

Easily move your data from Mixpanel To Databricks to enhance your analytics capabilities. With Hevo’s intuitive pipeline setup, data flows in real-time—check out our 1-minute demo below to see the seamless integration in action!
To make data insights easily accessible, setting up a Mixpanel to Databricks connection can be a game-changer for your business teams. When data scientists and business analysts need quick access to crucial insights, efficiency matters. The most straightforward way is often through Mixpanel’s APIs, though a no-code tool could save time and handle the entire integration process, letting you focus on strategic tasks.
In this guide, we’ll walk you through connecting Mixpanel to Databricks step-by-step so you can deliver essential data to your marketing team effectively and without delay.
Table of Contents
Introduction to Mixpanel

Mixpanel is a powerful product analytics tool designed to help businesses understand user behavior and drive data-driven decision-making. It enables organizations to track, analyze, and optimize user interactions across web and mobile platforms, offering insights into user engagement, retention, and conversion.
Method 1: Using Mixpanel APIs to Connect Mixpanel to Databricks
You will need to use engineering resources to write the scripts to get data from Mixpanel’s API and then to Databricks. You will also need to maintain the infrastructure for this and monitor the scripts on an ongoing basis.
Method 2: Using Hevo Data to Connect Mixpanel to Databricks
Hevo has a visual interface that lets you copy data in a hassle-free fashion from Mixpanel to Databricks in real-time. Your data will be replicated with 100% accuracy in your data warehouse without having to write any code.
Get Started with Hevo for FreeKey Features of Mixpanel
- Event Tracking: Captures detailed user interactions and events, allowing for granular analysis of user behavior.
- Segmentation: Provides advanced segmentation capabilities to analyze user groups based on various attributes and behaviors.
- Funnels: Tracks user progress through predefined steps to identify conversion rates and drop-off points.
- Cohort Analysis: Analyzes user groups over time to understand retention patterns and the impact of changes on user behavior.
Introduction to Databricks

Databricks is a popular Cloud-based Data Engineering platform developed by the creators of Apache Spark. It deals with large amounts of data and allows you to easily extract valuable insights from it. With the main focus on Big Data and Analytics, it also assists you in the development of AI (Artificial Intelligence) and ML (Machine Learning) solutions.
Key Features of Databricks
Databricks comprises a variety of features that help users work more efficiently on the Machine Learning Lifecycle. Some of the key features of Databricks include:
- Interactive Notebooks: Databricks’ interactive notebooks provide users with a variety of languages (such as Python, Scala, R, and SQL) and tools for accessing, analyzing, and extracting new insights.
- Integrations: Databricks can be easily integrated with a variety of tools and IDEs (Integrated Development Environment), including PyCharm, IntelliJ, Visual Studio Code, etc., to make Data Pipelining more structured.
- Delta Lake: Databricks houses an open-source Transactional Storage layer that can be used for the whole data lifecycle. This layer brings data scalability and reliability to your existing Data Lake.
Method 1: Replicate Data from Mixpanel to Databricks Using Mixpanel APIs
To start replicating data from Mixpanel to Databricks, you need to use one of the Mixpanel APIs, that is, Event Export API:
- Step 1.1: Data in Mixpanel is stored as JSON data. Mixpanel provides the Event Export API to retrieve the data. The following command is generated by Mixpanel for you after providing your basic authentication details:
$ python -m pip install requests
import requests
url = "https://data.mixpanel.com/api/2.0/export"
headers = {
"accept": "text/plain",
"authorization": "Basic aGFyc2g6MTIzNDU2"
}
response = requests.get(url, headers=headers)
print(response.text)
You need to modify a bit to store your response as JSON file:
import requests
url = "https://data.mixpanel.com/api/2.0/export"
headers = {
"accept": "text/plain",
"authorization": "Basic aGFyc2g6MTIzNDU2"
}
response = requests.get(url, headers=headers).json()
import json
with open('personal.json', 'w') as json_file:
json.dump(json_data, json_file)
- Step 1.2: You can read the JSON files in single-line or multi-line format in Databricks. In a single-line manner, a file may be split into multiple parts and expressed in parallel. In multi-line style, a file is capsulated in one body and cannot be split.
To read the JSON file in a single-line format, you can use the following command in Scala:
val df = spark.read.format("json").load("your-file-name.json")
To read the JSON file in a multi-line format, you can use the following command in Scala:
val mdf = spark.read.option("multiline", "true").format("json").load("/tmp/your-file-name.json")
Although the charset is detected automatically in Databricks, but you can also provide it using the Charset option:
spark.read.option("charset","UTF-16BE").format("json").load("your-file-name.json")This process using the Mixpanel APIs is a great way to replicate data from Mixpanel to Databricks effectively. It is optimal for the following scenarios:
- APIs can be programmed as customized scripts that can be deployed with detailed instructions on completing each workflow stage.
- Data workflows can be automated with APIs, like Mixpanel APIs in this scenario. These scripts can be reused by anyone for repetitive processes.
Limitations of using Mixpanel APIs to connect Mixpanel to Databricks
- Using this method requires you to make API calls and code custom workflows. Hence, it requires strong technical knowledge.
- Updating the existing API calls and managing workflows requires immense engineering bandwidth and, hence, can be a pain point for many users. Maintaining APIs is costly in terms of development, support, and updating.
- When the frequency of replicating data from Mixpanel increases, this process becomes highly monotonous. It adds to your misery when you have to transform the raw data every single time.
- With the increase in data sources, you would have to spend a significant portion of your engineering bandwidth creating new data connectors. Just imagine — building custom connectors for each source, transforming & processing the data, tracking the data flow individually, and fixing issues. Doesn’t it sound exhausting?
How about you focus on more productive tasks than repeatedly writing custom ETL scripts? This sounds good, right?
Method 2: Automate the Data Replication process using a No-Code Tool
Step 2.1: Configure Mixpanel as your Source
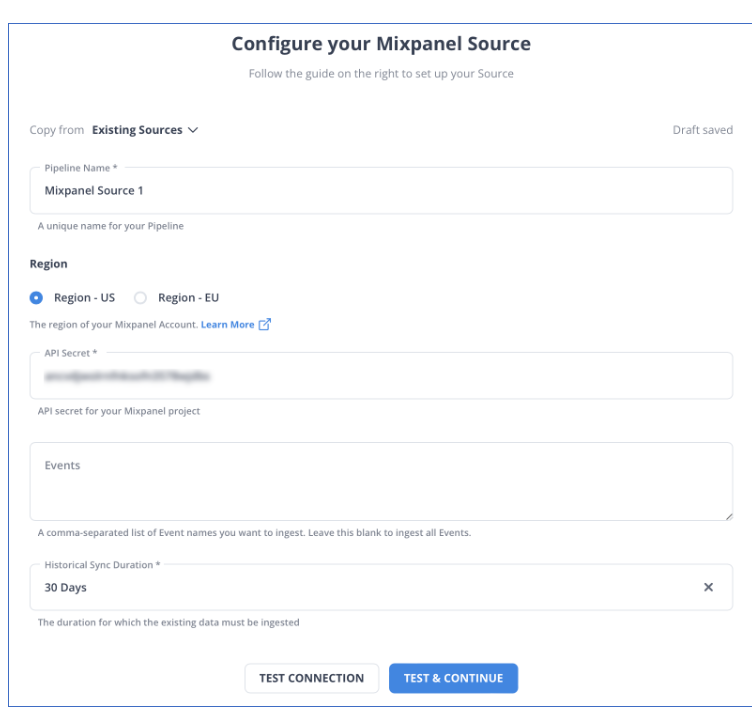
Step 2.2: Configure Databricks as a Destination
Once your Mixpanel to Databricks ETL Pipeline is configured, Hevo will collect new and updated data from Mixpanel every five minutes (the default pipeline frequency) and duplicate it into Databricks. Depending on your needs, you can adjust the pipeline frequency from 5 minutes to an hour.
How does Hevo Stand Out from the Rest?
- Fully Managed: You don’t need to dedicate time to building your pipelines. With Hevo’s dashboard, you can monitor all the processes in your pipeline, thus giving you complete control over it.
- Data Transformation: Hevo provides a simple interface to cleanse, modify, and transform your data through drag-and-drop features and Python scripts. It can accommodate multiple use cases with its pre-load and post-load transformation capabilities.
- Schema Management: With Hevo’s auto schema mapping feature, all your mappings will be automatically detected and managed to the destination schema.
- Scalable Infrastructure: With the increase in the number of sources and volume of data, Hevo can automatically scale horizontally, handling millions of records per minute with minimal latency.
- Live Support: The support team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.

What Can You Achieve by Migrating Your Data from Mixpanel to Databricks?
Here’s a little something for the data analyst on your team. We’ve mentioned a few core insights you could get by replicating data from Mixpanel to Databricks. Does your use case make the list?
- What percentage of customers from a region have the most engagement with the product?
- Which features of the product are most popular in a country?
- Your power users are majorly from which location?
- How does Agent performance vary by Product Issue Severity?
- How to make your users happier and win them over?
- What are the custom retention trends over a period of time?
- What is the trend of a particular feature adoption with time?
You can also read more about:
- Mixpanel to Redshift
- Segment to Databricks
- Google Analytics 4 to Databricks
- ActiveCampaign to Databricks
Summing It Up
Mixpanel APIs are the right path for you when your team needs data from Mixpanel once in a while. However, a custom ETL solution becomes necessary for the increasing data demands of your product or marketing channel. You can free your engineering bandwidth from these repetitive & resource-intensive tasks by selecting Hevo’s 150+ plug-and-play integrations.
Sign up for a 14-day free trial and simplify your data integration process. Check out the pricing details to understand which plan fulfills all your business needs.
Frequently Asked Questions
1. What tools can connect to Databricks?
a) Business Intelligence (BI) Tools
b) Data Integration and ETL Tools
c) Big Data and Streaming Tools
2. What type of cluster is Databricks?
Databricks primarily uses Apache Spark clusters.
3. Can I use Databricks without spark?
No, Databricks is fundamentally built on Apache Spark, so Spark is an integral part of the platform.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link












