

Snowflake is a fully managed SaaS (software as a service) that offers a single platform for data warehousing, data lakes, data engineering, data science, data application development, and secure sharing and consumption of real-time / shared data. It was first released in 2012. To meet the demanding needs of growing companies, Snowflake includes out-of-the-box capabilities such as storage and compute separation, on-the-fly scaling computation, data sharing, data cloning, and third-party tool support.
Apache Airflow is an open-source workflow authoring, scheduling, and monitoring application. It’s one of the most reliable systems for orchestrating processes or pipelines that Data Engineers employ. You can quickly see the dependencies, progress, logs, code, trigger tasks, and success status of your data pipelines.
In this blog post, you will learn about Airflow and how to use the Airflow Snowflake combination for efficient ETL.
Table of Contents
What is Airflow?

Apache Airflow is an open-source workflow automation and scheduling platform that programmatically authors, schedules, and monitors workflows. Organizations use Airflow to orchestrate complex computational workflows, create data processing pipelines, and perform ETL processes.
Airflow uses DAG (Directed Acyclic Graph) to construct the workflow, and each DAG contains nodes and connectors. Nodes connect to other nodes via connectors to generate a dependency tree.
Key Features of Airflow
- Dynamic Integration: Airflow uses Python as the backend programming language to generate dynamic pipelines. Several operators, hooks, and connectors are available that create DAG and ties them to create workflows.
- Extensible: Airflow is an open-source platform, and so it allows users to define their custom operators, executors, and hooks. You can also extend the libraries so that it fits the level of abstraction that suits your environment.
- Elegant User Interface: Airflow uses Jinja templates to create pipelines, and hence the pipelines are lean and explicit. Parameterizing your scripts is a straightforward process in Airflow.
- Scalable: Airflow is designed to scale up to infinity. You can define as many dependent workflows as you want. Airflow creates a message queue to orchestrate an arbitrary number of workers.
What is Snowflake?

Snowflake is completely cloud-oriented and truly a SaaS (Software-as-a-Service) offering, that is used to load, transform, and report massive data volume. Snowflake uses AWS, Azure, or GCP to host its services and provides an intuitive user interface that allows customers to perform analytics. It uses SQL to query the data that runs on its virtual machines.
With Snowflake, you can seamlessly run your data solution across multiple regions and Clouds for a consistent experience. Snowflake makes this possible by abstracting the complexity of underlying cloud infrastructures. Check out the Best Snowflake BI and Reporting Tools in 2024.
Key Features of Snowflake
- Scalable: Snowflake provides a secure, scalable architecture that can spin up an unlimited number of independent virtual warehouses in a few minutes. You can execute several parallel jobs without worrying about performance and memory management.
- Pay Per Use Model: Snowflake is available as pay per usage; i.e., you only have to pay for the time you use the services offered by Snowflake. You can shut down the warehouses once the execution gets completed, to save costs.
- High Processing Speed: Each Virtual Warehouse in Snowflake is associated with the MPP cluster (Massive Parallel Processing), which performs the parallel execution of a job without degrading other clusters’ performance.
- Separate Storage and Compute Layer: Snowflake uses different storage and computes layers that can scale up or down without affecting the other.
- Disaster Recovery: In Snowflake, data is replicated three times (by default) across the availability zones and regions, hence providing a complete fail-safe and fault-tolerant system.
A fully managed No-code Data Pipeline platform like Hevo Data helps you integrate data from 150+ Data Sources (including 60+ Free Data Sources) to a destination of your choice, such as Snowflake, in real-time in an effortless manner. Check out why Hevo is the Best:
- Live Support: The Hevo team is available round the clock to extend exceptional customer support through chat, E-Mail, and support calls.
- Schema Management: Hevo takes away the tedious task of schema management & automatically detects the schema of incoming data and maps it to the destination schema.
- Incremental Data Load: Hevo allows the transfer of data that has been modified in real-time. This ensures efficient utilization of bandwidth on both ends.
Prerequisites
- Use Python 3.6 or later and have a working knowledge of Python.
- Amazon AWS account with read/write access to buckets.
- Snowflake account, with access to perform read and write.
- Access to Apache Airflow 1.10 and later, with dependencies installed.
- Basic understanding of workflows and programming language.
Setting Up Airflow Snowflake Integration
Here is the outline that you’ll be covering while traversing ahead in Airflow Snowflake Integration:
Step 1: Connection to Snowflake
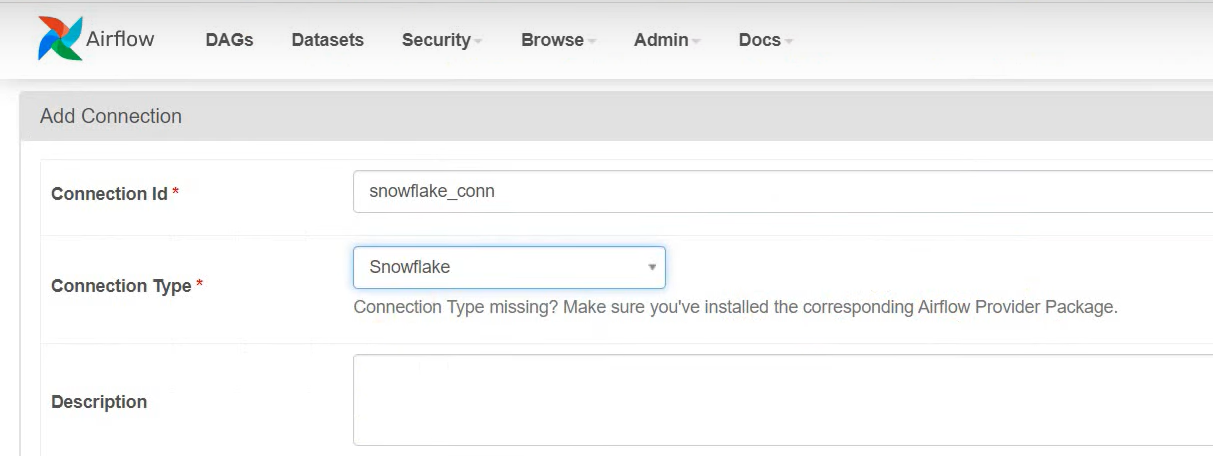
- On the Admin page of Apache Airflow, click on Connections, and on the dialog box, fill in the details as shown below. (Assuming Snowflake uses AWS cloud as its cloud provider).
Conn Id: <CONNECTION_ID>
Conn Type: Snowflake
Host: <YOUR_SNOWFLAKE_HOSTNAME>
Schema: <YOUR_SNOWFLAKE_SCHEMA>
Login: <YOUR_SNOWFLAKE_USERNAME>
Password: <YOUR_SNOWFLAKE_PASSWORD>
Extra: {
"account": <YOUR_SNOWFLAKE_ACCOUNT_NAME>,
"warehouse": <YOUR_SNOWFLAKE_WAREHOUSE_NAME>,
"database": <YOUR_SNOWFLAKE_DB_NAME>,
"region": <YOUR_SNOWFLAKE_HOSTED_REGION>
}
Step 2: Creation of DAG
DAG stands for Directed Acyclic Graph, and it represents the collection of tasks that you want to run. Each task runs on different workers at different points in time. DAG contains several operators that perform the tasks on the worker, like PythonOperator to perform Python tasks, BashOperator to perform Bash tasks, and so on.
To create a DAG for Airflow Snowflake Integration that will perform operations on Snowflake, you’ll need to use the Snowflake operator and Snowflake hooks provided by Airflow:
- Snowflake Operators are used when you want to perform a task without expecting output. These operators can execute – create, insert, merge, update, delete, copy into, and truncate operations as output result is not required in such cases.
- Snowflake Hook is used when you expect a result from a query. Hooks are mostly used with select queries as they extract Snowflake results and pass them to Python for further processing.
Let’s create a sample DAG to automate the tasks in Airflow Snowflake Integration:
- To create a DAG for Airflow Snowflake Integration, you need to organize Python imports by using the following code.
import logging
from datetime import datetime, timedelta
import airflow
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from airflow.contrib.hooks.snowflake_hook import SnowflakeHook
from airflow.contrib.operators.snowflake_operator import SnowflakeOperator- Initializing a DAG object for Airflow Snowflake Integration is very simple, as it requires a DAG id and the default parameters with schedule intervals. There are many optional parameters provided by Airflow for additional functionalities. You can refer to the complete list of parameters here.
dag = DAG(
dag_id="snowflake_connector3", default_args=args, schedule_interval=None
)- Create functions in Python to create tables, insert some records, and get row count from Snowflake for Airflow Snowflake Integration:
query1 = [
"""select 1;""",
"""show tables in database abcd_db;""",
]
def count1(**context):
dwh_hook = SnowflakeHook(snowflake_conn_id="snowflake_conn")
result = dwh_hook.get_first("select count(*) from abcd_db.public.test3")
logging.info("Number of rows in `abcd_db.public.test3` - %s", result[0])- Create DAG with SnowflakeOperator and PythonOperator to incorporate the functions created above for Airflow Snowflake Integration.
with dag:
query1_exec = SnowflakeOperator(
task_id="snowfalke_task1",
sql=query1,
snowflake_conn_id="snowflake_conn",
)
count_query = PythonOperator(task_id="count_query", python_callable=count1)
query1_exec >> count_query- Now that you have created the task, you need to connect them with the use of a (>>) operator to create a pipeline for Airflow Snowflake Integration.
create_insert >> get_countAfter completing the above script, you need to upload the script into the Airflow home for the Airflow Snowflake Integration. After the refresh, the DAG will appear on the user interface and will look as shown:
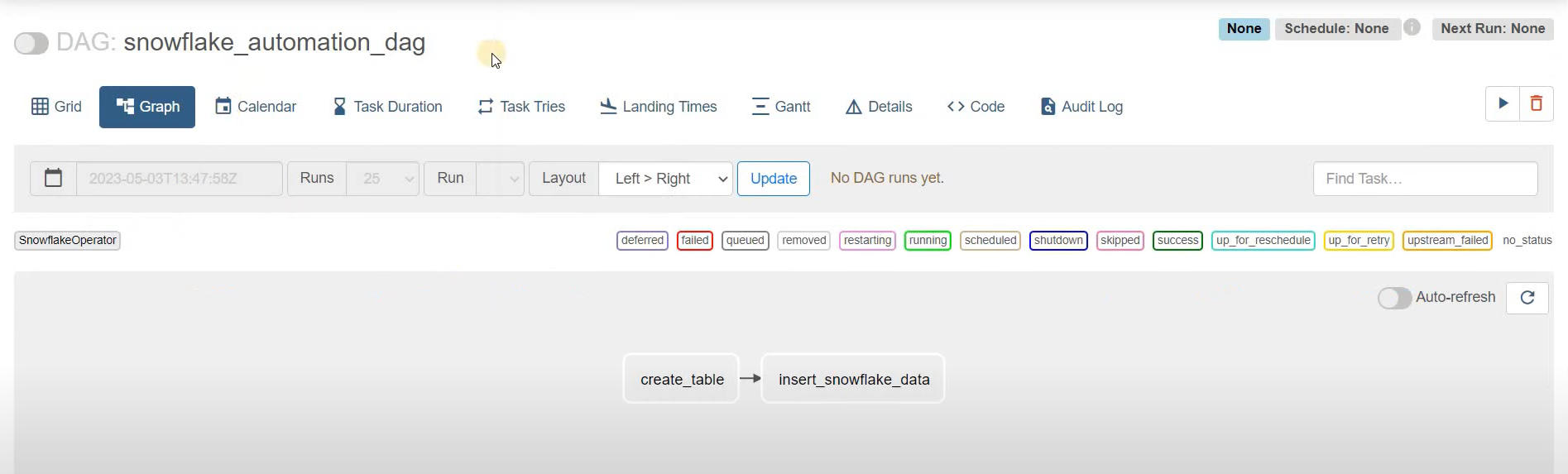



Example of DAG for Airflow Snowflake
Below is the complete example of the DAG for the Airflow Snowflake Integration:
import logging
import airflow
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from airflow.contrib.hooks.snowflake_hook import SnowflakeHook
from airflow.contrib.operators.snowflake_operator import SnowflakeOperator
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
args = {"owner": "Airflow", "start_date": airflow.utils.dates.days_ago(2)}
dag = DAG(
dag_id="snowflake_automation", default_args=args, schedule_interval=None
)
snowflake_query = [
"""create table public.test_employee (id number, name string);""",
"""insert into public.test_employee values(1, “Sam”),(2, “Andy”),(3, “Gill”);""",
]
def get_row_count(**context):
dwh_hook = SnowflakeHook(snowflake_conn_id="snowflake_conn")
result = dwh_hook.get_first("select count(*) from public.test_employee")
logging.info("Number of rows in `public.test_employee` - %s", result[0])
with dag:
create_insert = SnowflakeOperator(
task_id="snowfalke_create",
sql=snowflake_query ,
snowflake_conn_id="snowflake_conn",
)
get_count = PythonOperator(task_id="get_count", python_callable=get_row_count)
create_insert >> get_countIn the above DAG, the Snowflake operator creates a table and inserts data into the table. The Snowflake hook is then used to query the table created by the operator and return the result to the Python operator, which logs the result to the console completing the Airflow Snowflake Integration.
How is Airflow Snowflake Connection Beneficial?
Here are a few reasons why Airflow Snowflake Integration is beneficial:
- User-friendly monitoring interface: Airflow has a monitoring and management interface that allows you to get a rapid overview of the status of various tasks as well as trigger and clear charges or DAGs runs. Snowflake databases are extremely user-friendly, allowing users to organize data in any way they see fit. Snowflake is built to be a highly responsive platform that runs at peak performance without the need for regular monitoring by an expert.
- Airflow pipelines are configuration-as-code (Python) and hence allow for dynamic pipeline generation. This makes it possible to write code that generates pipeline instances on the fly. We do not process data in a linear or static manner.
- Airflow has a variety of operators set up to run code, so we can automate our queries or Python code. Airflow is written in Python and provides an operator for almost every database. It has a PythonOperator that makes migrating Python code to production a breeze.
- Maximum Server Capacity: While traditional data warehouses require considerable investments in servers and other infrastructure, Snowflake provides significantly more capacity without the need to upgrade hardware. Everything is cloud-based with Snowflake, so you may deploy it on a small scale that can later be scaled up or down depending on your company’s needs.
- Many firms deal with sensitive data, which must be securely protected. Snowflake’s backend has IP whitelisting, which restricts data access to only trusted, authorized users. Snowflake provides high-quality data security thanks to two-factor authentication, SSO authentication, and AES 256 encryption, as well as the fact that it encrypts data in transit and at rest.
- Recovering from a disaster: Some businesses are concerned about not having physical access to the servers where their data is housed in the case of a disaster. Snowflake databases have disaster recovery measures in place, ensuring that your data is replicated and accessible across several data centers in the event of a disaster.
Conclusion
In this blog, you have learned about Airflow, Snowflake, and how to use Airflow Snowflake combinations for efficient ETL. Airflow with Snowflake helps us automate the data transfer by forming an automated ETL.
This article also discusses the different features, benefits, and use cases of Airflow and Snowflake before diving into the steps involved in establishing a connection between Airflow and Snowflake.
However, the manual approaches to connecting Airflow to Snowflake can be complex and time-consuming. Moreover, they are error-prone, and a significant amount of technical expertise is required to implement them successfully.
Hevo Data, with its strong integration with 150+ Sources & BI tools, allows you to not only export data from sources & load data in the destinations such as Snowflake, but also transform & enrich your data, & make it analysis-ready so that you can focus only on your key business needs and perform insightful analysis using BI tools. In short, Hevo can help you store your data securely in Snowflake.
Give Hevo Data a try and Sign Up for a 14-day free trial today. Hevo offers plans & pricing for different use cases and business needs!
FAQs
1. What is DBT vs Airflow?
DBT (Data Build Tool) focuses on transforming data within a database using SQL, while Airflow is an orchestration tool that manages, schedules, and monitors complex workflows, including data transformations, across various systems.
2. How to run the Snowflake query in Airflow DAG?
You can run a Snowflake query in an Airflow DAG using the SnowflakeOperator, which connects to Snowflake and executes the SQL query specified in your DAG’s task.
3. What is the best database for Airflow?
PostgreSQL and MySQL are commonly recommended databases for Airflow’s metadata storage, as they offer strong performance, reliability, and compatibility with Airflow’s backend requirements.




