


 KEY TAKEAWAY
KEY TAKEAWAYMigrating from PostgreSQL to Oracle helps organizations unlock Oracle’s enterprise-grade performance, scalability, and advanced analytics. Here are the steps:
Step 1: Export PostgreSQL Data to CSV
- Use the COPY command to export PostgreSQL tables into CSV format.
- Split large datasets into smaller chunks or compress files for faster transfers.
- Verify the CSV files to ensure data accuracy before migration.
Step 2: Import CSV Data into Oracle
- Use Oracle’s Data Import Wizard and select the target table (new or existing).
- Define data formats and map PostgreSQL columns to Oracle fields.
- Choose the import mode – run script, save file, or direct import.
- Configure error handling, generate logs, and start the import.
- Monitor the progress and validate the data once migration is complete.
PostgreSQL is an open-source object-relational database used for many web and analytics applications. Oracle is a leading enterprise relational database known for advanced features and performance. Many organizations opt to migrate PostgreSQL to Oracle to leverage Oracle’s advanced features and robust performance capabilities.
This article outlines two easy steps to connect PostgreSQL to Oracle, enabling you to access data across both databases. By establishing this integration, you can migrate PostgreSQL data to Oracle while retaining live access from applications.
Table of Contents
Overview of PostgreSQL and Oracle
What is PostgreSQL?

PostgreSQL is an open-source, general-purpose, object-relational database management system, or ORDBMS. It provides advanced features along with standard compliance. These features include complex queries, foreign keys, triggers, and views—all supporting transactional integrity with full ACID compliance. Inherent in it is vast extensibility for custom data types, functions, and operators.
What is Oracle Database?

The Oracle database is a commercial RDBMS designed for enterprise-size applications that require extraordinary performance, scalability, and reliability. It has advanced features such as real application clusters (RAC) for high availability, a data guard for disaster recovery, and built-in machine learning for analytics. With robust security and 24/7 enterprise support, Oracle has found wide applications in industries such as finance, healthcare, and telecommunications.
Leverage Hevo’s powerful platform to seamlessly connect Oracle and PostgreSQL with your data destinations. Simplify your data integration process and unlock real-time insights without the need for complex coding.
Why Choose Hevo for Oracle and PostgreSQL Integration?
- Broad Source Support: Easily integrate data from both Oracle and PostgreSQL, along with 150+ other sources, into your preferred destination.
- No-Code Setup: Quickly configure and manage your data pipelines without any technical expertise.
- Real-Time Sync: Ensure your data is always up-to-date with continuous, real-time syncing.
Steps to Migrate Data from PostgreSQL to Oracle
Prerequisites
For initiating migration from PostgreSQL to Oracle, install and run PostgreSQL and Oracle.
Step 1: Export PostgreSQL Data to CSV
1. Use the COPY Command
The COPY command allows you to export data from PostgreSQL tables into CSV files.
Example:
<em>COPY employees TO '/path/to/employees.csv' DELIMITER ',' CSV HEADER;</em>- TO: Specifies the file path for the exported CSV.
- DELIMITER: Defines the character used to separate fields.
- CSV HEADER: Includes column names as the first row in the file.
Tips for Handling Large Datasets:
- Split large tables: Break down large tables into smaller chunks using WHERE clauses.
<em>COPY (SELECT * FROM employees WHERE id <= 10000) TO '/path/employees_part1.csv' CSV HEADER;</em>- Compress files: Use gzip to reduce file size and speed up transfers.
gzip /path/to/employees.csv
2. Verify Data Accuracy
Before moving forward, confirm the data in the CSV file matches the PostgreSQL table.

Step 2: Import CSV Data to Oracle
1. Decide on the Target Table
- New Table: If the data will go into a new table, go to the database menu and click ‘Import Data’.
- Existing Table: If the data will go into an existing table, go to Database Explorer, right-click the table, and select ‘Import Data.’
This opens the Data Import Wizard, preloaded with an Oracle connection, the target table, and the database.
- Click Next to proceed.
- In the Data Import Wizard, select the CSV format and specify the location of the source data file.
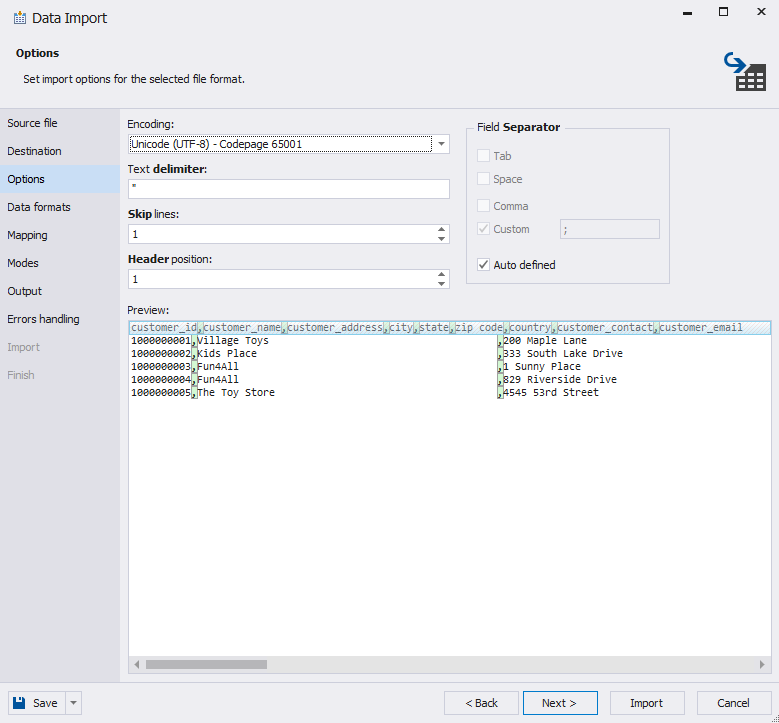
2. Define Data Formats and Map Columns
- Go to the Data Formats Tab to define the formats (e.g., date, number formats) for the source data.
- Click Next.
- Modify column properties (e.g., data types or primary keys) for a new table as needed.
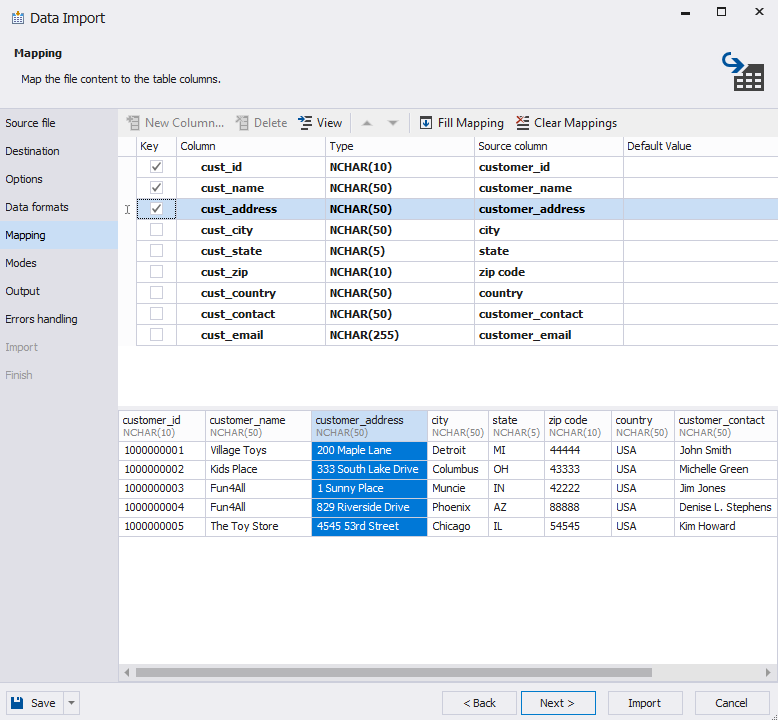
- Use the Mapping Tab to align source columns with target table columns.
- Clear Mapping: Removes all mappings.
- Fill Mapping: Automatically restores mappings.
3. Select Import Mode
On the Modes Tab, choose how the data will be imported:
- Open the import script in the editor.
- Save the script to a file.
- Import the data directly into the database.
4. Handle Errors and Start Import
- On the Errors Handling Tab, specify how to manage errors during the import.
- Decide if you want to generate a log file for the session.
- Click Import to start the migration.
- Monitor the progress, and once complete, click Finish to close the wizard.
Limitations of Using CSV Files for This Migration
- File and Record Size Constraints: Oracle systems limit data file imports to 50,000 records per file via UI or REST services, requiring splitting or using EDLC for larger datasets.
- Manual Data Management: Handling relationships between CSV files manually risks errors and compromises data integrity, especially with multiple related tables.
- Exporting Large Data Sets: Managing Oracle tables with millions of records involves writing complex SQL queries and exporting data in chunks, which is time-consuming.
- Data Type and Format Issues: Exporting complex data types like objects or multivalued fields requires careful attention to formatting and data types in CSV exports.
- Performance Impact: Exporting large data volumes can strain Oracle database performance, consuming significant resources and potentially impacting other operations.
- Error Handling: Manual exports are prone to errors, necessitating manual intervention and complicating the export process.
- User Feedback and System Limitations: Users request higher export limits due to critical issues for businesses needing detailed, extended data extraction.
Common Challenges and How to Overcome Them
1. Data Type Incompatibilities
PostgreSQL and Oracle have different data types. Plan for conversions like:
- Boolean: Convert to Oracle
NUMBER(1). - Serial/Auto-increment: Replace with Oracle sequences.
2. Performance Issues
- Batch Processing: Import data in smaller batches to avoid memory overload.
- Indexes: Disable indexes during imports and re-enable them afterward.
3. Referential Integrity
Ensure foreign key relationships are maintained by first importing parent tables.
Best Practices to Enhance The Migration Process
- Analyze Schema Compatibility: PostgreSQL and Oracle differ in their data types and constraints. Plan schema mapping carefully to ensure compatibility, converting types like BOOLEAN to NUMBER(1) and SERIAL to Oracle sequences.
- Plan Thoroughly: Create a detailed migration plan with objectives, timelines, risks, and stakeholder roles to ensure smooth execution.
- Test and Validate: Thoroughly test migrated schemas and data for accuracy, ensuring application compatibility before production.
- Schedule Downtime: Plan migrations during non-peak hours to minimize business disruptions.
- Monitor Progress: Enable logging to track the migration process and quickly address errors.
Additional Resources for PostgreSQL Integrations and Migrations
- How to load data from PostgreSQL to Biquery
- Postgresql on Google Cloud SQL to Bigquery
- Integrate Postgresql to Databricks
- Replicate Postgres to Snowflake
- Export a PostgreSQL Table to a CSV File
Conclusion
Migrating data from PostgreSQL to Oracle can seem daunting, but it becomes a straightforward process with the proper steps and tools. Using the Data Import Wizard effectively ensures that your data is accurately transferred, whether you’re working with a new or existing table. Properly configuring options such as header rows, column mappings, and import modes allows you to tailor the migration to your requirements.
Always remember to handle errors proactively and generate logs to troubleshoot any issues. With a clear understanding of the abovementioned process, you can perform seamless migrations and focus on leveraging your data for business insights. For related PostgreSQL or Oracle migrations, try Hevo. Hevo also supports PostgreSQL as a destination for various use cases. Get started today, and make your data migration journey smooth and efficient!
FAQ
How to connect PostgreSQL and Oracle?
To connect PostgreSQL to Oracle, you can use database migration tools like Oracle SQL Developer or open-source tools like pgAdmin to export data from PostgreSQL and import it into Oracle. Another approach is to use ETL (Extract, Transform, Load) tools like Hevo Data, Talend, or Apache Nifi for seamless data migration.
Why migrate to Postgres from Oracle?
There are a few benefits of migrating from Oracle to Postgres:
1. Cost Savings: Postgres is open-source and free, reducing licensing costs
2. Flexibility: PostgreSQL offers extensibility and supports various data types.
3. Community Support: Strong community support for troubleshooting and development.
How to migrate SQL Server database to Oracle?
To migrate the SQL Server database to Oracle, follow these steps:
1. Backup your SQL Server database
2. Use tools such as Oracle SQL Developer
3. Extract data from SQL Server using Bulk Data Program
4. Convert SQL Server schema to Oracle-compatible schema
5. Load data using SQL Loader
6. Verify data integrity once the migration is completed
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




