



Data migration between different platforms is critical to consider when generating multiple organizational strategies. Amazon Redshift is a serverless, fully managed leading data warehouse in the market, and many organizations are migrating their legacy data to Redshift for better analytics.
In this blog, we will discuss the best Redshift ETL tools that you can use to load data into Redshift.
Table of Contents
Overview of Redshift

Amazon Redshift, offered by Amazon Web Services (AWS), is a cloud data warehousing service that helps corporations manage large amounts of data and produce valuable insights. Amazon Redshift provides you with a wide variety of features that can assist you meet the needs of your business requirements.
Some popular features include its parallel processing abilities, automated data compression to reduce storage space requirements, columnar storage that makes the data easy to query by only considering specific columns, and many more.
For companies moving data from, let’s say, SQL Server to Redshift, selecting the right ETL tools is essential to ensure efficient and reliable data transfer, especially for large datasets.
A fully managed No-code Data Pipeline platform like Hevo Data helps you integrate and load data from 150+ different sources (including 60+ free sources) to a Data Warehouse such as Redshift or Destination of your choice in real-time in an effortless manner.
Let’s see some unbeatable features of Hevo Data:
- Fully Managed: Hevo Data is a fully managed service and is straightforward to set up.
- Schema Management: Hevo Data automatically maps the source schema to perform analysis without worrying about the changing schema.
- Real-Time: Hevo Data works on the batch as well as real-time data transfer so that your data is analysis-ready always.
- Live Support: With 24/5 support, Hevo provides customer-centric solutions to the business use case.
8 Best Redshift ETL Tools
Let’s have a detailed look at these tools.
1. AWS Glue

AWS Glue is a fully managed and cost-effective serverless ETL (Extract, Transform, and Load) service on the cloud. It allows you to categorize your data, clean and enrich it, and move it from source systems to target systems.
AWS Glue uses a centralized metadata repository known as Glue Catalog, to generate the Scala or Python code to perform ETL and allows you to modify and add new transformations. It also does job monitoring, scheduling, metadata management, and retries.
Key Features of AWS Glue
- AWS Glue is a cloud-based ETL tool that uses Python as its base language for generating ETL code.
- It offers several useful pre-built transformations that can be plugged into existing ETL logic, and you can also create custom functions to integrate into the flow.
- AWS glue is mostly used for batch data, but in combination with other offerings of AWS like Lambda or Step, a near-real-time scenario can be achieved.
- You can use AWS Glue to perform effective ETL on the data without having to think about performance, scalability, and other parameters.
AWS Glue Price
AWS Glue has a pay-as-you-go pricing model. It charges an hourly rate, billed by the second. Check about AWS Glue pricing.
2. AWS Kinesis

Amazon Kinesis is a serverless Data Analytics service and is the best tool to analyze real-time data. With the use of pre-built templates and built-in operators, you can quickly build sophisticated real-time applications.
Key Features of AWS Kinesis
- It is a serverless framework, and hence you don’t need to set up any hardware or complex infrastructure for processing.
- AWS Kinesis can auto-scale based on the loads, and hence you need not worry about the performance and scaling of the infrastructure.
- It has a pay-as-you-go pricing model, and hence you only need to pay for the time you are using their services.
- AWS Kinesis has an interactive editor to build SQL queries using streaming data operations like sliding time-window averages. You can also view streaming results and errors using live data to debug or further refine your script interactively.
- AWS Kinesis Firehose uses the Redshift Copy command to move the streaming ETL data directly to the Redshift. Then you can use Redshift’s in-built SQL editor to perform Transformation on the data.
AWS Kinesis Pricing
Kinesis has a pay-as-you-go model and doesn’t have any upfront charges. You can find the details about the charges of AWS Kinesis.
3. AWS Data Pipeline

AWS Data Pipeline is a serverless web service that you can use to automate data extraction and Transformation by creating a data-driven workflow that will contain dependent tasks.
AWS Data Pipeline is different from AWS Glue as it allows more control on the job, and you can stitch the various AWS services into one to create an end-to-end pipeline.
Key Features of AWS Data Pipeline
- AWS Data Pipeline is an orchestration tool that creates data-driven workflows by combining various services/states of AWS.
- It allows you to choose from various AWS services and build custom pipelines and then scheduling the jobs.
- You can select EC2 Clusters for computation, S3 for storage, Lambda for event-based triggers, and then combine them to a single dependent workflow in AWS Data Pipeline.
- It allows you to run the job using MapReduce, Hive, Pig, Spark, or Spark SQL.
AWS Data Pipeline Pricing
AWS Data Pipeline has a pay-per-use model, and you have to pay for your pipeline based on how often your activities and preconditions are scheduled to run and where they run. For more information, see AWS Data Pipeline Pricing.
4. Hevo Data

Hevo Data, a No-code Data Pipeline, reliably replicates data from any data source with zero maintenance. You can get started with Hevo’s 14-day Free Trial and instantly move data from 150+ pre-built integrations comprising a wide range of SaaS apps and databases. What’s more – our 24X5 customer support will help you unblock any pipeline issues in real-time.
Key Features of Hevo Data
- Near Real-Time Replication: Get access to near real-time replication on All Plans. Near Real-time via pipeline prioritization for Database Sources. For SaaS Sources, near real-time replication depend on API call limits.
- In-built Transformations: Format your data on the fly with Hevo’s preload transformations using either the drag-and-drop interface or our nifty python interface. Generate analysis-ready data in your warehouse using Hevo’s Postload Transformation.
- Monitoring and Observability: Monitor pipeline health with intuitive dashboards that reveal every stat of ETL pipeline and data flow. Bring real-time visibility into your ETL with Alerts and Activity Logs.
- Reliability at Scale: With Hevo, you get a world-class fault-tolerant ETL architecture that scales with zero data loss and low latency.
Hevo’s Pricing
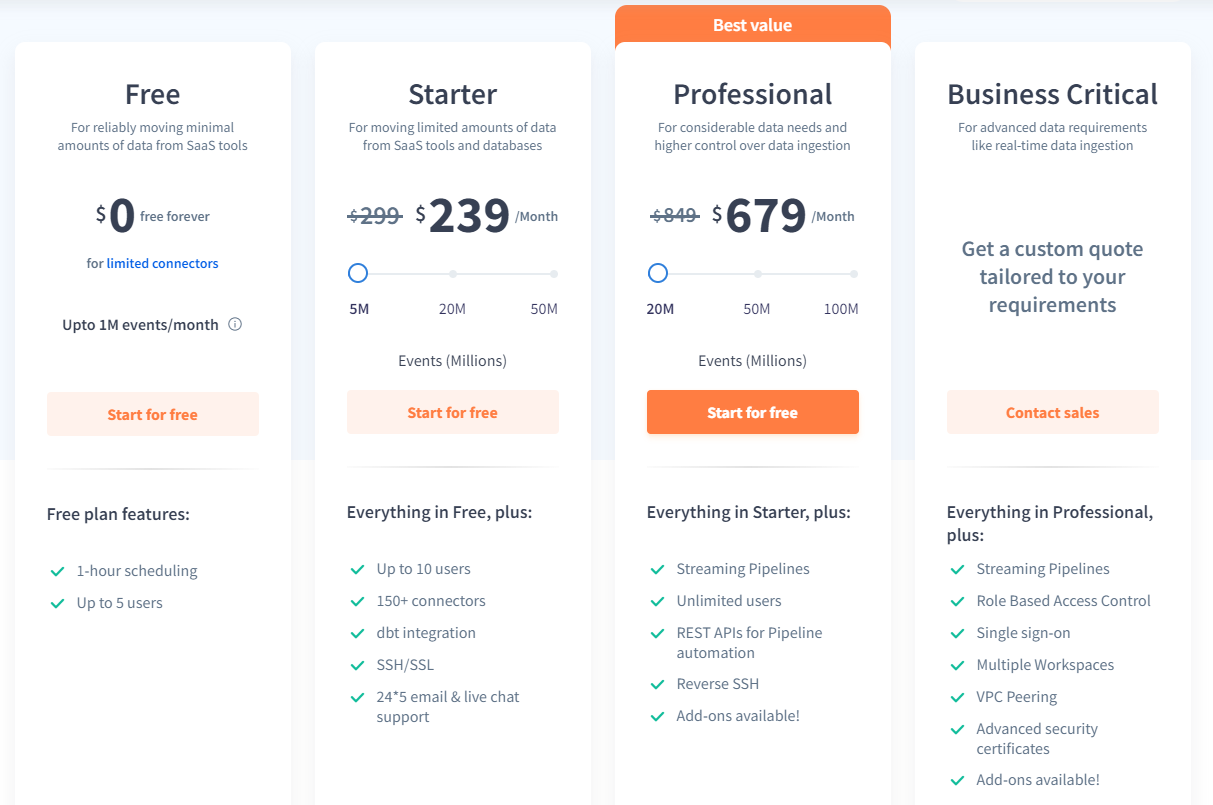
Explore Hevo’s pricing plans in detail.



5. Apache Spark

Apache Spark is an open-source lightning-fast in-memory computation framework that can be installed with the existing Hadoop ecosystem as well as standalone. Many distributions like Cloudera, Databricks, AWS have adopted Apache Spark in their framework for data computation.
Key Features of Apache Spark
- Apache Spark performs in-memory computations and is based on the fundamentals of Hadoop MapReduce. Due to its in-memory computation, it is 100x faster than Hadoop MapReduce.
- Apache Spark distributes the data across executors and processes them in parallel to provide excellent performance. It can handle large data volumes easily.
- Apache Spark can effectively connect with legacy databases using JDBC connectors to extract the data and transform them in memory and then load to the target.
- Apache Spark can use Redshift as a source or target to perform ETL by using the Redshift connector.
- Apache spark is completely functionally programmed, and hence the user needs to be compliant with programming languages.
- Apache Spark works on both ETL batch processing and real-time data.
Spark Pricing
Apache Spark is free to use, and you can explore it further by downloading It. However, distributions like Cloudera and Hortonworks charge for support, and you can get detailed pricing.
6. Talend

Talend is a popular tool to perform ETL on the data by using its pre-built drag and drop palette that contains pre-built transformations.
Key Features of Talend
- Talend has an open studio edition for beginners, which can be used without paying. The Enterprise version is known as Talend Cloud.
- Talend has multiple integrations like Data Integration, Big Data Integration, Data Preparation, etc.
- Talend has an Interactive space that allows Drag and Drop of various functions (called palette) which features the various ETL operations.
- Talend generates Java code at the backend when you build the Talend job. Hence it requires the users to have a basic understanding of programming languages.
- Talend has excellent connectivity to Redshift, and you can easily perform transformations in Talend space and then load the data into Redshift.
- Talend also provides API Services, Data Stewardship, Data Inventory, and B2B.
Talend Pricing
Talend’s base pack starts from $12000 a year and has multiple categories to choose from.
7. Informatica

Informatica is available as an on-premise and cloud infrastructure with hundreds of connectors to connect with leading tools to perform ETL on the data. Informatica provides codeless and optimized integration with databases, cloud data lakes, on-premise systems, and SaaS applications.
Key Features of Informatica
- Informatica has enhanced connectivity and hosts hundreds of connectors to connect with data warehouses, databases, and other systems.
- With the broad range of connectors, it has excellent support to data(structured data, unstructured data, and complex data), processing type(batch, real-time, near real-time).
- Informatica also supports Change Data Capture, advanced lookups, error handling, and partitioning of the data.
- Informatica has a data mapping designer that you can use to develop ETL workflows by using its in-built connectors and transformation boxes without having to write any piece of code.
- Informatica also offers bulk data load, data discovery, flow orchestration, data catalog, etc. to manage the lifecycle of your data.
- Informatica Cloud is a serverless offering where you can effectively analyze vast volumes of data without having any issue of scalability and performance.
- Informatica has excellent support for the leading cloud technologies viz. AWS, GCP, and Azure.
Pricing
Informatica provides a 30-day free trial to get you hands-on with their various offerings and has multiple pricing and packages that you can choose based on your needs.
8. Stitch

Stitch Data is a powerful ETL tool that is built for developers and it can easily connect with the data sources to extract the data and moves to analysis very quickly. Stitch sets up in minutes without any hassle and provides unlimited data volume during the trial period.
Key Features of Stitch
- Stitch provides orchestration features to create pipelines and provide data movement which allows users to have more control over the data.
- It automatically detects the defects and reports the error. If possible, it automatically fixes the errors and reports them by notification.
- Stitch provides excellent performance and scalability of the data volumes in any direction.
- Stitch has inbuilt Data Quality that helps you to profile, clean, and even mask the data before moving to the transformations.
- Stitch provides more than 900 connectors and components that help you to perform transformations, including a map, sort, aggregates, etc.
Pricing
Stitch comes with two pricing plans viz. Stitch Standard and Stitch Enterprise. Stitch standard has a 14-day free trial period and then later it charges $100 per month for 5 million rows per month.
Conclusion
In this blog post, we provided you with a list of the best ETL tools in the market to perform ETL and its features. AWS Redshift has exceptional capabilities to process petabytes of data, and generate in-depth insights.
However, if you’re looking for the perfect solution to perform Redshift ETL, we recommend you to try Hevo Data, a No-code Data Pipeline helps you transfer data from a source of your choice in a fully-automated and secure manner without having to write code repeatedly.
Sign up for a 14-day free trial and simplify your data integration process. Check out the pricing details to understand which plan fulfills all your business needs.
Frequently Asked Questions
1. Is Amazon Redshift an ETL tool?
No, Redshift is a data warehouse, not an ETL tool. It stores and analyzes data.
2. What ETL tool does Amazon use?
Amazon offers AWS Glue for ETL, which helps move and transform data within its ecosystem.
3. Which tool is used to connect to Redshift database?
You can use tools like Hevo, JDBC/ODBC, or SQL Workbench to connect to Redshift for data integration and queries.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





