




Organizations use Google BigQuery Data Warehouse for analytics and querying large, complex datasets. BigQuery is based on Dremel architecture that divides the query execution into slots. When multiple users are querying data simultaneously, these slots get allocated to users as per their needs. As a result, the Dremel system maintains fairness for concurrent queries.
With BigQuery, users can perform SQL queries on data and visualize it to gain insights into big data. BigQuery can also connect with different SQL and Business intelligence (BI) tools for real-time analytics. But to use these tools, you have to use BigQuery JDBC and ODBC connectors that give you access to BigQuery’s Standard SQL.
In this tutorial, you will learn to establish a connection between Google BigQuery and JDBC drivers using the Progress DataDirect connector and DbSchema tool.
Table of Contents
What Is Google BigQuery?
Developed in 2010, BigQuery is a fully managed Data Warehouse that helps users organize and analyze their data with features like Machine Learning, Geospatial Analysis, and Business Intelligence. It follows a serverless architecture that allows users to use SQL queries to get answers from their data.
BigQuery enables developers and data scientists to use client libraries with programming languages like Python, Java, JavaScript, and Go. Users can also use BigQuery’s REST API to transform and manage their data effectively.
Discover more about Google BigQuery here- BigQuery Tutorial: A Comprehensive Guide. If you would like to know more about the best Data Visualization Tools on Google BigQuery, follow this guide – Best Google BigQuery Data Visualization Tools.
Key Features of Google BigQuery
1. Machine Learning and Predictive Modeling
With BigQuery ML, users can create and execute Machine Learning Models by using standard SQL queries. Machine Learning Models like Linear Regression, Binary Logistic Regression, Multi-class Regression, K-means Clustering, and more are supported with BigQuery. Such models allow anyone to build their own Machine Learning Models on structured or semi-structured data using SQL inside BigQuery.
More on Machine Learning and Predictive Modeling here- Understanding Google BigQuery ML: Simplified 101.
2. BigQuery BI Engine
BigQuery consists of the BI engine, which helps users process large datasets with sub-second query response time and high concurrency. The BI Engine can integrate with BI tools like Google Data Studio, Tableau, Power BI, and more to speed up your data analysis. It can also work with tools like BigQuery SQL, API libraries, JDBC drivers, and more.
3. Geospatial Analysis
Users can analyze and visualize geospatial data in BigQuery using geography data types and standard SQL geography functions.
4. BigQuery Omni
BigQuery Omni enables users to perform analysis on data stored in AWS S3 or Azure blob storage. Many companies store data on several clouds and getting insights into such data becomes difficult. As a result, you can copy or move all data to a central location to obtain insights. But, moving or copying data may require more time. This is where BigQuery Omni eliminates the need for moving data by bringing the BI engine to your data and performing analytics.
More on BigQuery Omni here- Understanding Google BigQuery Omni: Multi-Cloud Analytics Simplified 101.
Hevo is a fully managed, no-code data pipeline platform that effortlessly integrates data from more than 150 sources into a data warehouse such as BigQuery. With its minimal learning curve, Hevo can be set up in just a few minutes, allowing users to load data without having to compromise performance. Its features include:
- Connectors: Hevo supports 150+ integrations to SaaS platforms, files, Databases, analytics, and BI tools. It supports various destinations, including Google BigQuery, Amazon Redshift, and Snowflake.
- Transformations: A simple Python-based drag-and-drop data transformation technique that allows you to transform your data for analysis.
- Schema Management: Hevo eliminates the tedious task of schema management. It automatically detects the schema of incoming data and maps it to the destination schema.
- Real-Time Data Transfer: Hevo provides real-time data migration, so you can always have analysis-ready data.
- 24/7 Live Support: The Hevo team is available 24/7 to provide exceptional support through chat, email, and support calls.
Try Hevo today to experience seamless data transformation and migration.
Get Started with Hevo for FreeHow to Set Up BigQuery JDBC Connection?
Google uses Magnitude Simba to provide BigQuery JDBC and ODBC drivers that increase the power of BigQuery’s Standard SQL. Magnitude Simba provides a complete data connectivity solution that delivers data access to and from applications, databases, virtual databases, or any other data sources.
Using Magnitude, users can not only access all their data sources easily but also build scalable data-driven solutions. These solutions consist of Simba Gateway Connectivity-as-a-Service, Simba SDK, Standalone Connectors, and more.
Setting Up BigQuery JDBC Connection Using Progress DataDirect’s JDBC Connector
Connecting BigQuery With JDBC Connector
Follow the steps below for BigQuery JDBC connection using Progress DataDirect’s JDBC connector.
Step 1: Download the Progress DataDirect JDBC Connector for Google BigQuery by visiting the given website.
Step 2.a (For Windows users): For the Windows downloaded version, extract the downloaded file using the below command.
PROGRESS_DATADIRECT_JDBC_GOOGLE_BIGQUERY_WIN.zipRun the PROGRESS_DATADIRECT_JDBC_INSTALL.exe file for installing the JDBC driver. To complete the connector installation, follow the instructions as provided by the installer.
Step 2.b (For Linux users): For the Linux download version, extract the downloaded file using the below command.
PROGRESS_DATADIRECT_JDBC_GOOGLE_BIGQUERY_ALL.zipYou can use the below command in the terminal to install the JDBC driver.
java -jar PROGRESS_DATADIRECT_JDBC_INSTALL.jarThen, follow the instructions on the terminal to install the JDBC connector.
Authenticating JDBC Driver for Google BigQuery
Progress DataDirect’s JDBC connector for Google BigQuery consists of two types of authentication:
- Service Account Authentication
- OAuth 2.0 Authentication
In this tutorial, you will be using the Service Account Authentication. Follow the steps below to authenticate BigQuery JDBC driver for Google BigQuery:
Step 1: Log in to your Google Cloud Console.
Step 2: Open the menu on the left and click on IAM & admin. After that, click on the Services Account as shown below.
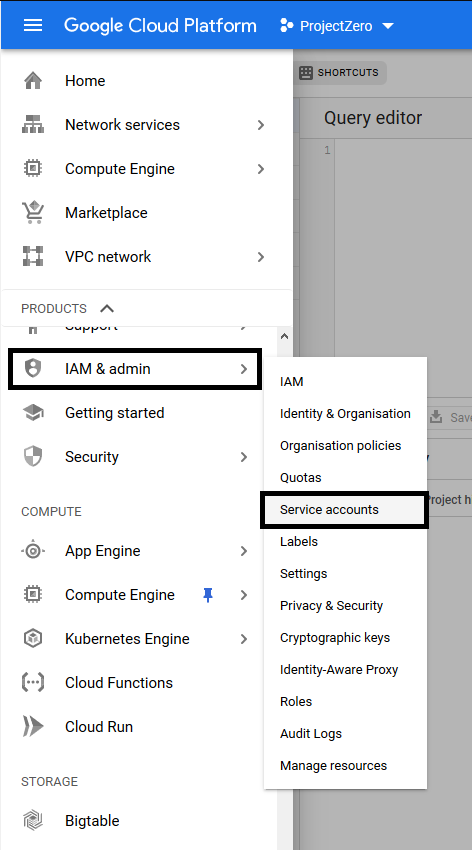
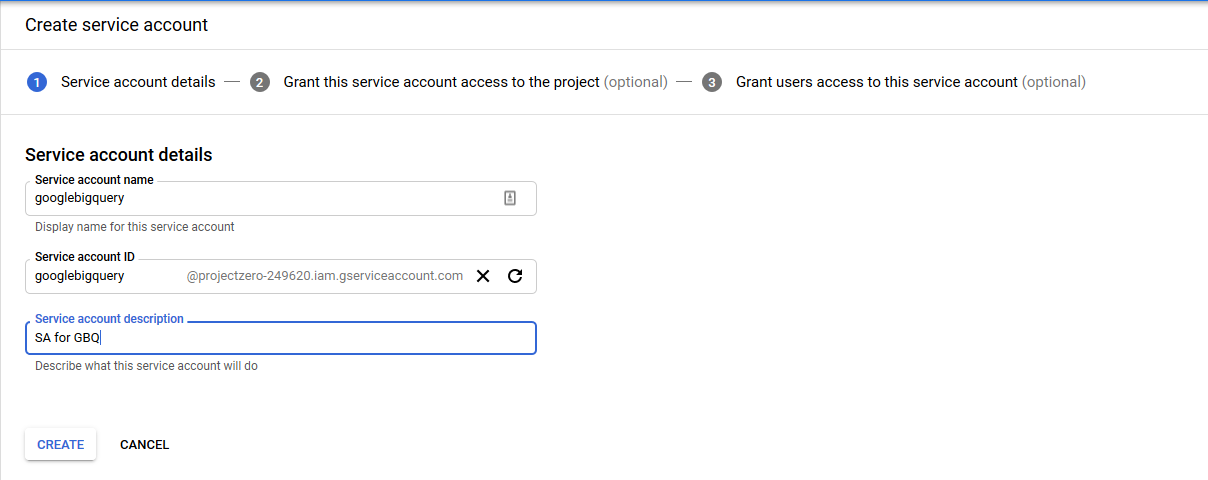
Step 3: On the Service Accounts page, click on the Create Service Account button. There, you will find a form to create a new Service Account. On this page, you need to enter the Service Account Name, Service Account ID, and Service Account Description, as shown below.
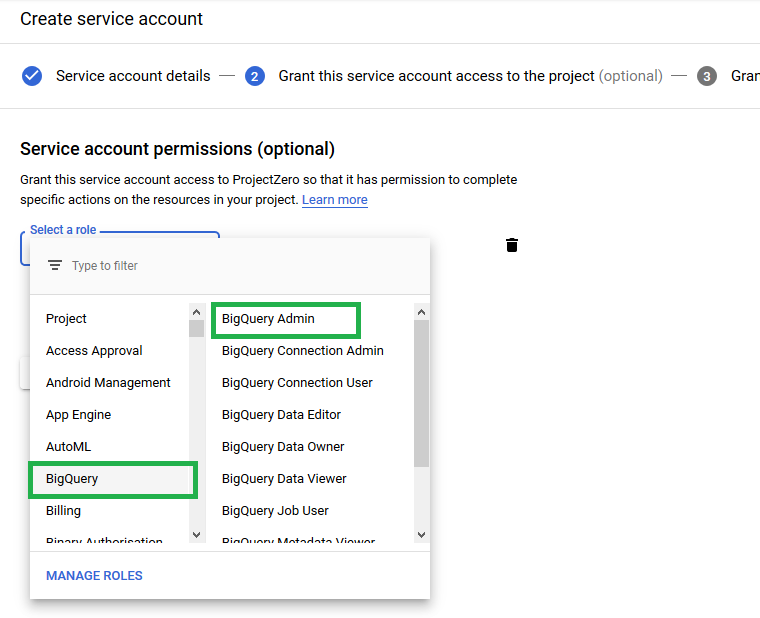
Step 4: After filling in the details, click on the Create button. There is an option of providing Service Account permissions. Just below that, there is a drop-down menu from which you have to select BigQuery → BigQuery Admin, as shown below.
Step 5: Next, click on the Continue tab. You will find an option to create a Key on the next screen. Click on Create Key.
It will open a menu on the right side asking you to choose between JSON or .p12 key files. You can select any of the two files. Since you are using BigQuery JSON drivers, you will select the JSON file as shown below.
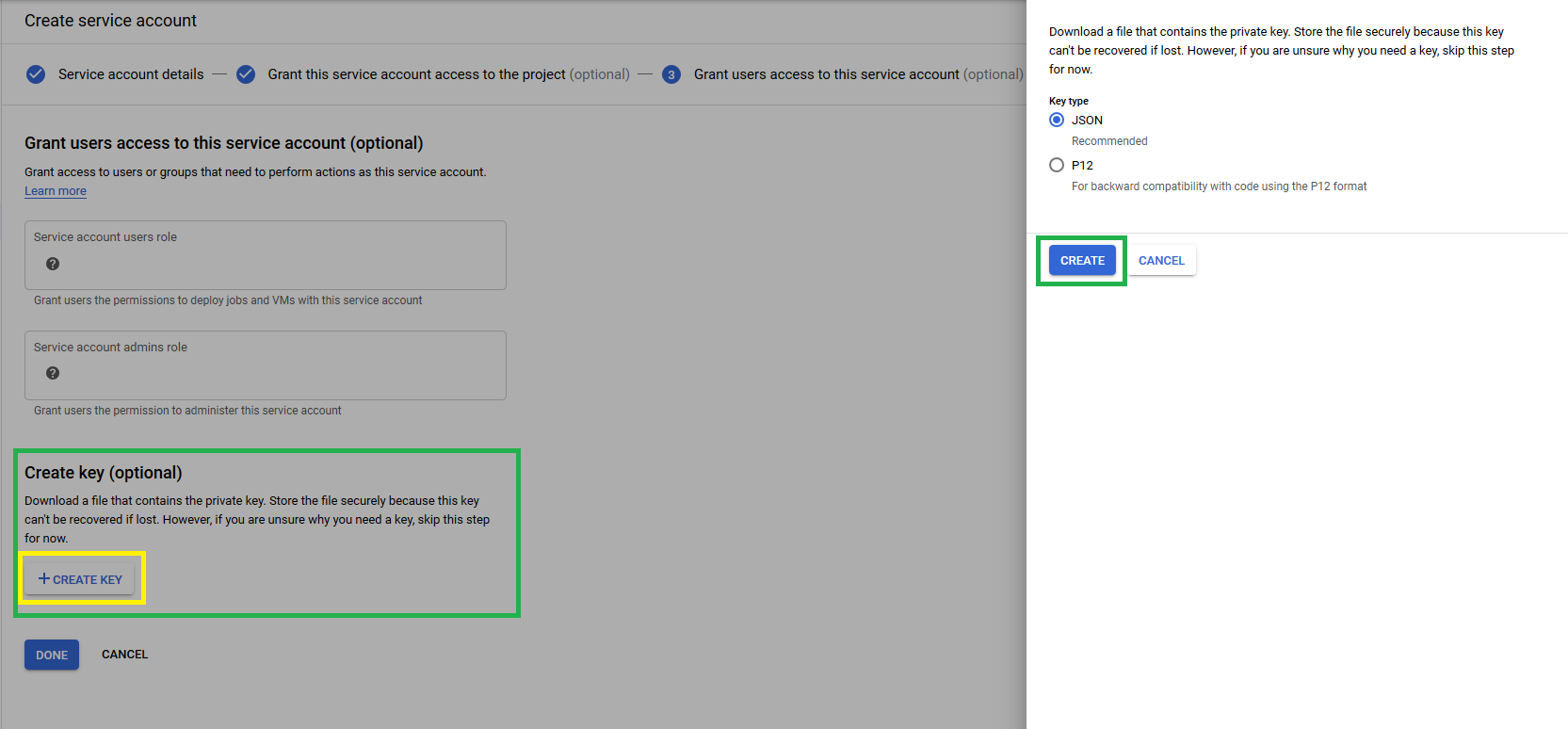
Step 6: After choosing the JSON file, it will start downloading the JSON file.
Query the Google BigQuery Data
For querying data using Progress DataDirect’s BigQuery JDBC Connector with Google BigQuery, you can use a simple query tool called Dbeaver.
To do that, you have to register the BigQuery JDBC connector with Dbeaver.
Step 1: Go to Database and click on DriverManager. It will open the below window.
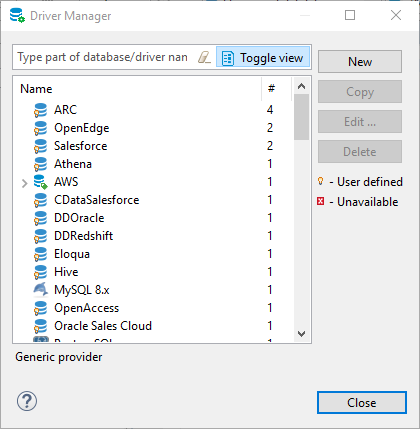
Step 2: Click on New Tab. It will open a form for registering the driver. Fill it with the below details.
Name: <Any name>
Class Name: com.ddtek.jdbc.googlebigquery.GoogleBigQueryDriverStep 3: Click on Add File and navigate to the location of googlebigquery.jar as mentioned below.
C:Program FilesProgressDataDirectJDBC_60googlebigquery.jarStep 4: After providing the above details, the registration form will look as follows.
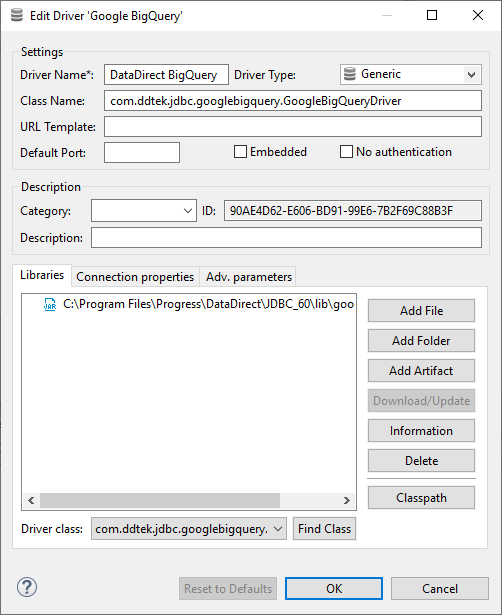
Step 5: Click on OK to register the BigQuery JDBC connector.
Step 6: You have to create a connection with Google BigQuery. Go to Database and click on New Connection. Select the BigQuery JDBC Connector that you just created.
Step 7: Use this URL in the JDBC URL.
jdbc:datadirect:googlebigquery:AuthenticationMethod=serviceaccount;Project=<yourprojectname-12345>;Dataset=<your dataset name>;ServiceAccountEmail=<email@yourprojectname-12345.iam.gserviceaccount.com;ServiceAccountPrivateKey=/path-to/json-or-p12-fileIn the above URL,
- Project: It is the Project ID that you get in your Google Console.
- Dataset: It is the name of the dataset you want to connect.
- ServiceAccountEmail: It is the Service Account ID, which can be found in IAM->Service Accounts.
- ServiceAccountPrivateKey: It is the path to JSON or .p12 file.
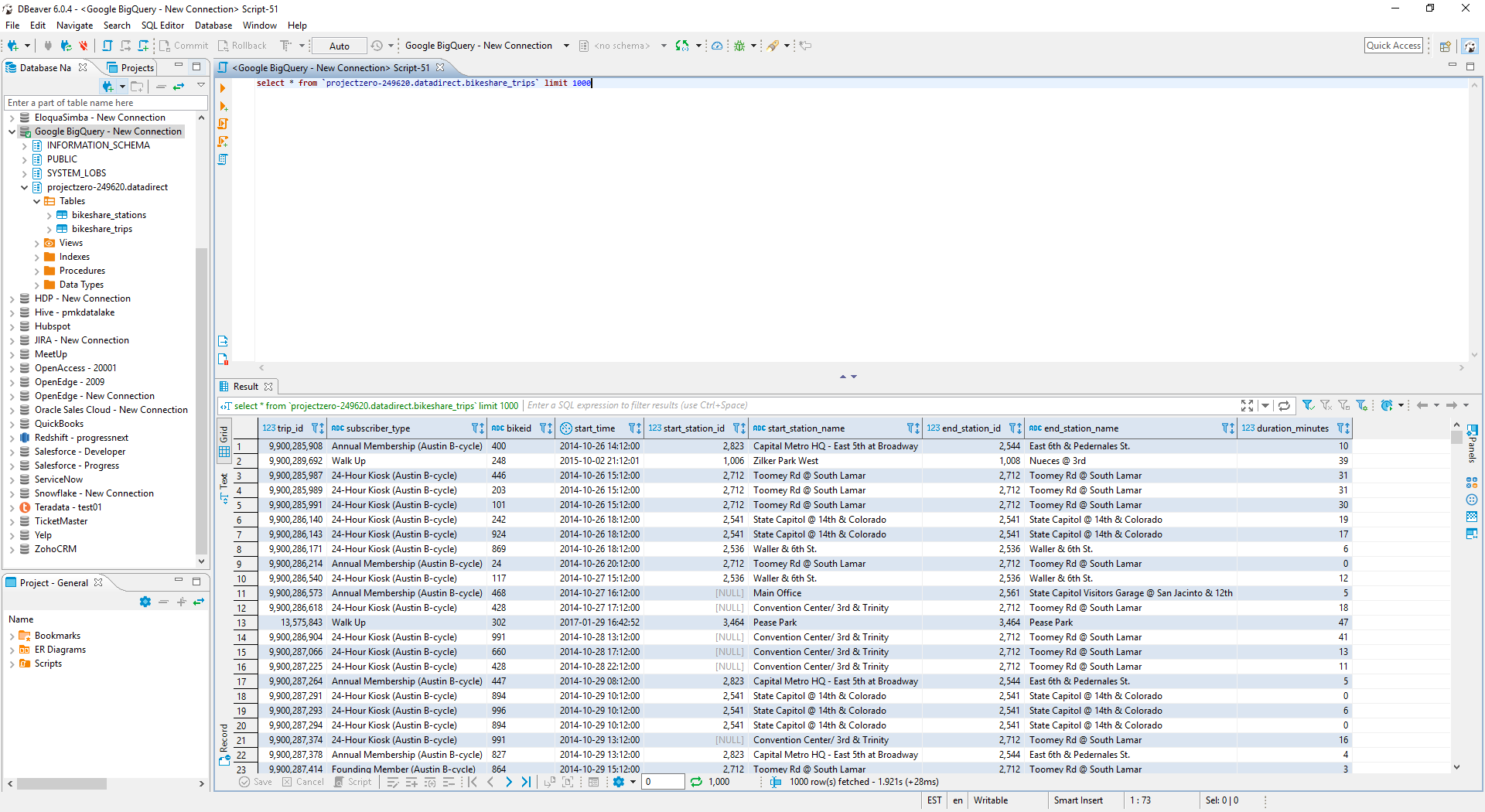
Step 8: By clicking on the Test Connect tab, you are ready to run your SQL queries on BigQuery, as shown below.
Connecting Google BigQuery JDBC Driver With DbSchema
JDBC drivers are Java library files used by applications to connect with the databases. They use specific URLs with a particular format that contains information about the host and where the database is running, the port, username, database name, and more. The URL format is specific to each JDBC driver.
DbSchema is a universal Database Designer Tool for immediate schema management, sharing the schema in teams, and deploying schema for different databases. It can support all the commonly used databases, including MySQL, SQL, PostgreSQL, MongoDB, Redshift, and more.
Follow the steps below for connecting the Google BigQuery JDBC driver with DbSchema.
Step 1: Download the Google BigQuery JDBC driver from the link provided.
Step 2: Download the free version of DbSchema.
Step 3: Select the alias for your database connection. As shown below, the alias’ name will be the same for the specific database connection.
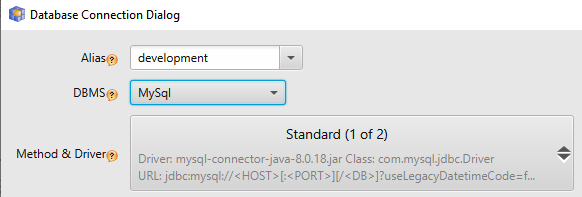
Step 4: Select “GoogleBigQuery” from the list of DBMS.
Step 5: The driver for the Google BigQuery will be downloaded automatically in the folders below.
C:UsersYourUser.DbSchemadriversGoogleBigQuery (for Windows)or
/Users/YourUser/.DbSchema/drivers/GoogleBigQuery (for Linux and MacOS)Each database can have several JDBC connections and authentication methods. You can switch to a different method from the drop-down menu.
Step 6: There are two tabs for connecting with the JDBC driver, as shown below. The Compose URL tab will ask for hostname, port name, and username details.
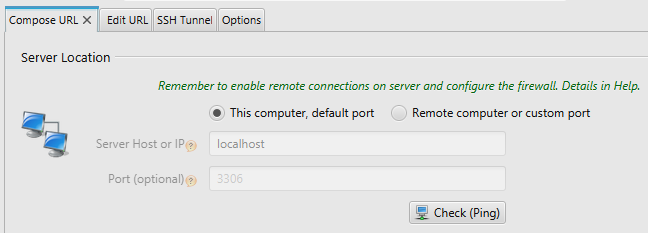
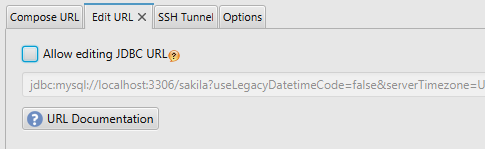
The second tab is the Edit URL tab. It will allow you to directly enter the JDBC URL. You can use the first tab to connect and the second tab to see the created URL, as shown below.
If the connection is successful, you can see your first DbSchema project and its diagrams as follows.
This brings us to the end of this BigQuery JDBC connection tutorial. We hope that the explained concepts and steps guided you through your first BigQuery JDBC connection with ease and clarity.

More Recommended
- How to Issue a BigQuery Dry Run? 2 Easy Methods
- Amazon Redshift to Google BigQuery Migration: 2 Easy Methods
- Configuring Google Apps Script BigQuery Connection Simplified 101: Critical Aspects
- BigQuery Restore Deleted Tables In 2 Easy Steps
Conclusion
In this tutorial, you have learned how to connect Google BigQuery with JDBC using Progress DataDirect’s JDBC connector and DbSchema. With DbSchema, you can directly download the JDBC connector for Google BigQuery and create DbSchema projects from BigQuery data.
Progress DataDirect is a third-party connector integrating BigQuery JDBC data with the JDBC driver. Besides Progress DataDirect, there are many other third-party BigQuery JDBC connectors like CData, MicroStrategy, and more. You can use Magnitude Simba for connecting the JDBC driver with Google BigQuery.
With your Data Warehouse, Google BigQuery live and running, you’ll need to extract data from multiple platforms to carry out your analysis. However, integrating and analyzing your data from a diverse set of data sources can be challenging, and this is where Hevo Data comes into the picture.
Hevo Data, a No-code Data Pipeline provides you with a consistent and reliable solution to manage data transfer between a variety of sources and a wide variety of desired destinations such as Google BigQuery, with a few clicks. Connect with us today to improve your data management experience and achieve more with your data.
FAQs
Does BigQuery support JDBC?
Yes, BigQuery supports JDBC through the BigQuery JDBC driver, allowing applications to connect and interact with BigQuery.
What is JDBC in big data?
JDBC (Java Database Connectivity) in big data refers to a standard API that allows Java applications to interact with databases, including big data platforms like BigQuery, for querying and managing large datasets.
What is ODBC vs JDBC?
ODBC (Open Database Connectivity) and JDBC (Java Database Connectivity) are both APIs for database access. ODBC is language-independent and works with various programming languages, while JDBC is Java-specific.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



