




So, you’re a Pipedrive user, right? It’s nice to talk to someone who knows that the customer plays the most pivotal role in the success of any business.
At times, there would be a need to move your sales & marketing data from Pipedrive to a data warehouse. That’s where you come in. You take responsibility for replicating data from Pipedrive to a centralized repository. By doing this, the analysts and key stakeholders can make super-fast business-critical decisions.
Give a high-five! We’ve prepared a simple and straightforward guide without beating around the bush. Leap forward and read the two simple methods for performing the data replication from Pipedrive to Redshift.
Table of Contents
What is Pipedrive?

Pipedrive is an easy-to-use CRM designed for sales teams to help businesses organize leads and manage customer relationships in a more streamlined fashion within the sales process, with specific features like visual pipelines, contact tracking, and sales automation that make it really easy to follow the flow of deals and increase productivity levels.
What is Redshift?

Amazon Redshift is a fully managed, petascale, and cloud-based data warehousing service owned by AWS. It allows users to store and analyze their data with various business intelligence tools and acquire insights into business operations and customers.
Amazon clusters consist of one lead node and one or more compute nodes. The size of your data will decide the exact number of nodes in your clusters. You can create a data warehouse in Redshift by launching a set of nodes called Amazon Redshift clusters. Then, Redshift will perform the queries and analyze the data query performance.
Method 1: Replicate Data from Pipedrive to Redshift Using CSV Files
This approach involves manually exporting your data from Pipedrive as CSV files and then loading them into Redshift for further processing.
Method 2: Replicate Data from Pipedrive to Redshift Using Hevo Data
Leverage Hevo’s no-code platform to automate the entire data integration process from Pipedrive to Redshift, ensuring real-time data availability without the hassle of manual intervention.
Method 1: Replicate Data from Pipedrive to Redshift Using CSV Files
Pipedrive, being a CRM platform, stores data about deals, organizations, and people. You can combine and customize different types of data before exporting.
Follow along to replicate data from Pipedrive to Redshift in CSV format:
Step 1: Export CSV Files from Pipedrive
Method 1: Exporting from the detail view
You can only export data about individual deals from the detail view.
- Click on the detail about which you want to export data.
- Go to the deal’s detail view.
- On the top left corner, click on the “…” icon. From the drop-down, select the “Export as XLS option.
- A spreadsheet with details about the deal and any information about linked people or organizations will be downloaded.
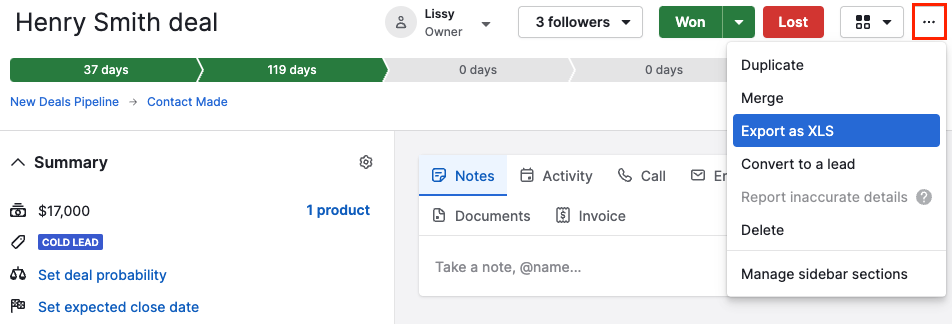
- Open the file, and go to the “Save As” dialog box. Select the location where you want to save the file. And from the file type drop-down menu, select “CSV.” Click on “Save.”
Method 2: Exporting from the list view
From the list view, you can easily export custom reports about your deals, organizations, or any other items in Pipedrive.
- Go to the list view of any item.
- Then, apply a filter that best fits the data type you want to export. For example, if you want to export information about the won deals only, you need to select the filter “All lost deals” to pull up deals that fit that criteria.
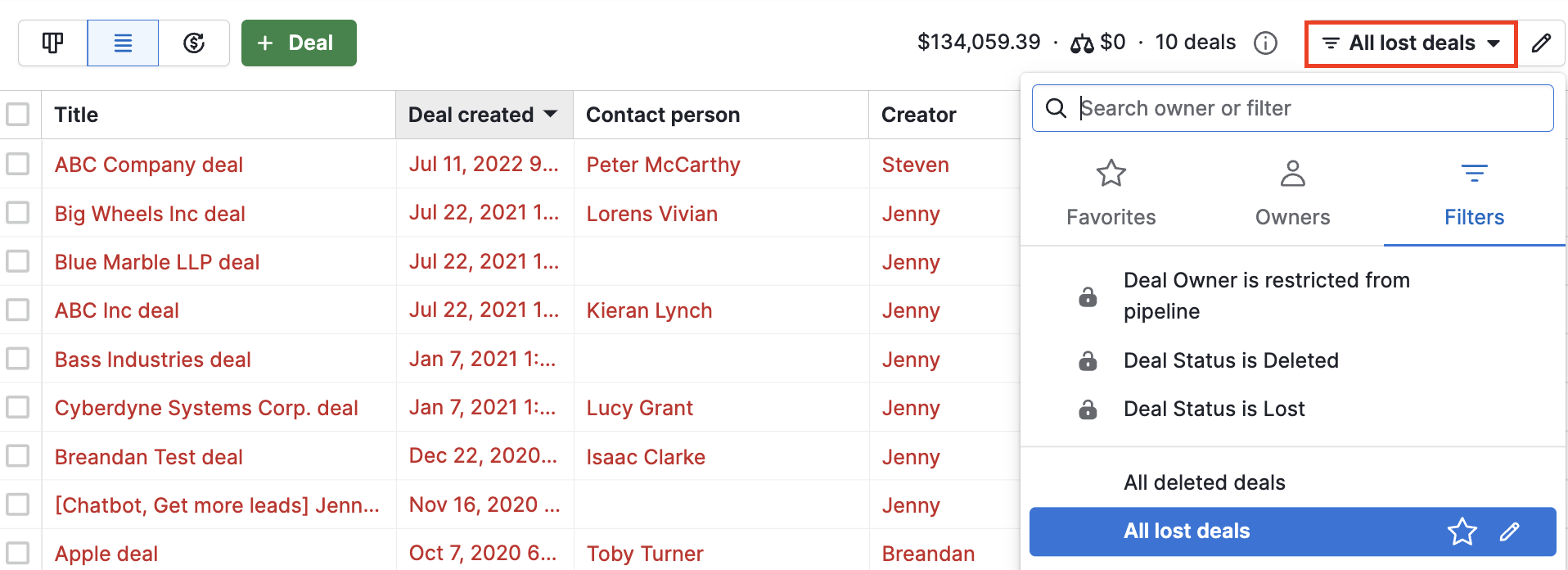
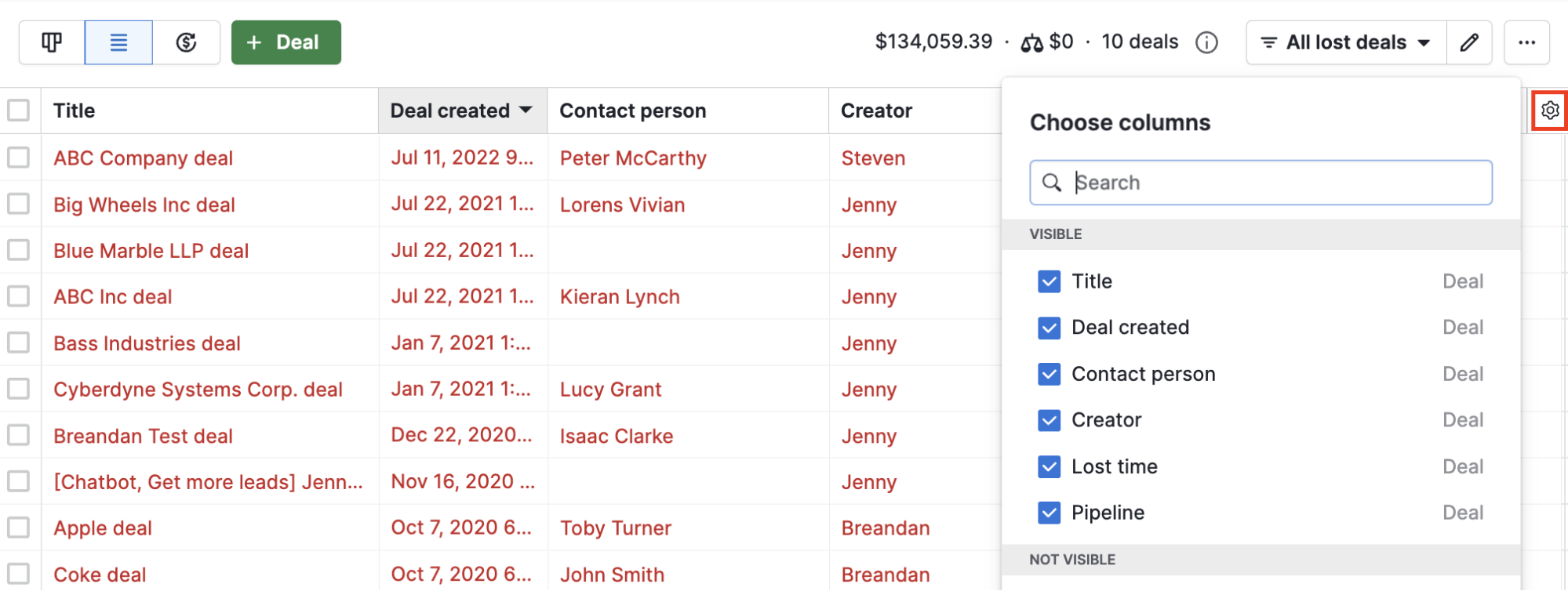
- Now, select the columns for which you want to export data.
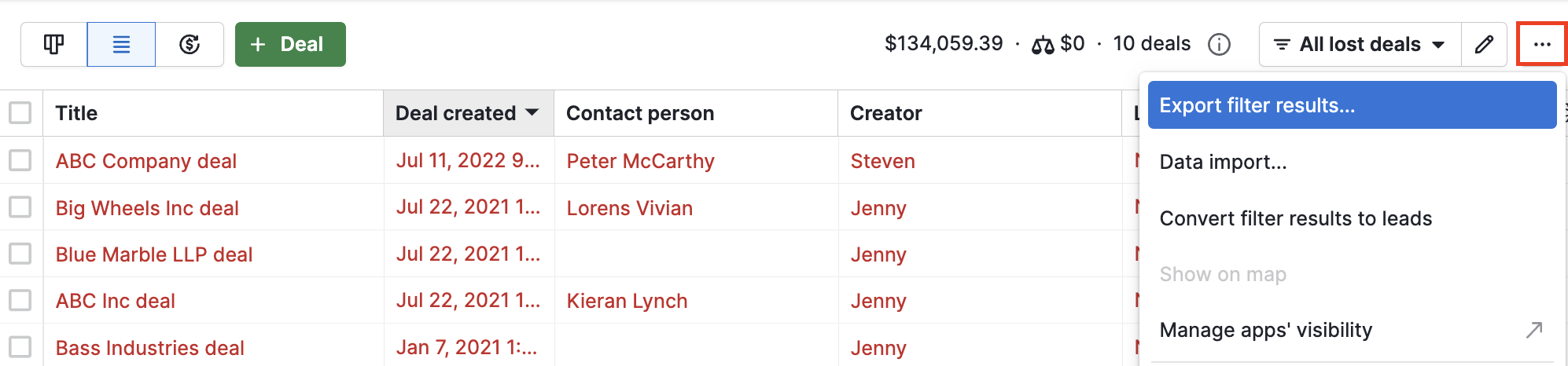
- Now, click on the “…” icon in the top-right corner. From the drop-down list, select the “Export filter results” option.
Now, Pipedrive will export all the information that fits the filter and columns that you have set.
Method 3: Exporting from the “Export data” option
In this case, you can export data about a whole module or apply filters on any module and then export only specific data.
- Navigate to the “Settings” option. Then, click on the “Export data” option.
- The export from settings will allow you to export data related to deals, organizations, people, activities, or notes individually.
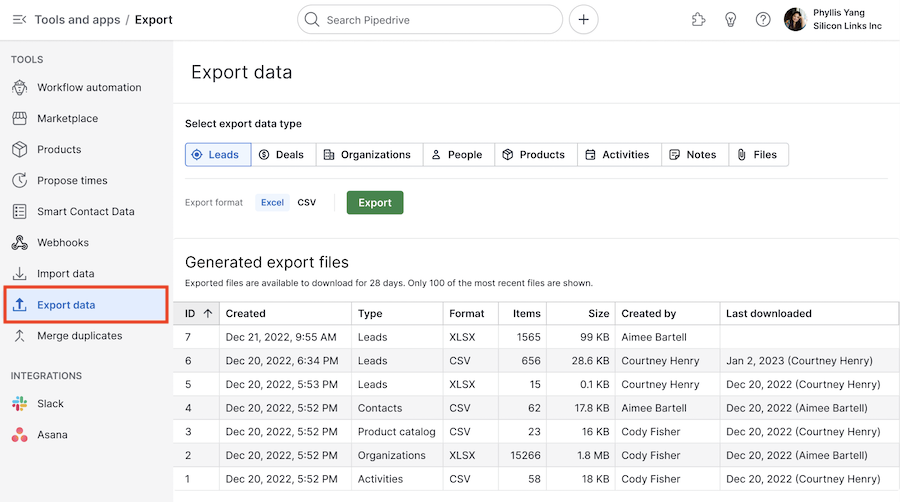
- Select the type of data you want to export. Then click on the “CSV” option.
- Your export file will then appear in the “Generated exports” list. Then click on the ”Available until” button to download the file.
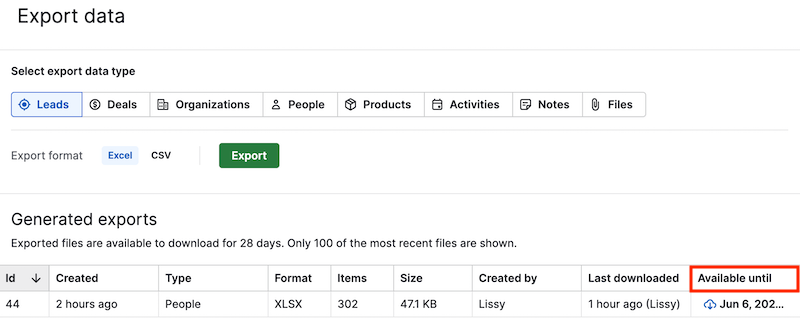
Step 2: Import CSV Files into Redshift
- Create a manifest file that contains the CSV data to be loaded. Upload this to S3 and preferably gzip the files.
- Once loaded onto S3, run the COPY command to pull the file from S3 and load it to the desired table. If you have used gzip, your code will be of the following structure:
COPY <schema-name>.<table-name> (<ordered-list-of-columns>) FROM '<manifest-file-s3-url>'
CREDENTIALS'aws_access_key_id=<key>;aws_secret_access_key=<secret-key>' GZIP MANIFEST;
- You also need to specify any column arrangements or row headers to be dismissed, as shown below:
COPY table_name (col1, col2, col3, col4)
FROM 's3://<your-bucket-name>/load/file_name.csv'
credentials 'aws_access_key_id=<Your-Access-Key-ID>;aws_secret_access_key=<Your-Secret-Access-Key>'
CSV;
-- Ignore the first line
COPY table_name (col1, col2, col3, col4)
FROM 's3://<your-bucket-name>/load/file_name.csv'
credentials 'aws_access_key_id=<Your-Access-Key-ID>;aws_secret_access_key=<Your-Secret-Access-Key>'
CSV
INGOREHEADER 1;
This process will successfully load your desired CSV datasets to Amazon Redshift in a pretty straightforward way. Also, Read Pipedrive to MySQL and Pipedrive PostgreSQL Integration.
Use Cases of Manual Method
The above 2-step guide replicates data from Pipedrive to Redshift effectively. It is optimal for the following scenarios:
- Less Amount of Data: This method is appropriate for you when the number of reports is less. Even the number of rows in each report is not huge.
- One-Time Data Replication: This method suits your requirements if your business teams need the data only once in a while.
- Limited Data Transformation Options: Manually transforming data in CSV files is difficult & time-consuming. Hence, it is ideal if the data in your spreadsheets is clean, standardized, and present in an analysis-ready form.
- Dedicated Personnel: If your organization has dedicated people who have to perform the manual downloading and uploading of CSV files, then accomplishing this task is not much of a headache.
- Coding Knowledge: For doing this replication, you need to have some knowledge of writing COPY commands in Redshift.
However, when the frequency of replicating data from Pipedrive increases, this process becomes highly monotonous. It adds to your misery when there is a need to transform the raw data every single time. With the increase in data sources, you would have to spend a significant portion of your engineering bandwidth creating new data connectors. Just imagine — building custom connectors for each source, transforming & processing the data, tracking the data flow individually, and fixing issues. Doesn’t it sound exhausting?

Method 2: Replicate Data from Pipedrive to Redshift Using Hevo Data
For instance, here’s how Hevo Data, a cloud-based ETL solution, makes data replication from Pipedrive to Redshift ridiculously easy:
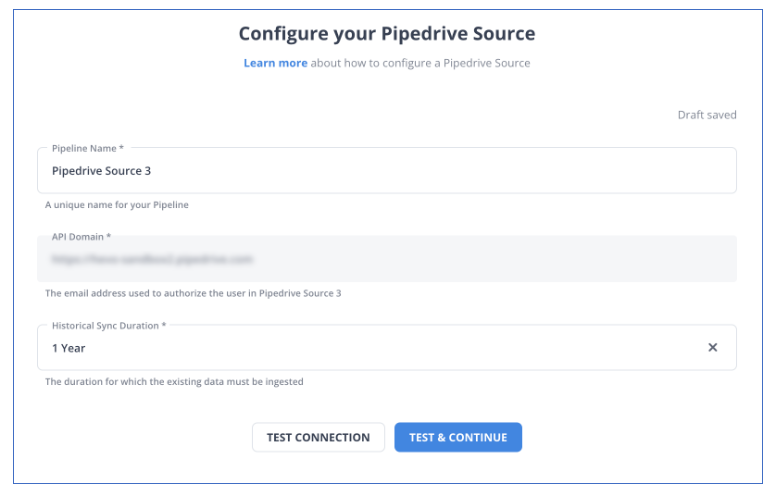
Step 1: Configure Pipedrive as your Source
- Fill in the required credentials required to configure Pipedrive as your source.
Step 2: Configure Redshift as your Destination
Now, you need to configure Redshift as the destination.
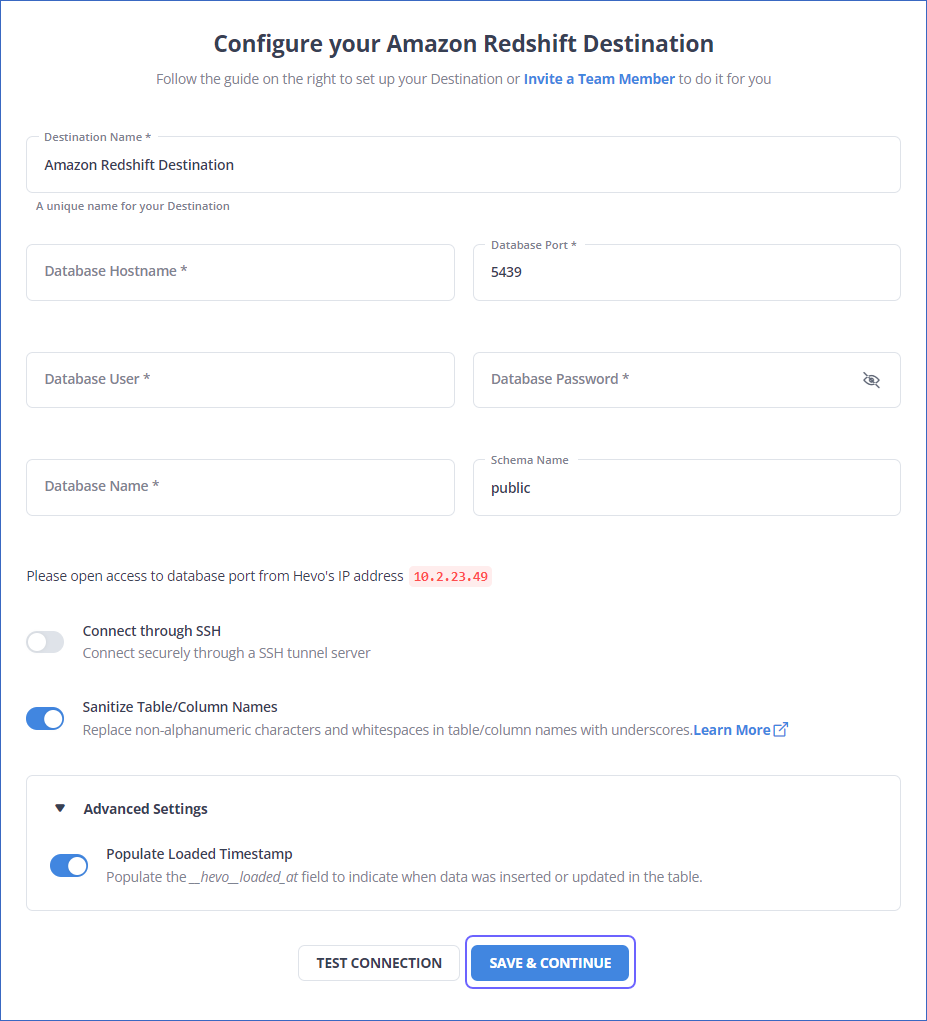
After implementing the two simple steps, Hevo will take care of building the pipeline for replicating data from Pipedrive to Redshift based on the inputs given by you while configuring the source and the destination.
You don’t need to worry about security and data loss. Hevo’s fault-tolerant architecture will stand as a solution to numerous problems. It will enrich your data and transform it into an analysis-ready form without having to write a single line of code.
Here’s what makes Hevo stands out from the rest:
- Fully Managed: You don’t need to dedicate time to building your pipelines. With Hevo’s dashboard, you can monitor all the processes in your pipeline, thus giving you complete control over it.
- Data Transformation: Hevo provides a simple interface to cleanse, modify, and transform your data through drag-and-drop features and Python scripts. It can accommodate multiple use cases with its pre-load and post-load transformation capabilities.
- Faster Insight Generation: Hevo offers near real-time data replication, giving you access to real-time insight generation and faster decision-making.
- Schema Management: With Hevo’s auto schema mapping feature, all your mappings will be automatically detected and managed to the destination schema.
- Scalable Infrastructure: With the increased number of sources and volume of data, Hevo can automatically scale horizontally, handling millions of records per minute with minimal latency.
- Transparent pricing: You can select your pricing plan based on your requirements. Different plans are clearly put together on its website, along with all the features it supports. You can adjust your credit limits and spend notifications for any increased data flow.
- Live Support: The support team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.
You can take our 14-day free trial to experience a better way to manage data pipelines.
Get started for Free with Hevo!Benefits of Connecting Pipedrive to Redshift
Here’s a little something for the data analyst on your team. We’ve mentioned a few core insights you could get by replicating data from Pipedrive to Redshift. Does your use case make the list?
- What is the Marketing Behavioural profile of the Product’s Top Users?
- What message would take a customer from one lifecycle stage to another?
- How likely is the lead to purchase a product?
- What was the survey’s Engagement Rate of App Users by channel?
Summing It Up
Exporting & uploading CSV files is the go-to solution for you when your data analysts require fresh data from Pipedrive only once in a while. However, with an increase in frequency, redundancy will also increase. However, to focus your time on doing productive tasks, you can prefer an automated solution. This automated solution would be able to accommodate your frequent data replication needs.
You don’t need to bite the bullet and spend months developing & maintaining custom data pipelines. You can make all the hassle go away in minutes by taking a ride with Hevo Data’s automated no-code data pipeline.
Hevo’s 150+ plug-and-play native integrations will help you replicate data smoothly from multiple tools to a destination of your choice. Its intuitive UI will help you smoothly navigate through its interface. And with its pre-load transformation capabilities, you don’t even need to worry about manually finding errors and cleaning & standardizing them.
Skeptical? Why not try Hevo for free and make the decision yourself? Using Hevo’s 14-day free trial feature, you can build a data pipeline from Pipedrive to Redshift and try out the experience.
Here’s a short video that will guide you through the process of building a data pipeline with Hevo.
We hope you have found the appropriate answer to the query you were searching for. Happy to help!
FAQs
1. What does Pipedrive integrate with?
Pipedrive integrates with a wide variety of tools and platforms to enhance its CRM capabilities.
2. Does Pipedrive integrate with constant contact?
Yes, Pipedrive can integrate with Constant Contact using third-party tools to sync contacts or automate email campaigns.
3. What data can be transferred from Pipedrive to Redshift?
You can transfer various data types, including leads, deals, activities, contacts, and sales reports, from Pipedrive to Redshift, allowing for comprehensive analysis and reporting.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



