




Easily move your data from Freshdesk To Databricks to enhance your analytics capabilities. With Hevo’s intuitive pipeline setup, data flows in real-time—check out our 1-minute demo below to see the seamless integration in action!
So trying to replicate data from Freshdesk to Databricks? It’s great to connect with someone who values the impact of delivering top-notch customer service for their business. You’re focused on providing the right value to your clients through the most suitable contact channels.
At times, the key stakeholders in your company might need a comprehensive, 360-degree view of your data. That’s where you come in. To keep your analysts and data scientists productive, you’ll want to integrate support data from Freshdesk with information from other teams, right?
If you’re looking for a straightforward, step-by-step guide on replicating data from Freshdesk to Databricks, you’re in the right place. But let’s first look at Freshdesk and Databricks.
Table of Contents
What is Freshdesk?

Freshworks offers Freshdesk, a cloud-based customer support tool that manages every facet of client interaction. By tracking tickets from several channels, giving support via phone, chat, and messaging applications, classifying and prioritizing issues, and providing preformatted answers for frequently asked problems, it aids teams in managing support more effectively.
What is Databricks?

Databricks is an open-source storage layer that helps you build a data lakehouse architecture. This setup combines the speed of data warehousing with the cost-effectiveness of a data lake. Databricks works seamlessly with your existing data lake and is fully compatible with Apache Spark, an open-source engine for processing large data sets.
Why waste time on manual data transfers? With Hevo’s simple, no-code pipeline, you can move data from Freshdesk to Databricks in just a few clicks! It supports over 150 integrations and keeps your data up-to-date, so it’s always ready for analysis.
Why Hevo?
- No-Code Simplicity: Move data from Freshdesk to Databricks in just a few clicks with Hevo’s easy-to-use interface.
- Real-Time Sync: Hevo keeps your data automatically up-to-date, so it’s always ready for analysis.
- Boost Productivity: Free up time for valuable tasks by automating data transfers, saving you from manual work.
Sounds good? Give Hevo a try today! Try the 14-day trial for Hevo and experience the ultimate one-stop data pipeline solution for all your problems.
Get started for Free with Hevo!Method 1: Replicate Data from Freshdesk to Databricks Using Hevo
Hevo can help you quickly replicate data from Freshdesk to Databricks in just two simple steps:
Step 1: Configure Freshdesk as your Source
- Fill in the required attributes required, for configuring Freshdesk as your source.

Note: You can create an API token from your Freshdesk support portal. You can go to the Profile Settings option and access your API token.
Step 2: Configure Databricks as your Destination
Now, you need to configure Databricks as the destination.

After implementing the 2 simple steps, Hevo will build the pipeline for replicating data from Freshdesk to Databricks based on the inputs you provide while configuring the source and the destination.
Why you should Consider Hevo
- Fully Managed: You don’t need to spend time building pipelines. With Hevo’s easy-to-use dashboard, you can keep an eye on every process and have complete control over your data flow.
- Ease of Data Transformation: Clean and transform your data effortlessly using drag-and-drop features or Python scripts. It’s built to handle various use cases with both pre-load and post-load transformation options.
- Faster Insights: Get near real-time data replication so you can access insights and make decisions faster.
- Automatic Schema Management: Hevo takes care of schema mapping for you, automatically detecting and managing data to fit your destination schema.
- Scalable Infrastructure: Hevo is capable of scaling itself with growing volumes and sources of data.
- Clear Pricing: Choose a plan that suits your needs. Hevo’s pricing is straightforward, and you can set credit limits and get alerts for increased data flow.
- 24/7 Live Support: In case of any queries or help, Hevo’s support team is available around the clock via chat, email, and calls.

Method 2: Replicate Data From Freshdesk to Databricks Manually
Freshdesk, being a cloud-based customer service platform, stores data about customers. This data is categorized into two components, i.e., Companies and Contact in Freshdesk.
Follow along to replicate data from Freshdesk to Databricks in CSV format:
Step 1: Export CSV Files from Freshdesk
- Click on the hamburger icon on the top-left corner of your Freshdesk window.
- Select the “Companies” or “Contact” option based on which data you want to export
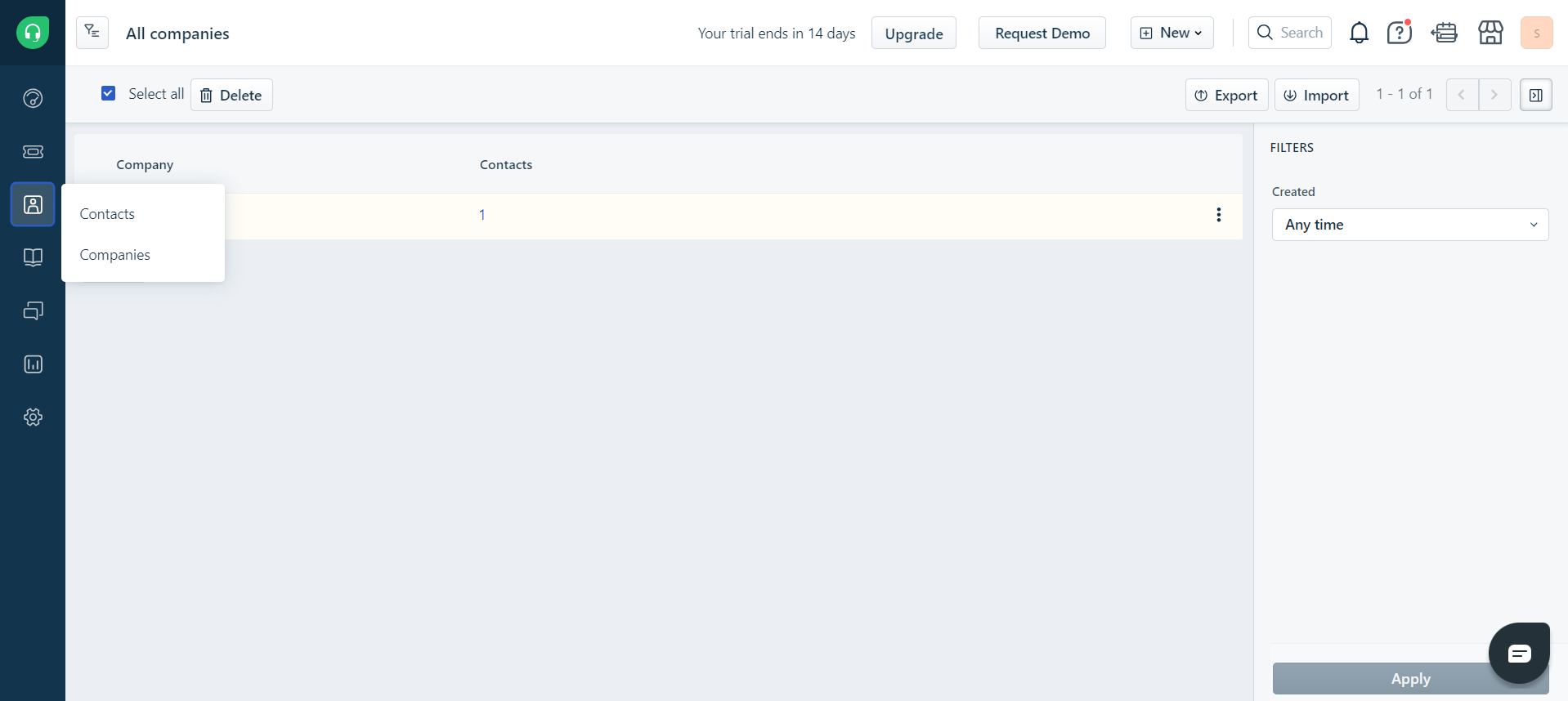
- Select the “Export” button.
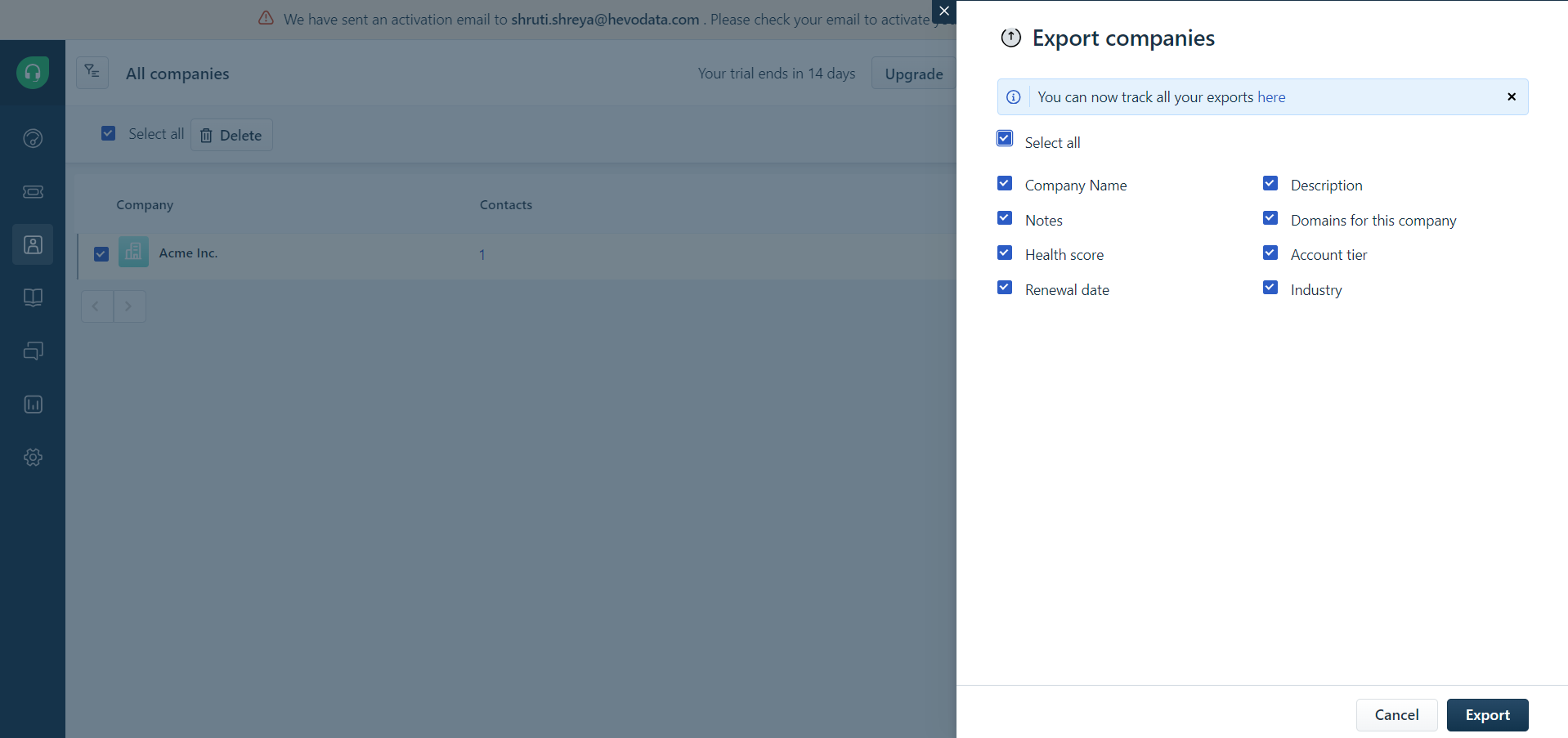
- Now, you can select the fields which you want to export. Following that, click the “Export” button. A CSV file containing all the required data will be sent to the email address associated with the Freshdesk account.
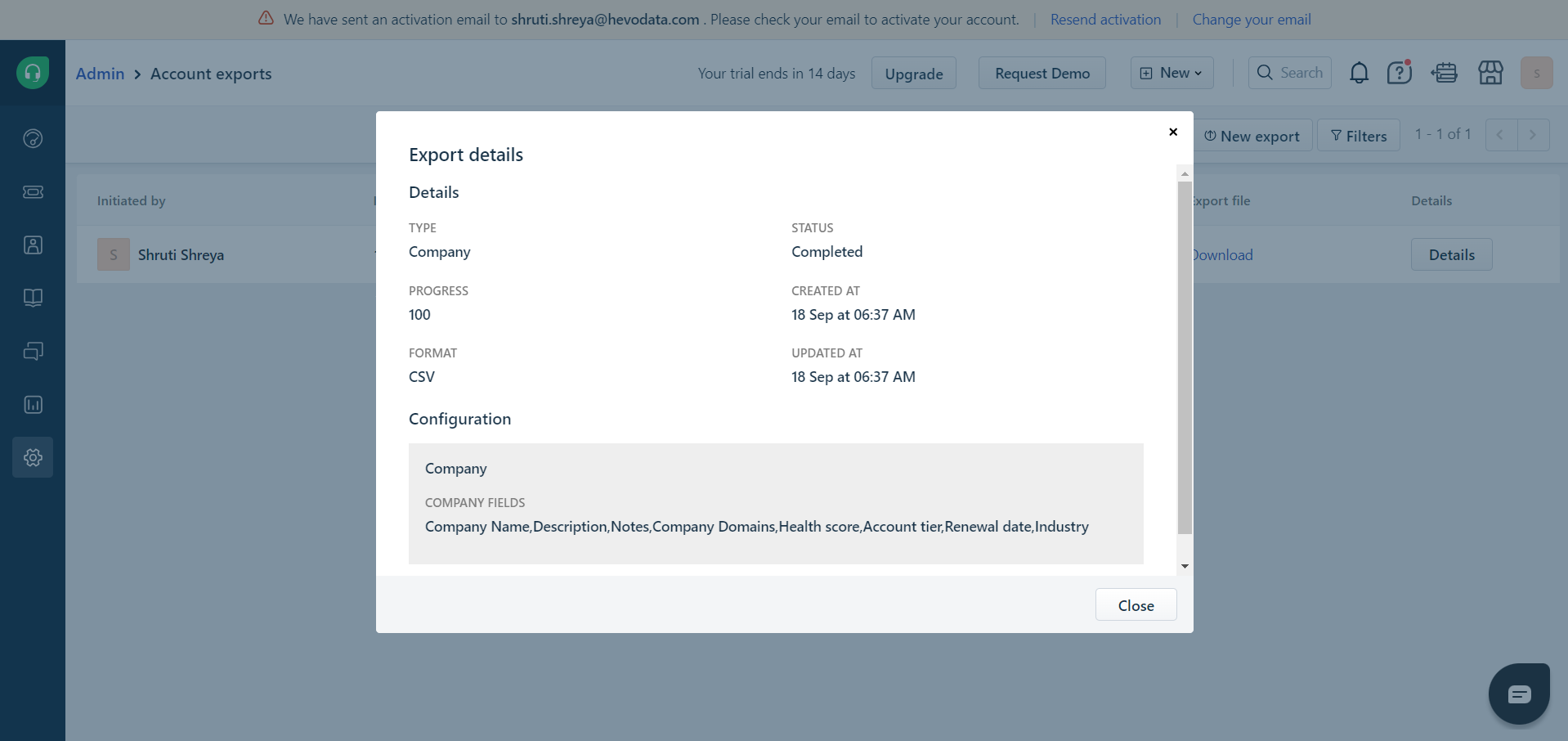
Step 2: Import CSV Files into Databricks
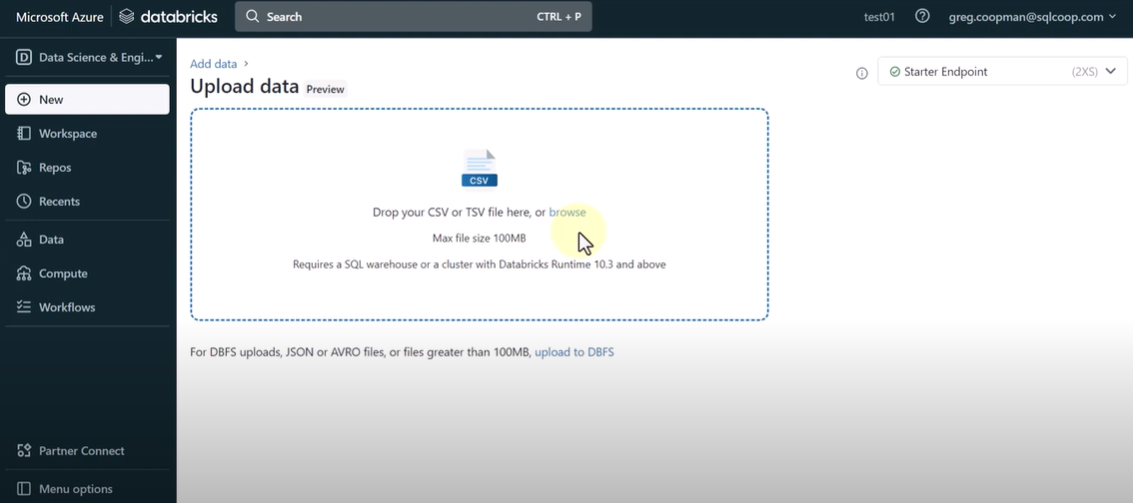
- In the Databricks UI, go to the side navigation bar. Click on the “Data” option.
- Now, you need to click on the “Create Table” option.
- Then drag the required CSV files to the drop zone. Otherwise, you can browse the files in your local system and then upload them.
After uploading the CSV files, your file path will look like this:
/FileStore/tables/<fileName>-<integer>.<fileType>
Step 3: Modify & Access the Data
- Click on the “Create Table with UI” button.
- The data has been uploaded to Databricks. You can access the data via the Import & Explore Data section on the landing page.
- To modify the data, select a cluster and click on the “Preview Table” option.
- Then change the attributes accordingly and select the “Create Table” option.
This 3-step process using CSV files is a great way to effectively replicate data from Freshdesk to Databricks. This method is ideal for small data volumes, one-time replication needs, and clean datasets that don’t require transformation. But it will not be that efficient in the following scenarios:
- Frequent Data Updates: When your data needs to be updated more often and automatically, this method can be troublesome as it will involve more manual effort.
- High volume of data: It will be difficult to handle large amounts of data or a high number of reports manually.
- Complex transformations involved : This method’s limited transformation options might not be sufficient for complex transformations.
- Scalability issue: Managing CSVs manually with increasing data becomes highly time-consuming.
What Can You Achieve by Replicating Your Data from Freshdesk to Databricks?
Here’s a little something for the data analyst on your team. We’ve mentioned a few core insights you could get by replicating data from Freshdesk to Databricks. Does your use case make the list?
- What percentage of customers’ queries from a region are through email?
- The customers acquired from which channel have the maximum number of tickets raised?
- What percentage of agents respond to customers’ tickets acquired through the organic channel?
- Customers acquired from which channel have the maximum satisfaction ratings?
Read More About:
- Freshdesk to Snowflake
- Zendesk to Databricks
- Google Analytics 360 to Databricks
- Salesforce to Databricks
Summing It Up
Manual downloading of the CSVs and uploading them works if data replication from Freshdesk to Databricks is infrequent. However, the need for data on a regular basis may call for automation – a case where an automated solution like Hevo provides a faster experience.
Hevo has an intuitive no-code data pipeline with more than 150 plug-and-play integrations. It supports smooth data replication from various sources. Navigate through an easy-to-use UI, with pre-load transformation capabilities, to avoid manual cleaning of data. With Hevo, one can have automated data processing for various use cases, and their 24×7 support team ensures onboarding. Try the 14-day free trial by Hevo to experience its service for building a data pipeline from Freshdesk to Databricks.
FAQs
1. What is the benefit of integrating Freshdesk with Databricks?
Integrating Freshdesk with Dtaabricks supports data for analysis and helps in streamlining data-driven decision-making. Hevo simplifies this process with its no-code platform.
2. What expertise is needed to set up?
Only basic knowledge is required, as Hevo provides a no-code platform. This makes the setup process simple and quick for anyone.
3. Does Hevo support data security during the integration?
Yes, Hevo ensures data security with end-to-end encryption and follows data privacy regulations.
Feel free to catch up and let us know about your experience of employing a data pipeline from Freshdesk to Databricks using Hevo.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



