLLECTION. This is the closest to the Relational Model we discussed at the start of this post, where we store the relationship data in a third table, Employee_address.
Here, Hibernate MongoDB OGM will create a MongoDB Collection for every Address-Employee association. So, if Employee A has 2 addresses, addressentity1 and addressentity1, 2 collections will be created.
Here, your internal MongoDB JSON object will be something like:
{
"_id" : { "employee_id" : "empID0001" },
"rows" : [
{ "address_id" : "add001" }
]
}
{
"_id" : { "employee_id" : "empID0001" },
"rows" : [
{ "address_id" : "add006" }
]
}Hibernate MongoDB OGM will maintain a set of secondary indexes, which you can use to query your data in MongoDB. These indexes can be stored in the Lucene Directory of Infinispan. Infinispan is an open-source, in-memory, key/value data store. OGM will return managed entities and there is a proper integration at the JPA/Hibernate API level.
Implementing Advanced Configuration for MongoDB
Hibernate MongoDB OGM provides the MongoDBConfiguration class and the InfinispanConfiguration class, inside org.hibernate.ogm.options package, to fine-tune configuration. This configuration is read when OGM starts to load your Datastore or operates on it.
Conclusion
NoSQL Databases like MongoDB have emerged tremendously in the last few years. MongoDB stores data into collections of self-describing JSON documents. MongoDB has become widely accepted as a leading Database owing to its dynamic schema, high scalability, and faster access.
This post discussed how to work with Hibernate MongoDB using OGM, and some internal details of Hibernate MongoDB OGM. Simply put, Hibernate make it easy to access and query MongoDB Databases. However, to get a complete overview of your business performance, it is important to consolidate data from MongoDB and other Data Sources into a Cloud Data Warehouse or a destination of your choice for further Business Analytics. This is where Hevo comes in.
Hevo Data with its strong integration with 150+ Sources & BI tools such as MongoDB, allows you to not only export data from sources & load data in the destinations, but also transform & enrich your data, & make it analysis-ready so that you can focus only on your key business needs and perform insightful analysis using BI tools.
FAQ on Hibernate MongoDB
Can I use MongoDB with Hibernate?
Yes, you can use MongoDB with Hibernate via the Hibernate OGM (Object/Grid Mapper) project. Hibernate OGM allows you to use Hibernate’s familiar API to interact with MongoDB and other NoSQL databases.
What database to use with Hibernate?
Hibernate is typically used with relational databases like MySQL, PostgreSQL, Oracle, and SQL Server. Hibernate OGM extends this functionality to NoSQL databases like MongoDB.
Where is MongoDB not suitable?
MongoDB is not suitable for applications requiring complex transactions and joins, strong ACID compliance, and traditional relational data modeling. For these needs, use a relational database like PostgreSQL or MySQL.
Can you use MongoDB for caching?
Yes, MongoDB can be used for caching due to its high read and write throughput. However, specialized caching solutions like Redis or Memcached are often more efficient for this purpose.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




