


 Key Takeaways
Key TakeawaysThe right Oracle replication tool depends on whether your priority is analytics modernization, cloud migration, disaster recovery, or enterprise-scale synchronization.
The top 6 tools include:
- Hevo Data simplifies real-time Oracle replication with a fully managed no-code platform.
- Carbonite Availability focuses on disaster recovery with byte-level replication and failover support.
- Quest SharePlex specializes in Oracle-to-Oracle replication and real-time lakehouse integration.
- Oracle GoldenGate supports enterprise-scale heterogeneous replication across complex environments.
- IBM InfoSphere Data Replication is built for hybrid replication with bidirectional sync and conflict resolution.
- AWS DMS helps AWS teams manage Oracle migration and replication workflows.
Note: Real-time CDC, schema handling, monitoring visibility, and operational overhead are the biggest differentiators between modern Oracle replication platforms.
Oracle replication sounds straightforward until replication lag, failed failovers, or schema changes start disrupting downstream systems. And with cloud and hybrid environments in the mix, choosing the right replication tool becomes much harder.
Some platforms are built for disaster recovery, others focus on enterprise database synchronization, while newer tools prioritize low-maintenance, real-time data movement into modern cloud stacks.
In this guide, we’ll break down the top Oracle replication tools to consider in 2026, comparing them across
- Replication capabilities
- Setup complexity
- Pricing
- Operational overhead
So you can find the right fit for your environment.
Table of Contents
Overview of the Top 6 Oracle Replication Tools
Here’s a quick comparison table of the top Oracle replication tools:
| Factors | Hevo Data | Carbonite Availability | Quest SharePlex | Oracle GoldenGate | IBM InfoSphere | AWS DMS |
| Type | No-code ELT | HA/DR replication | Database replication | Enterprise CDC | Hybrid data replication | Cloud migration service |
| No-code Setup | Yes | No | No | No | No | Partial |
| CDC method | LogMiner | Byte-level | Redo log | Redo log | Log-based CDC | LogMiner / Binary Reader |
| Connectors | 150+ connectors | Limited integrations | Oracle-focused | 100+ supported endpoints | Enterprise-level | AWS-native |
| Schema Evolution | Automatic handling | Manual updates | Partial handling | DDL replication | Configurable | Basic |
| Transformation | Built-in SQL/Python | Not supported | Minimal | Stream processing | Limited transformation logic | Basic mapping rules |
| Multi-Cloud Support | AWS, Azure, GCP | Primarily on-prem | Partial cloud support | AWS, Azure, OCI, GCP | Hybrid + multi-cloud | AWS-focused |
| Fault Tolerance | Auto-healing pipelines | Continuous failover | Queue-based recovery | Active-active replication | Conflict detection | Managed AWS recovery |
| Security | SOC 2, GDPR | Enterprise-grade security | Role-based access | Oracle enterprise-level | IBM enterprise security | AWS IAM + KMS |
| Best For | Real-time analytics | Business continuity | Oracle database sync | Large enterprise estates | Hybrid environments | AWS migrations |
Say goodbye to manual coding for your data pipelines and embrace Hevo’s No-Code, Fully Automated ETL solution. With Hevo, you can effortlessly replicate data from over 150 ready-to-use integrations, including Oracle, to any target warehouse or database.
Setting up data pipelines with Hevo is a simple three-step process: select the data source, provide valid credentials, and choose the destination.
Trust Hevo for your data replication process for a hassle-free experience. This will enable you to spend more time on data analysis and less time on data aggregation.
Get Started with Hevo for FreeHow Did We Shortlist the Best Oracle Replication Tools?
To shortlist the best Oracle replication tools, we analyzed:
- G2 reviews and community feedback to identify common pain points around setup, maintenance, reliability, and pricing.
- Reddit threads and engineering communities highlighted the tools most frequently recommended for production Oracle workloads.
- Official product documentation and walkthroughs helped compare replication methods, cloud compatibility, and deployment flexibility.
- Priority was given to platforms consistently mentioned in analytics modernization, cloud migration, and hybrid replication discussions.
After comparing dozens of options, six tools made it to our final shortlist.
Top 6 Oracle Replication Tools
Below are the top 6 Oracle replication tools handpicked by our experts:
1. Hevo Data

Rating: 4.4/5(G2)
Hevo Data is a fully managed, no-code ELT platform designed to simplify data replication and movement across modern data stacks. It enables teams to build reliable data pipelines without writing custom scripts, maintaining complex workflows, or worrying about how to connect to Oracle DB.
The platform helps data teams replicate Oracle data for analytics, reporting, and Oracle to BigQuery ETL workflows in near real time. With support for 150+ connectors, Hevo is particularly useful for organizations looking to modernize legacy Oracle environments and centralize their data stack.
What makes Hevo stand out is its balance between enterprise-grade reliability and operational simplicity. While many Oracle replication tools require heavy configuration and continuous maintenance, Hevo’s automated schema management, fault-tolerant pipelines, and end-to-end pipeline visibility allow teams to scale replication workflows hands-free.
Key features:
- Oracle Redo Log-Based CDC: Hevo connects to Oracle using LogMiner to read directly from Redo Logs for efficient Oracle change tracking, capturing inserts, updates, and deletes without querying source tables, making it the optimal mode for Oracle replication.
- Historical Load Flexibility: You can choose whether to backfill all existing Oracle data or capture only changes from the pipeline creation point, giving teams direct control over the backfill scope on the first run.
- Configurable Redo Log Controls: Hevo exposes advanced settings like poll interval, query fetch size, and a long transaction window directly in the pipeline configuration, giving teams fine-grained control over Oracle log mining.
- Multi-Destination Replication: Replicates Oracle data to cloud warehouses such as Snowflake, Google BigQuery, and Oracle to Redshift pipelines via a single pipeline.
Pros:
- Faulty records are isolated without halting the entire pipeline.
- Supports both archived and online redo logs simultaneously.
- Auto-detects and includes new Oracle tables added post-pipeline creation.
- No version control support for pipeline configurations.
User review:
“I really appreciate Hevo Data’s great customer service and easy interface. People get back to you super fast, and tickets are resolved quickly, which is a big plus for me. The customer support team is also a great help with research because they know the documentation of all APIs really well. The initial setup was easy, which made the transition smooth.”
Hevo Data Pricing
Hevo provides Transparent Pricing to bring complete visibility to your ETL spend.
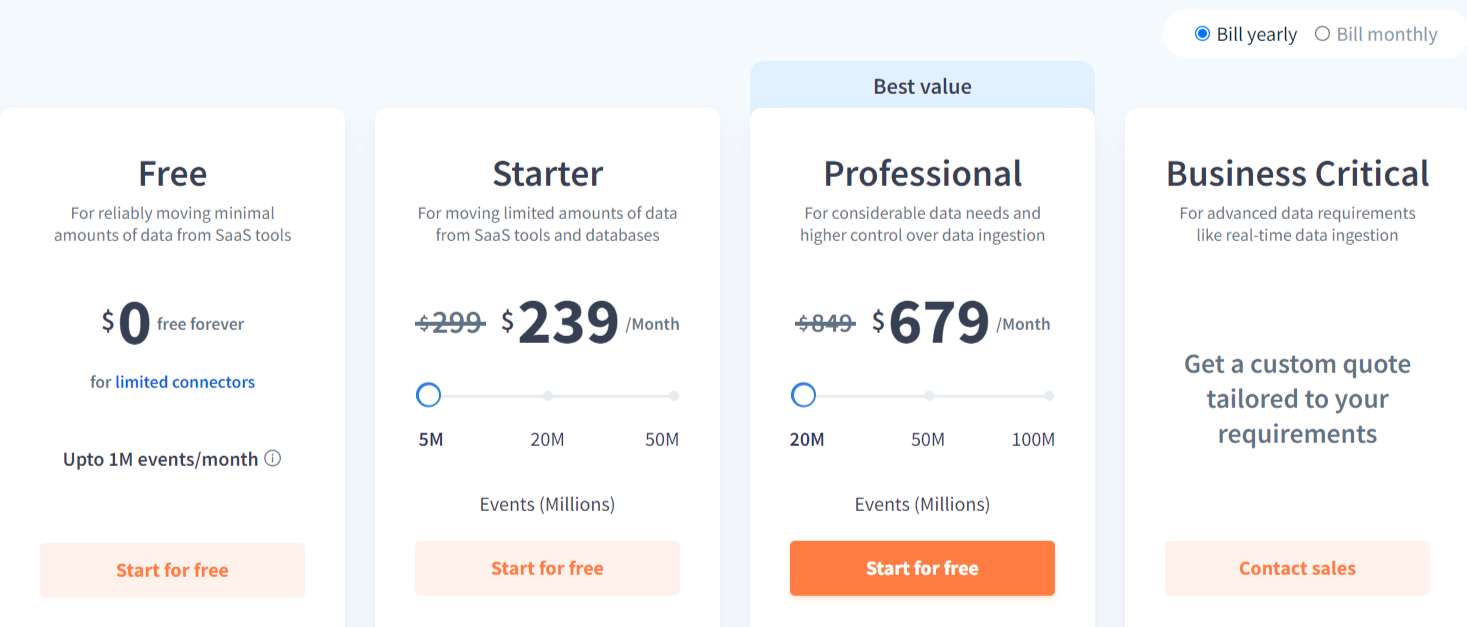
Stay in control with spend alerts and configurable credit limits for unforeseen spikes in the data flow.
2. Carbonite Availability

Rating: 4.1(G2)
Carbonite Availability is one of the data replication tools for Oracle that ensures that crucial systems of any business are accessible to all necessary users and applications that depend on them at all times. This software keeps all critical business systems available at all times and prevents data loss on Linux and Windows Servers. It houses a continuous replication technology, that is capable of maintaining an up-to-date copy of the operating business environment without putting too much load on the primary system or network bandwidth.
Key features:
- Patented Byte-Level Replication: Carbonite captures and transmits only the changed bytes within an Oracle database file rather than full datasets. This keeps the network overhead minimal across physical, virtual, or cloud targets.
- Seconds-Long Recovery Points: With Carbonite’s real-time application at the byte level, you can achieve a Recovery Point Objective (RPO) within seconds. It’s viable for Oracle environments where data loss tolerance is extremely low.
- Automatic Failover via Heartbeat Monitoring: Carbonite implements automatic failover using a server heartbeat monitor, allowing Oracle workloads to switch to the secondary server without manual intervention when the primary goes down.
Pros:
- AES-256 encryption protects Oracle data in transit.
- Hardware agnostic, works across any physical, virtual, or cloud environment.
- Supports Oracle Enterprise Linux as a certified source platform.
Cons:
- No CDC or log-based capture specific to Oracle’s redo log architecture.
- No support for heterogeneous Oracle-to-warehouse replication.
- Limited transformation or data manipulation capabilities during replication.
“Our critical Windows and Linux servers remain available due to the presence of OpenText Availability. The steady replication approach preserves an evolving backup site which facilitates swift resilience in the event of downtime.”
Carbonite Availability Pricing
Carbonite does not follow a transparent pricing model for its Data Replication offering and the final price depends on the requirements and infrastructure.
More information on Carbonite can be found here.


3. Quest Shareplex

Rating: 4.3(G2)
Quest Shareplex is a popular Oracle Database Replication software that can ensure high Availability, Scalability, and Reporting. With Quest SharePlex, users can replicate Oracle data to another Oracle Database, in SQL Server, or Kafka.
Key features:
- Built-In Compare and Repair: SharePlex automatically validates data integrity at the row level between source and target to detect and correct inconsistencies during ongoing replication without manual intervention.
- Real-Time Oracle Data to Lakehouse Platforms: It delivers Parquet-formatted Oracle data directly into S3 or Azure Blob for Databricks and Microsoft Fabric, with no additional ETL tools or custom scripts required.
- AI Insights for Replication Diagnostics: SharePlex AI Insights is a free web-based add-on that provides AI-driven performance diagnostics and a plain-language assistant grounded in the SharePlex replication knowledge base.
Pros:
- Captures Oracle redo logs without locks or impact on source performance.
- Supports Oracle Standard Edition, avoiding forced Enterprise Edition upgrades.
- Automated target creation eliminates manual schema setup during replication.
Cons:
- Cannot be installed directly on Microsoft Azure PaaS environments.
- Performance heavily dependent on supplemental logging configuration at source.
- Separate license keys required for each target platform, increasing cost complexity.
Pricing:
Quest Shareplex does not follow a transparent pricing model and the final price depends on your business and data requirements. Contact sales for a custom quote.
User review:
“QuestSoft is kept up to date with the latest regulations so that you receive erros in your data. I really like the ease of use and simplicity of the software. Scrubbing HMDA data could not any clarer.”
4. Oracle GoldenGate

Rating: 3.9(G2)
GoldenGate is a product by Oracle that gives businesses the ability to replicate, filter, and transform data from one Oracle database to another supported heterogeneous database. This tool is capable of replicating data 6 times faster than other traditional data movement solutions and ensures high availability, disaster recovery, and zero downtime migrations.
Key features:
- AI-Powered Vector Data Replication: GoldenGate natively captures and delivers Oracle’s vector data type for real-time vector processing, which makes it the only replication tool with built-in support for Oracle’s AI database architecture.
- Fully Managed Cloud Deployment via OCI: OCI GoldenGate is a fully managed cloud service where teams can run and monitor replication tasks without allocating or managing any underlying compute environments.
- GoldenGate Veridata for Data Validation: Veridata compares source and target data concurrently with active replication, identifying discrepancies and producing accurate comparison reports without interrupting transactions.
Pros:
- Supports heterogeneous replication across Oracle, MySQL, SQL Server, Db2, PostgreSQL, and more.
- Veridata runs concurrently with replication without interrupting transaction.
- GoldenGate Free offers full product features under a free perpetual license.
Cons:
- Licensing costs are among the highest of any Oracle replication tool.
- Separate component licenses required for Big Data, Kafka, and non-Oracle targets.
- BYOL model on AWS RDS means users manage their own licensing and certification.
Pricing:
The pricing for Oracle GoldenGate is based on the type of usage as well as the actual requirement. With a wide range of pricing plans, Golden Gate pricing starts at $350 per user license with an additional cost of $77 for the software update, license, and support.
User review:
“Oracle Golden Gate is an excellent tool which can be used to automate the replicate between instance. There are two ways of replication is available in Golden Gate. One is uni directional and the second one is bi directional. Uni directional goldengate is used widly in reporting application where the production data is replicated to the reporting application and the reports can run over the reorting database which will avoid performance issues on the production system.”
5. IBM InfoSphere Change Data Capture

Rating: 4.8(G2)
InfoSphere CDC is IBM’s Data Replication solution that is capable of capturing database changes as they happen and replicate those changes in target databases accordingly. This tool provides its users with low-impact change capture and fast delivery of all data changes for key information management initiatives such as Dynamic Data Warehousing, Application Consolidations or Migrations, Master Data Management, Operational Business Intelligence, etc. The Data Replication using IBM InfoSphere CDC can be carried out continuously or periodically.
Key features:
- Zero-Footprint Log-Based CDC: InfoSphere captures Oracle changes directly from database logs using a zero-footprint architecture that adds no overhead to source systems. It enables zero-downtime migrations without touching source applications.
- Bidirectional Replication with Conflict Resolution: Supports active Oracle replication topologies with built-in conflict detection and resolution to prevent data divergence when changes are made simultaneously across multiple databases.
- Table-Level Error Isolation: The ONTABLEERROR parameter idles a problematic Oracle table on error while replication continues uninterrupted on all other tables, preventing a single failure from halting the entire pipeline.
Pros:
- Supports replication from Oracle to Kafka, Snowflake, BigQuery, and Hadoop.
- Available on-premises, as SaaS, and within IBM Cloud Pak for Data.
- Built-in compare utilities for determining data differences between source and target.
Cons:
- Latency higher than competing tools.
- Limited free training resources compared to competing tools.
- Performance significantly slower when routing Oracle data through DataStage.
“IBM infosphere data replication – Q replication on of the best data replication technology in the market . It allows read and write on every nodes . Real time data sync . Good documentation of errors and problem scenario is available online that too free of cost .”
6. AWS DMS

Rating: 4.1/5 (G2)
AWS Database Migration Service (AWS DMS) is a fully managed migration and replication service that helps organizations move databases to AWS with minimal downtime. It supports both homogeneous migrations like Oracle to Oracle, and heterogeneous migrations like Oracle to Amazon Aurora or PostgreSQL.
AWS DMS is designed to handle the full migration lifecycle, from initial schema conversion to ongoing change replication, all within a single managed service. Its pay-as-you-go pricing and native integration with the broader AWS ecosystem make it a practical choice for teams already running or migrating Oracle workloads to AWS infrastructure.
Key features:
- SCN-Based CDC Start Point: AWS DMS lets teams specify an exact Oracle System Change Number as the CDC start point, ensuring replication begins from a precise transaction boundary and no earlier open transactions are missed during cutover.
- Oracle TDE Encryption Support: AWS DMS natively supports Oracle Transparent Data Encryption for both data at rest in the source database and SSL encryption for data in transit between the Oracle endpoint and the replication instance.
- Dual CDC Methods for Oracles: Offers two distinct methods for capturing Oracle changes: LogMiner, which supports encryption, compression, and table clusters, and Binary Reader, which directly parses raw redo log files for significantly higher performance on large-volume Oracle workloads.
Pros:
- Multi-AZ deployment support ensures high availability for Oracle replication instances.
- Native integration with CloudWatch for real-time monitoring and migration logging.
- Reverse replication capability allows safe fallback to the source Oracle database post-cutover.
Cons:
- AWS DMS does not fully replicate Oracle ADD, DROP, and TRUNCATE DDL.
- Amazon Web Services DMS requires either the source or the target to be hosted on AWS.
- Multiple Oracle TDE encryption keys on a single source endpoint are not supported.
Pricing:
It has a pay-as-you-go pricing model with no upfront cost.
User review:
“The best features of AWS Database Migration Service include its ease of use, flexibility to support various migration scenarios, automatic schema conversion, and real-time replication capabilities. Additionally, it offers a highly secure and reliable solution for database migration with minimal downtime.”

Factors To Keep in Mind While Choosing An Oracle Replication Tools
Your organization’s requirements play a pivotal role in choosing a suitable replication tool for your business. Below are a few points to keep in mind before deciding on any of the Oracle replication software:
- Purpose of Replication: You should know why there is a need for replication of your data. It can be to move applications to the cloud, synchronize your data instance, do replication for real-time analysis, or seek a better hybrid cloud solution that meets your requirements. It is essential to understand the reason for choosing an Oracle replication tool that is suitable for you.
- Features that You Need: Look out for the features of the Oracle db replication tools and zero down the one that meets your needs. Analyze parameters such as the volume of data it replicates, supported data types, and data sources, along with supported data targets.
- Budget: Consider the budget that your organization has for spending on Oracle database synchronization tools. Prices and ease of use are the most important things to keep in mind before investing in any tool. There are many open source Oracle database replication tools as well. You can go for them if they cater to your needs.
You can also read about:
- Replicate Oracle data to BigQuery
- Migrate Oracle to Redshift with Hevo
- Migrate Oracle to Snowflake quickly
- Best Oracle ETL tools with features & pricing
Conclusion
This article provided you with an understanding of Data Replication along with a list of the best Oracle Replication Tools available in the market.
Although there are a wide variety of Data Replication tools available in the market, most of them are considered to be hard to understand and implement for someone with not enough technical knowledge of database systems.
Hence, businesses should consider using automated platforms like Hevo. It will make your life easier and make data migration hassle-free. It is User-Friendly, Reliable, and Secure.
Take 14-Day Full-Feature Free TrialFAQs Related to Oracle Replication Tools
1. What are the different types of replication in Oracle?
Different types of Replication in Oracle are:
1. Physical Standby Database (Data Guard)
2. Logical Standby Database
3. Snapshot Replication
4. Materialized View Replication
5. Oracle Streams
6. Oracle GoldenGate
2. What is Oracle GoldenGate?
GoldenGate is Oracle’s software solution that allows you to replicate, filter, and transform data between databases, ensuring real-time synchronization across diverse systems.
3. Does Oracle have an ETL tool?
Oracle offers an ETL tool called Oracle Data Integrator (ODI). This tool provides a comprehensive data integration platform that supports high-performance data movement and transformation among various systems.
4. What is Oracle?
Oracle Database is a relational database management system built to store, manage, and retrieve structured data at enterprise scale. It is widely used across industries like finance, healthcare, manufacturing, and government for managing mission-critical workloads.
Key features include:
– Redo logs: Enable reliable real-time change capture from committed Oracle transactions.
– LogMiner: Parse Oracle redo logs for log-based CDC replication.
– Supplemental logging: Capture row-level changes accurately during replication.
– Transparent Data Encryption (TDE): Secure Oracle data without interrupting replication.
– Oracle Exadata: Choose replication tools certified for Exadata environments.
5. What is Data Replication?
Data replication is the process of copying and synchronizing data from a source database to one or more target systems in real time or near real time. It ensures that multiple systems maintain consistent, up-to-date copies of the same data without disrupting the source environment.
The benefits include:
– High availability: Keep standby databases ready during outages.
– Disaster recovery: Minimize data loss during failures.
– Reduced latency: Replicate data closer to users and applications.
– Analytics offloading: Run analytics without impacting production databases.
– Zero-downtime migrations: Migrate databases without disrupting live systems.
Feel free to comment your thoughts on the Oracle replication tool in the comments!

Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





