




Businesses have a lot of data residing in multiple software in varying formats. This data will need to be coalesced in some way, to get useful insights and analytics on the performance of the business. Many companies use Kafka Oracle integration using Oracle CDC to Kafka for the publish-subscribe messaging system and allow for the publishing and consumption of messages from a Kafka topic.
Kafka can act as a pipeline that can register all the changes happening to the data, and move them between your sources like the Oracle database and destination.
In this article, we will see how to set up Kafka Oracle integration.
What Hevo Offers:
- Real-Time Data Migration: Hevo enables continuous, real-time data transfer from sources like Kafka and Oracle to your data warehouse or BI tools.
- No-Code Integration: Set up and manage data pipelines without writing a single line of code, making the process quick and user-friendly.
- Automated Data Transformation: Hevo automatically enriches and transforms your data into an analysis-ready format, reducing manual effort and ensuring consistency.
Table of Contents
How to Set Up Kafka Oracle Integration?
In this section, you will go through 3 different methods to set up Kafka Oracle Integration; you can choose the most convenient one. Follow the below-mentioned methods to set up Kafka Oracle integration.
You can also check out this blog on Oracle replication tools for easier alternatives.
Method 1: Using Kafka Connect Tool
Apache Kafka provides a tool named Kafka Connect, which enables the streaming of data between Kafka and other systems in a secure and reliable manner.
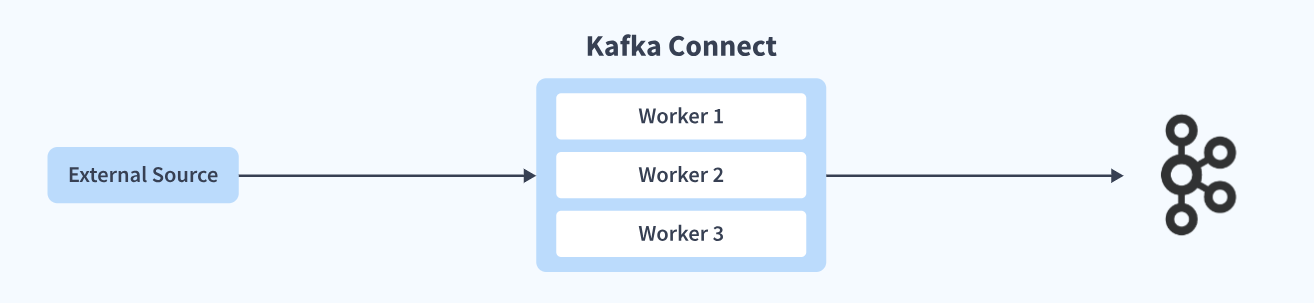
Kafka Connect can be used to enable both, incoming and outgoing connections.
Step 1. Configure Startup Worker Parameters
Configure startup worker parameters like:
- bootstrap.servers – list of Kafka servers used to bootstrap connections to Kafka.
- key.converter – Specify the class that will convert from Kafka Connect format to the serialized form that is written to Kafka. This will take care of the conversion of keys in messages written to or read from Kafka.
- value.converter – This will take care of the conversion of values in messages written to or read from Kafka.
- offset.storage.file.filename – File to store the offset data for Kafka Oracle Integration.
- config.storage.topic – Whilst using the distributed mode, this parameter specifies the topic to use for storing connector and task configurations.
- offset.storage.topic – topic to use for storing offsets; this topic should have many partitions, be replicated, and be configured for compaction.
- Connector configurations – like name, connector class, tasks.max, etc.
Step 2. Define the Transformations that you Need
In most cases, you will need some transformations to be applied to either incoming data or outgoing data, as the data format stored in Kafka partitions will be different from the source/sink databases.
- transforms – List of aliases for the transformation and the order in which the transformations should be applied.
- transforms.$alias.type – Fully qualified class name for the transformation.
- transforms.$alias.$transformationSpecificConfig – Configuration properties.
- Some inbuilt transformations that you can apply are InsertField, ReplaceField, ExtractField, SetSchemaMetadata, Filter(removes messages from further processing), etc.
Step 3. Specify your Predicates
If you want to apply the above transformation selectively to only certain messages, that fulfill a certain condition, specify them in this section.
- predicates – Set of aliases for the predicates to be applied.
- predicates.$alias.type – Fully qualified class name for the predicate.
- predicates.$alias.$predicateSpecificConfig – Configuration properties for the predicate.
Some inbuilt predicates you can use are TopicNameMatches, HasHeaderKey(matches records with a header with the given key), RecordIsTombstone, etc.
Step 4. Specify your Error Reporting and Logging Options
Kafka Connect provides error reporting, and a user can decide to take an alternative action or ignore the errors altogether.
Some frequently used options here are :
- errors.log.enable = true
- errors.log.include.messages =true – also log the problem record key/value/headers to the log.
- errors.dead letter queue.context.headers.enable – to enable or disable the dead letter queue.
Step 5. Start the Standalone Connector or Distributed Mode Connector
You can run the workers in two different modes- standalone and distributed. Standalone mode is better suited for environments that lend themselves to single agents (e.g. sending logs from webservers to Kafka), or development. The distributed model is more suitable where a single source or sink may require heavy data volumes (e.g. sending data from Kafka to HDFS), in terms of scalability and high availability to minimize downtime.
Step 6. Use REST APIs to Manage your Connectors
You can define your listeners and actions. The REST API is used to monitor/manage Kafka Connect, as well as for the Kafka Connect cross-cluster communication.
Kafka Connect Features
Kafka Connect has many useful features:-
- Standalone as well as the Distributed mode
- REST Apis in case you want to manage multiple connectors in your cluster
- Automatic offset management – Kafka Connect can manage the offset commit process automatically so connector developers do not need to worry about this error-prone part of connector development
- Scalability and Bridging between stream-based systems and batch processing systems
- Oracle CDC to Kafka for capturing changes to rows in your Oracle database and reflecting those changes from Oracle CDC to Kafka topics.
The downside of Kafka Connect is the need to configure many parameters and make sure that they do not conflict with each other or impede performance. Also, you must know how Kafka works and its background intricacies.
Method 2: Develop your Custom Connector and Use the Connect API
You can also establish Kafka Oracle integration via Connect API. If you want your connector to do much more than the connector functions and transformation provided by default, you can develop your own custom Connector, too.
Kafka provides a low-level connector-API to develop a custom connector.
A full discussion and code on how to achieve this are out of the scope of this discussion, but this can be a viable option for experienced developers.
Method 3: Using Oracle CDC to Kafka
Oracle CDC to Kafka also lets you achieve Kafka Oracle integration. Oracle CDC to Kafka is a service that works in a fashion that is somewhat similar to Kafka.

Oracle CDC to Kafka defines two abstractions of Publishers and Subscribers. It captures changes to the database tables and user actions and then makes this data available to applications or individuals (Subscribers).
Oracle CDC to Kafka captures change data in 2 ways:-
1. Synchronous – Synchronous capturing in Oracle CDC to Kafka triggers the database to allow immediate capturing of changed data, as soon as a DML command is executed.
2. Asynchronous – Asynchronous capturing in Oracle CDC to Kafka operates if there are no triggers. This Oracle CDC to Kafka mode reads the data sent to the redo log, as soon as the SQL statement containing the DML operation is committed.
A) Using GoldenGate
The easier option in Oracle CDC to Kafka is to use the Oracle proprietary Golden Gate tool ( or Attunity Replicate, Dbvisit Replicate, or Striim) for Kafka Oracle integration.
The downside here is that these tools are priced a bit heavily (more than 17K per CPU).
B) Using Kafka’s JDBC Connector
The second option for Oracle CDC to Kafka is by using Kafka’s JDBC connector, which allows you to connect with many RDBMS like Oracle, SQL Server, MySQL, DB2, etc.
This option requires a Kafka Connect runtime.
The first step is configuring the JDBC connector, specifying parameters like
- the connection details.
- topic.prefix – prefix to prepend to table names.
- mode – bulk, incrementing, timestamp, timestamp+incrementing, etc.
Use incrementing mode in this Oracle CDC to Kafka method if you need to capture only new rows and are not interested in changes to older rows. Use timestamp mode to capture a time-based detection of new and modified rows.
This option will require programming resources, and any transformation needed will need to be programmed. Some open-source tools can help a bit, but you must have insights into backend programming and JDBC functioning.

Why is Kafka Oracle Integration Important?
- Kafka’s open-source nature and wide range of connectors make it an ideal bridge between Oracle and other systems in your data ecosystem. This allows for bi-directional data exchange with various applications, analytics platforms, and cloud services.
- Integrating Kafka with Oracle streamlines data flow and processing, reducing latency and bottlenecks. This translates to faster decision-making, improved system performance, and ultimately, greater operational efficiency.
- Kafka excels at handling high-volume data streams in real-time, making it ideal for applications that require immediate response to changes, such as fraud detection, anomaly monitoring, and event-driven microservices. Oracle, on the other hand, stores and manages large volumes of structured data effectively. Combining them allows for real-time analysis and reactions based on Oracle data changes.
You can also read about:
- Migrate AWS RDS Oracle to Redshift
- Migrate AWS RDS Oracle to Databricks
- Set up CDC with Oracle and Debezium
- Migrate Oracle to PostgreSQL (step-by-step)
Conclusion
Hevo Data provides its users with a simpler platform for integrating data from 150+ sources such as Kafka and Oracle Database into a Data Warehouse for analysis. It is a No-code Data Pipeline that can help you combine data from multiple sources. You can use it to transfer data from multiple data sources into your Data Warehouse, Database, or a destination of your choice.
Curious about Oracle data integration? Check out our detailed guide to discover how Oracle’s solutions can enhance your data workflows and improve integration.
Visit our Website to Explore HevoUsing Hevo, you can connect your SaaS platforms, databases, etc. to any data warehouse of your choice, without writing any code or worrying about maintenance.
If you are interested, you can try Hevo by Sign Up for the 14-day free trial. Visit our unbeatable pricing page for more information on Hevo’s affordable pricing plans.
Share with us your experience of learning about Kafka Oracle Integration in the comment box below. Have any questions on Kafka Oracle Integration? Let us know.
Frequently Asked Questions
1. Can Kafka connect to an Oracle database?
Yes, Apache Kafka can connect to an Oracle database using Kafka Connect, a component of the Kafka ecosystem designed to integrate Kafka with various data sources and sinks.
2. Can Kafka connect to database?
Kafka Connect supports connecting to various databases for both importing and exporting data.
3. Is Kafka used for integration?
Kafka is commonly used for data streaming, event streaming, data integration, microservices communication, and log aggregation.


Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



