




So, you’re a Salesforce user, right? It’s always a pleasure talking to someone who gives utmost priority to the customer experience and behavior. Being focused on optimizing marketing & sales channels based on customer engagement is what makes you a great player.
Salesforce has consolidated dashboards based on multiple reports of customer engagement, behavior, and support data. But, there would be times when this data needs to be integrated with that of other functional teams. That’s where you come in. You take the responsibility of replicating data from Salesforce to a centralized repository so that analysts and key stakeholders can make super-fast business-critical decisions.
Well, you’ve landed in the right place! We’ve prepared a simple and straightforward guide to help you replicate data from Salesforce to Databricks. Read the 2 simple methods to understand the replication process quickly.
Table of Contents
Overview of Salesforce

- For plenty of Entrepreneurs, Business Owners, and Corporations, Salesforce is the king of CRM. Salesforce is the most popular and robust cloud-based CRM software designed to support organizations in managing their sales and marketing data.
- Salesforce will help you accomplish several marketing goals by storing and keeping track of all your customer data, contact data, and marketing leads. You can also generate Sales Forecast Reports with Salesforce to convert your leads.
- Salesforce also supports Email Integration with applications like Microsoft Outlook, Gmail, etc. They really have just about everything that you could possibly think of when it comes to operations in a business and managing their customers.
- Salesforce follows a subscription-based model and offers a variety of pricing options, ranging from $25 to about $300 per user every month.
Are you looking for ways to connect your Salesforce with cloud storage tools like Amazon S3? Hevo has helped customers across 45+ countries migrate data seamlessly. Hevo streamlines the process of migrating data by offering:
- Seamlessly data transfer between Salesforce, Amazon S3, and 150+ other sources.
- Risk management and security framework for cloud-based systems with SOC2 Compliance.
- In-Built transformations like drag-and-drop to analyze your CRM data.
Don’t just take our word for it—try Hevo and experience why industry leaders like Whatfix say,” We’re extremely happy to have Hevo on our side.”
Key Features of Salesforce
Let’s look at some of the key features of Salesforce responsible for its immense popularity:
- Accounting Management: Salesforce gives companies a complete picture of their customers. At any moment, customers can access Activity Logs, Customer Conversations, Contacts, Internal Account Discussions, and other data.
- Lead Management: Salesforce helps firms track leads and optimize campaign performance across all marketing platforms. As a result, they will be more equipped to make decisions about how and where to spend their marketing budget.
- Analytics and Forecasting: Salesforce comprises customizable dashboards that display key performance metrics and reporting capabilities for your business. These analytics can assist you in making more informed business decisions.
You can think of combining your Salesforce data with data coming from various other sources in your Data Warehouse to get valuable insights for your business.
Overview of Databricks

- Databricks is a popular Cloud-based Data Engineering platform developed by the creators of Apache Spark.
- It deals with large amounts of data and allows you to easily extract valuable insights from it. With the main focus on Big Data and Analytics, it also assists you in the development of AI (Artificial Intelligence) and ML (Machine Learning) solutions.
- Machine Learning libraries such as Tensorflow, Pytorch, and others can be used for training and developing Machine Learning models.
Key Features of Databricks
Databricks comprises a variety of features that help users work more efficiently on the Machine Learning Lifecycle. Some of the key features of Databricks include:
- Interactive Notebooks: Databricks’ interactive notebooks provide users with a variety of languages (such as Python, Scala, R, and SQL) and tools for accessing, analyzing, and extracting new insights.
- Integrations: Databricks can be easily integrated with a variety of tools and IDEs (Integrated Development Environment), including PyCharm, IntelliJ, Visual Studio Code, etc., to make Data Pipelining more structured.
- Delta Lake: Databricks houses an open-source Transactional Storage layer that can be used for the whole data lifecycle. This layer brings data scalability and reliability to your existing Data Lake.
Replicate Data from Salesforce to Databricks
To replicate data from Salesforce to Databricks, you can do either of the following:
Learn about Salesforce Connect.
Method 1: Replicate Data from Salesforce to Databricks Using an Automated ETL Tool
Here’s how Hevo Data, a cloud-based ETL tool, makes Salesforce to Databricks data replication ridiculously easy:
Step 1.1: Configure Salesforce as Your Source

Step 1.2: Configure Databricks as Your Destination

All Done to Setup Your ETL Pipeline
After implementing the 2 simple steps, Hevo Data will build the pipeline for replicating data from Salesforce to Databricks based on your inputs while configuring the source and the destination.
The pipeline will automatically replicate new and updated data from Salesforce to Databricks every 15 mins (by default). However, you can also adjust the data replication frequency as per your requirements.
Data Pipeline Frequency
| Default Pipeline Frequency | Minimum Pipeline Frequency | Maximum Pipeline Frequency | Custom Frequency Range (Hrs) |
| 15 Mins | 15 Mins | 24 Hrs | 1-24 |
For in-depth knowledge of how a pipeline is built & managed in Hevo Data, you can also visit the official documentation for Salesforce as a source and Databricks as a destination.
You don’t need to worry about security and data loss. Hevo’s fault-tolerant architecture will stand as a solution to numerous problems. It will enrich your data and transform it into an analysis-ready form without having to write a single line of code.
Salient Features of Hevo
- Data Transformation: Hevo provides a simple interface to cleanse, modify, and transform your data through drag-and-drop features and Python scripts. It can accommodate multiple use cases with its pre-load and post-load transformation capabilities.
- Schema Management: With Hevo’s auto schema mapping feature, all your mappings will be automatically detected and managed to the destination schema.
- Scalable Infrastructure: With the increase in the number of sources and volume of data, Hevo can automatically scale horizontally, handling millions of records per minute with minimal latency.
- Transparent pricing: You can select your pricing plan based on your requirements. You can adjust your credit limits and spend notifications for increased data flow.
- Live Support: The support team is available round the clock to extend exceptional customer support through chat, email, and support calls.

Method 2: Replicate Data from Salesforce to Databricks Using CSV Files
You can carry forward with the following steps to understand the replication process of replicating data from Salesforce to Databricks in CSV format:
Step 2.1: Export CSV Files From Salesforce Using the Data Loader Export Wizard
- Log in to your Salesforce application. Then, go to setup.
- Under Administer section, select the “Data Management”, following which click on the “Data Loader” option.
- Choose the appropriate version for your computer and download the file. Then, download Data Loader for Windows or Mac.
- Double-click the saved file to install it on your PC.
- Launch the Salesforce Data Loader export wizard. Then click on the “Export” button.
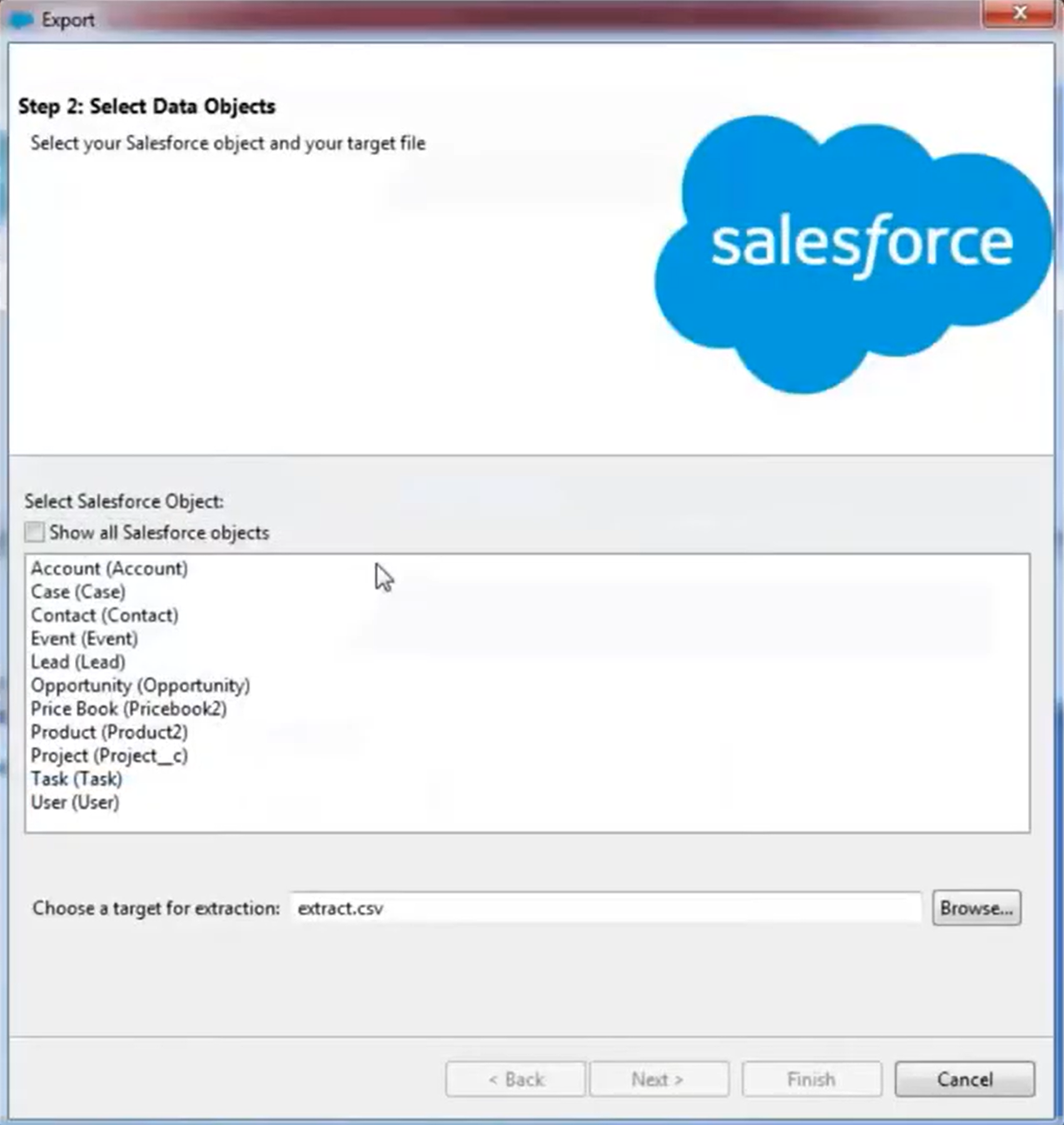
- Log in to Salesforce using your credentials. Then click on the “Next” button.
- Select the object you want to export. For example, you can select the Leads object. To view an expanded view of all the objects available for export, select the “Show all objects” button.
- Create the CSV file to export the data to and click the “Next” button.
- Create a SOQL (Salesforce Object Query Language) query for the data export. For example, for Lead data, you can select First Name, Last Name, Address, Email, Mobile, City, Lead Source, Lead Status, Campaign, Company, and Title in the query fields, and click Finish. As you follow the next steps, the CSV viewer displays all the lead names and the corresponding fields.
Step 2.2: Import CSV Files into Databricks
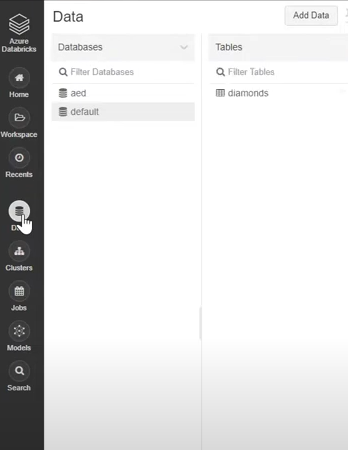
- In the Databricks UI, go to the side navigation bar. Click on the “Data” option.
- Now, you need to click on the “Create Table” option.
- Then drag the required CSV files to the drop zone. Otherwise, you can browse the files in your local system and then upload them.
Once the CSV files are uploaded, your file path will look like: /FileStore/tables/<fileName>-<integer>.<fileType>
Step 2.3: Modify & Access the Data
- Click on the “Create Table with UI” button.
- The data now gets uploaded to Databricks. You can access the data via the Import & Explore Data section on the landing page.
- To modify the data, select a cluster and click on the “Preview Table” option.
- Then, change the attributes accordingly and select the “Create Table” option.
With this 3-step approach, you can easily replicate data from Salesforce to Databricks using CSV files.
Advantages of Connecting Salesforce to Databricks Manually
- Low-frequency Data Replication: When your marketing team needs the Salesforce data only once in a long period, i.e., monthly, quarterly, yearly, or just once.
- Limited Data Transformation Options: Manually transforming data in CSV files is difficult & time-consuming if this needs to be done on a regular basis. Hence, it is ideal if the data in your spreadsheets is clean, standardized, and present in an analysis-ready form.
- Dedicated Personnel: If your organization has dedicated people who have to perform the manual downloading and uploading of CSV files, then accomplishing this task is not much of a headache.
Limitations of Connecting Salesforce to Databricks Manually
- Just imagine — building custom connectors for each source, transforming & processing the data, tracking the data flow individually, and fixing issues.
- When the frequency of replicating data from Salesforce increases, this process becomes highly monotonous.
- It adds to your misery when you have to transform the raw data every single time. With the increase in data sources, you would have to spend a significant portion of your engineering bandwidth creating new data connectors.
What Can You Achieve by Migrating Your Data from Salesforce to Databricks?
Here’s a little something for the data analyst on your team. We’ve mentioned a few core insights you could get by replicating data from Salesforce to Databricks. Does your use case make the list?
- Customers acquired from which channel have the maximum satisfaction ratings?
- How does customer SCR (Sales Close Ratio) vary by Marketing campaign?
- How many orders were completed from a particular Geography?
- How likely is the lead to purchase a product?
- What is the Marketing Behavioural profile of the Product’s Top Users?
You can also learn more about:
- Salesforce Marketing Cloud to Databricks
- Mailchimp to Databricks
- Marketo to Databricks
- What is Databricks
Summing It Up
- Exporting and importing CSV files would be the smoothest process when your sales, support & marketing teams require data from Salesforce only once in a while.
- But what if the sales, support & marketing teams request data from multiple sources at a high frequency? Would you carry on with this method of manually importing & exporting CSV files from every other source?
- In this situation, wouldn’t you rather focus on something more productive? You can stop spending so much time being a ‘Big Data Plumber’ by using a custom ETL solution instead.
- A custom ETL solution becomes necessary for real-time data demands such as monitoring campaign performance or viewing the recent user interaction with your product or marketing channel.
You can free your engineering bandwidth from these repetitive & resource-intensive tasks by selecting Hevo Data’s 150+ plug-and-play integrations (including 60+ free sources).
Take Hevo’s 14-day free trial to experience a better way to manage your data pipelines. You can also check out the unbeatable pricing, which will help you choose the right plan for your business needs.
Frequently Asked Questions
1. Does Databricks have a Salesforce connector?
Yes, Databricks provides native connectors and partner integrations to connect with
Salesforce.
2. Does Databricks compete with Salesforce?
No, Databricks focuses on data processing and analytics, while Salesforce specializes in CRM solutions.
3. How do I transfer data to Databricks?
You can transfer data to Databricks using multiple methods, such as CSV imports or
automated tools like Hevo for seamless integration.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



