

Taboola is a New York City-based public advertising firm. It displays advertisements at the bottom of many online news articles, such as “Around the Web” and “Recommended For You” boxes.
AWS Redshift is an Amazon Web Services data warehouse service. It’s commonly used for large-scale data storage and analysis, as well as large database migrations.
This article talks about the ways to load data instantly from Taboola to Redshift. It also gives a brief introduction to Redshift and Taboola.
Method 1: Using Hevo Data to Set Up Taboola to Redshift ETL
Hevo Data, an Automated Data Pipeline, provides you with a hassle-free solution to connect Taboola to Redshift within minutes with an easy-to-use no-code interface. Hevo is fully managed and completely automates the process of loading data from Taboola to Redshift and enriching the data and transforming it into an analysis-ready form without having to write a single line of code.
Method 2: Using Custom Code to Move Data from Taboola to Redshift
This method would be time-consuming and somewhat tedious to implement. Users will have to write custom codes to enable two processes, streaming data from Taboola to Redshift. This method is suitable for users with a technical background.
Table of Contents
Taboola to Redshift ETL Set Up
- Method 1: Using Hevo Data to Set Up Taboola to Redshift ETL
- Method 2: Using Custom Code to Move Data from Taboola to Redshift
Method 1: Using Hevo Data to Set Up Taboola to Redshift ETL
Hevo provides an Automated No-code Data Pipeline that helps you move your Taboola to Redshift. Hevo is fully-managed and completely automates the process of not only loading data from your 150+ data sources(including 60+ free sources)but also enriching the data and transforming it into an analysis-ready form without having to write a single line of code. Its fault-tolerant architecture ensures that the data is handled in a secure, consistent manner with zero data loss.
Using Hevo Data, you can connect Taboola to Redshift in the following 2 steps:
Step 1: Configure Taboola as the Source
- Step 1.1: In the Asset Palette, select PIPELINES.
- Step 1.2: In the Pipelines List View, click + CREATE.
- Step 1.3: Select Taboola on the Select Source Type page.
- Step 1.4: Set the following in the Configure your Taboola Source page:
- Pipeline Name: A name for the Pipeline that is unique and does not exceed 255 characters.
- Client ID: Your Taboola advertiser account’s Client ID.
- Client Secret: Your Taboola advertiser account’s Client Secret. In the onboarding email communication, your Taboola Account Manager will share the Client ID and Client Secret. If necessary, you can request these from the Taboola team again.
- Advertiser Accounts: Once you’ve entered the correct Client ID and Secret, this field will appear. Choose which advertiser accounts you want to import data from.
- Historical Sync Duration: The time it takes for historical data to be synced with the Destination. 1 Year is the default value.
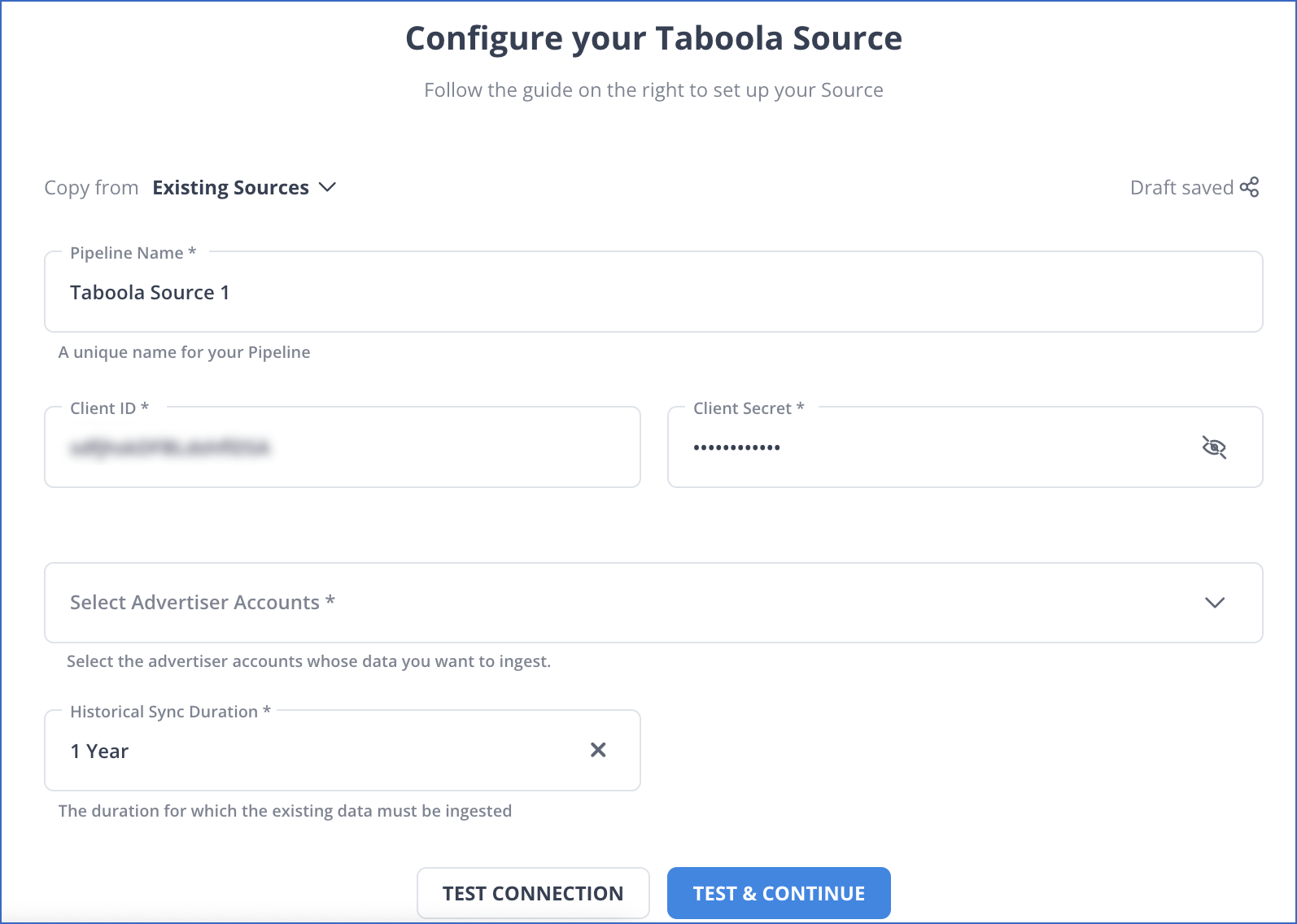
- Step 1.5: TEST & CONTINUE is the button to click.
- Step 1.6: Set up the Destination and configure the data ingestion.
Step 2: Configure Amazon Redshift as a destination.
- Step 2.1: In the Asset Palette, select DESTINATIONS.
- Step 2.2: In the Destinations List View, click + CREATE.
- Step 2.3: Select Amazon Redshift from the Add Destination page.
- Step 2.4: Set the following parameters on the Configure your Amazon Redshift Destination page:
- Destination Name: A unique name for your Destination.
- Database Cluster Identifier: Amazon Redshift host’s IP address or DNS.
- Database Port: The port on which your Amazon Redshift server listens for connections. Default value: 5439
- Database User: A user with a non-administrative role in the Redshift database.
- Database Password: The password of the user.
- Database Name: The name of the Destination database where data will be loaded.
- Database Schema: The name of the Destination database schema. Default value: public.

- Step 2.5: Click Test Connection to test connectivity with the Amazon Redshift warehouse.
- Step 2.6: Once the test is successful, click SAVE DESTINATION.
Reasons to try Hevo
- Smooth Schema Management: Hevo takes away the tedious task of schema management & automatically detects the schema of incoming data and maps it to your schema in the desired Data Warehouse.
- Exceptional Data Transformations: Best-in-class & Native Support for Complex Data Transformation at fingertips. Code & No-code Flexibility is designed for everyone.
- Quick Setup: Hevo with its automated features, can be set up in minimal time. Moreover, with its simple and interactive UI, it is extremely easy for new customers to work on and perform operations.
- Built To Scale: As the number of sources and the volume of your data grows, Hevo scales horizontally, handling millions of records per minute with very little latency.
- Live Support: The Hevo team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.
Method 2: Using Custom Code to Move Data from Taboola to Redshift
Step 1: Getting Data Out of Taboola
Using Taboola’s Backstage API, developers can extract data from its servers. You could, for example, get campaign information by calling
GET /backstage/api/1.0/[account-id]/campaigns/[campaign-id]/items/.Step 2: Sample Taboola Data
Taboola’s Backstage API returns a JSON response that looks something like this:
{
"results":[
{
"id": "1",
"campaign_id": "124",
"type": "ITEM",
"url": "http://news.example.com/article.htm",
"thumbnail_url": "http://cdn.example.com/image.jpg",
"title": "Demo Article",
"approval_state": "APPROVED",
"is_active": true,
"status": "RUNNING"
}
]
}Step 3: Loading Data into Redshift
- You can use the Redshift CREATE TABLE statement to create a table to receive all of the data after you’ve identified the columns you want to insert.
- You might be tempted to use INSERT statements to add data to your Redshift table row by row to populate that table. That’s not a good idea; Redshift isn’t built for inserting data one row at a time.
- If you have a large amount of data to insert, it’s better to load it into Amazon S3 and then use the COPY command to migrate it to Redshift.
Step 4: Keeping Taboola Data up to Date
- It’s not a good idea to duplicate all of your data every time your records are updated. This would be a painfully slow and Resource-Intensive process.
- Instead, identify key fields that your script can use to bookmark its progress through the data and return to as it searches for updated data. It’s best to use auto-incrementing fields like updated at or created at for this. You can set up your script as a Cron Job or a continuous loop to get new data as it appears in Taboola once you’ve added this functionality.
- And, as with any code, you must maintain it once you’ve written it. You may need to change the script if Taboola changes its API, or if the API sends a field with a datatype your code doesn’t recognize. You will undoubtedly have to if your users require slightly different information.

Conclusion
This blog explains the different ways to load data from Taboola to Redshift in a few steps. It also gives an overview of Taboola and Redshift.
Find out how moving data from Taboola to Snowflake can boost your analytics capabilities. Our resource offers straightforward instructions for successful data integration.
Hevo Data offers a No-code Data Pipeline that can automate your data transfer process, hence allowing you to focus on other aspects of your business like Analytics, Marketing, Customer Management, etc.
This platform allows you to transfer data from 150+ sources (including 60+ Free Sources) such as Taboola and Cloud-based Data Warehouses like Snowflake, Google BigQuery, Amazon Redshift, etc. It will provide you with a hassle-free experience and make your work life much easier.
Want to take Hevo for a spin?
Try Hevo’s 14-day free trial and experience the feature-rich Hevo suite firsthand. You can also have a look at the unbeatable pricing that will help you choose the right plan for your business needs.
FAQ on Taboola to Redshift
How do I push data to AWS Redshift?
Push data to AWS Redshift using the COPY command for bulk loading from S3 or tools like AWS Data Pipeline, AWS Glue, or third-party ETL tools such as Hevo Data.
How do I connect to the Redshift Database?
Provide the cluster endpoint, port, database name, username, and password to connect to Redshift using JDBC or ODBC drivers, psql, or SQL clients like pgAdmin.
How do I migrate from RDS to Redshift?
Migrate from RDS to Redshift by exporting data from RDS to S3 (using AWS DMS or mysqldump), then loading the data into Redshift using the COPY command.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





