




As a data engineer, you hold all the cards to make data easily accessible to your business teams. Your team just requested a Square to Snowflake connection as a priority. We know you don’t want to keep your data scientists and business analysts waiting to get critical business insights. If this is a one-time thing, exporting data with the help of CSV files is helpful. Or, you can hunt for a no-code tool that fully automates & manages data integration for you while you focus on your core objectives.
Well, look no further. This article provides a step-by-step guide to connecting Square to Snowflake effectively and quickly delivering data to your finance team.
Method 1: Replicate data from Square to Snowflake using CSV
This involves using CSV files to import data into Snowflake. It has two steps and can be time-consuming compared to the second method.
Method 2: Automate the Data Replication process using a No-Code Tool
This can be achieved by using an automated pipeline. Hevo currently does not support Square as a source, but other tools available on the market can help.
Discover why the global experiences and transportation leader Hornblower chose Hevo!
Get Started with Hevo for FreeTable of Contents
Method To Replicate Data from Square to Snowflake Using CSV
To start replicating data from Square to Snowflake, firstly, you need to export data as CSV files from Square, then import the CSV files into Snowflake and modify your data according to your needs.
- Step 1: You must navigate to Actions > Export Library > Confirm Export by visiting Items section in the Square dashboard. You can select between xlsx and CSV files. Based on the file you select, it will be downloaded to your local system. The important factor to note is that the values will be in text format, you will need to change the required fields into number fields.
- Step 2: You can upload CSV files to Snowflake using the Data Load Wizard present in the Snowflake web interface. You can quickly load data into Snowflake by selecting the tables you want to load and clicking the Import button in the Snowflake Web UI. By deleting all staging files as soon as they are loaded into the data warehouse, the staging and data-loading tasks are clubbed into one action.
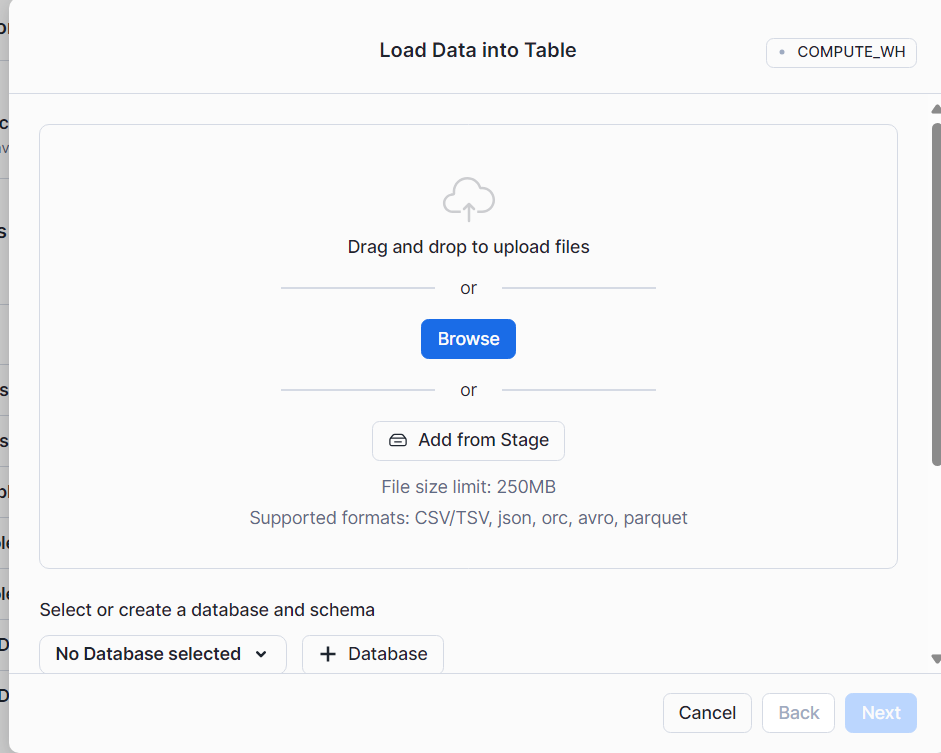
Learn more about loading CSV files through the web interface and how to load data into Snowflake.
This 2-step process using CSV is a great way to replicate data from Square to Snowflake effectively. It is optimal for the following scenarios:
- One-Time Data Replication: When your finance team needs the Square data only once in a long period.
- No Data Transformation Required: If there is a negligible need for data transformation and your data is standardized, then this method is ideal.
- Small Amount of Data: Since the amount of data is small, the accuracy of data replication would be high, making this method a good fit.
In the following scenarios, using CSV might not be a great fit:
- Data Mapping: Only basic data can be moved. Complex configurations cannot take place. There is no distinction between text, numeric values, null, and quoted values.
- Time Consuming: If you plan to export your data frequently, there may be better choices than the CSV method since it takes a significant amount of time to replicate the data using CSV files.
Frequent data replication from Square becomes monotonous, especially when you must repeatedly transform raw data. As data sources grow, engineering time is consumed building custom connectors, processing data, tracking flows, and fixing issues—an exhausting process.
How about you focus on more productive tasks than repeatedly writing custom ETL scripts? This sounds good, right?
In these cases, you can…
Opt for automated data pipelines. Such data pipelines are easy to use, even for non-technical people, and efficient. All you have to do is enter the credentials for your source and destination, and that’s it! Once connected, the pipeline will start loading data to your destination.
Hevo is an automated data pipeline. Here are the benefits of leveraging Hevo:
- Hevo has connectors for 150+ sources(60+ free) and can connect to significant data warehouses and databases, providing a seamless experience during data migration.
- With a user-friendly UI, tasks like setting up connections and providing credentials are simple.
- It also has the feature of auto-mapping schema, saving you time instead of doing that manually.
Hevo does not support Square as a source now, but you can look at the exhaustive list of sources Hevo provides to help you with your integrations.

What Can You Achieve by Migrating Your Data from Square to Snowflake?
Here’s a little something for the data analyst of your team. We’ve mentioned a few core insights you could get by replicating data from Square to Snowflake. Does your use case make the list?
- Which campaigns have the most support costs involved?
- For which geographies are marketing expenses the most?
- Which campaign is more profitable?
- What does your overall business cash flow look like?
- Which sales channel provides the highest purchase orders?
Summing It Up
CSV files is the right path for you when your team needs data from Square once in a while. However, an ETL solution becomes necessary if there are rapid changes in the source and frequent data replication needs to be done to meet the data demands of your product or finance channel. You can free your engineering bandwidth from these repetitive & resource-intensive tasks by selecting Hevo’s 150+ plug-and-play integrations.
Saving countless hours of manual data cleaning & standardizing, Hevo’s pre-load data transformations get it done in minutes via a simple drag and drop interface or your custom Python scripts.
Want to take Hevo for a ride? Explore our 14-day free trial and simplify your data integration process. Check out the pricing details to understand which plan fulfills all your business needs.
Share your experience of replicating data from Square to Snowflake! Let us know in the comments section below!
FAQs
1) Does Square use Snowflake?
Square designs and build tools that helps merchants start, run and empower their business. Together with Snowflake, it helps businesses run and avoid risks.
2) Is Snowflake a database or an ETL tool?
Snowflake is a SaaS data warehouse, not an ETL tool. It is cloud-based and is used to store and query large datasets.
3) What is the difference between a data warehouse and Snowflake?
Snowflake differentiates compute and storage, charging separately for both, which is significantly different from traditional data warehouses.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link










