




If you’re tracking time and projects using Toggl and need to analyze the data in Redshift, you’re in the right place! Toggl helps teams monitor productivity, while Amazon Redshift enables powerful data analysis and reporting. Connecting Toggl to Redshift allows you to combine time-tracking data with other business metrics for deeper insights.
In this blog, I’ll guide you through the steps to seamlessly link these two platforms, explain why this integration is useful, and show how you can use the data for more informed decision-making. Let’s get started!
Table of Contents
What is Toggl?
Toggl is a time-tracking tool for people or teams to track the hours they work and ensure productivity within projects and optimization of their project management. It has easy tracking options by which one records the hours taken on specific tasks, and reporting tools for time use analysis.
Features of Toggl
- Automated project time tracker: Track time spent on tasks with a one-click timer or manually add entries.
- Project Management: Organize time entries by projects, clients, or tasks for better project oversight.
- Reporting: Generate detailed reports on time usage, productivity, and project costs.
- Integrations: Integrates with popular tools like Trello, Asana, Slack, and more for seamless workflow management.
Say goodbye to the hassle of manually connecting Toggl to Redshift. Embrace Hevo’s user-friendly, no-code platform to streamline your data migration effortlessly.
Choose Hevo to:
- Access 150+(60 free sources) connectors, including Toggl and Redshift.
- Ensure data accuracy with built-in data validation and error handling.
- Eliminate the need for manual schema mapping with the auto-mapping feature.
Don’t just take our word for it—try Hevo and discover how Hevo has helped industry leaders like Whatfix connect Redshift seamlessly and why they say,” We’re extremely happy to have Hevo on our side.”
Get Started with Hevo for FreeWhat is Redshift?
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud, provided by Amazon Web Services (AWS). It allows you to run complex queries and analytics on massive datasets quickly, making it ideal for business intelligence, reporting, and data warehousing.
Key Features of Redshift
- Petabyte-scale data warehouse: Redshift can scale from a few hundred gigabytes to petabytes of data. You can easily resize clusters up or down as your data needs grow or shrink.
- Redshift uses a columnar storage format to store data, which drastically reduces the amount of I/O required to execute queries.
- Redshift employs Massively Parallel Processing (MPP) architecture, which distributes data and query execution across multiple nodes.
- Automated backups: Redshift automatically backs up your data to Amazon S3 (Simple Storage Service). You can configure backup retention periods, and it will retain snapshots for up to 35 days by default.
How to Replicate Data From Toggl to Redshift?
To replicate data from Toggl to Redshift, you can do either of the following:
- A no-code automated solution.
- Use CSV files
Method 1: Best Way to Replicate Data from Toggl to Redshift
Step 1: Configure Toggl as a Source.
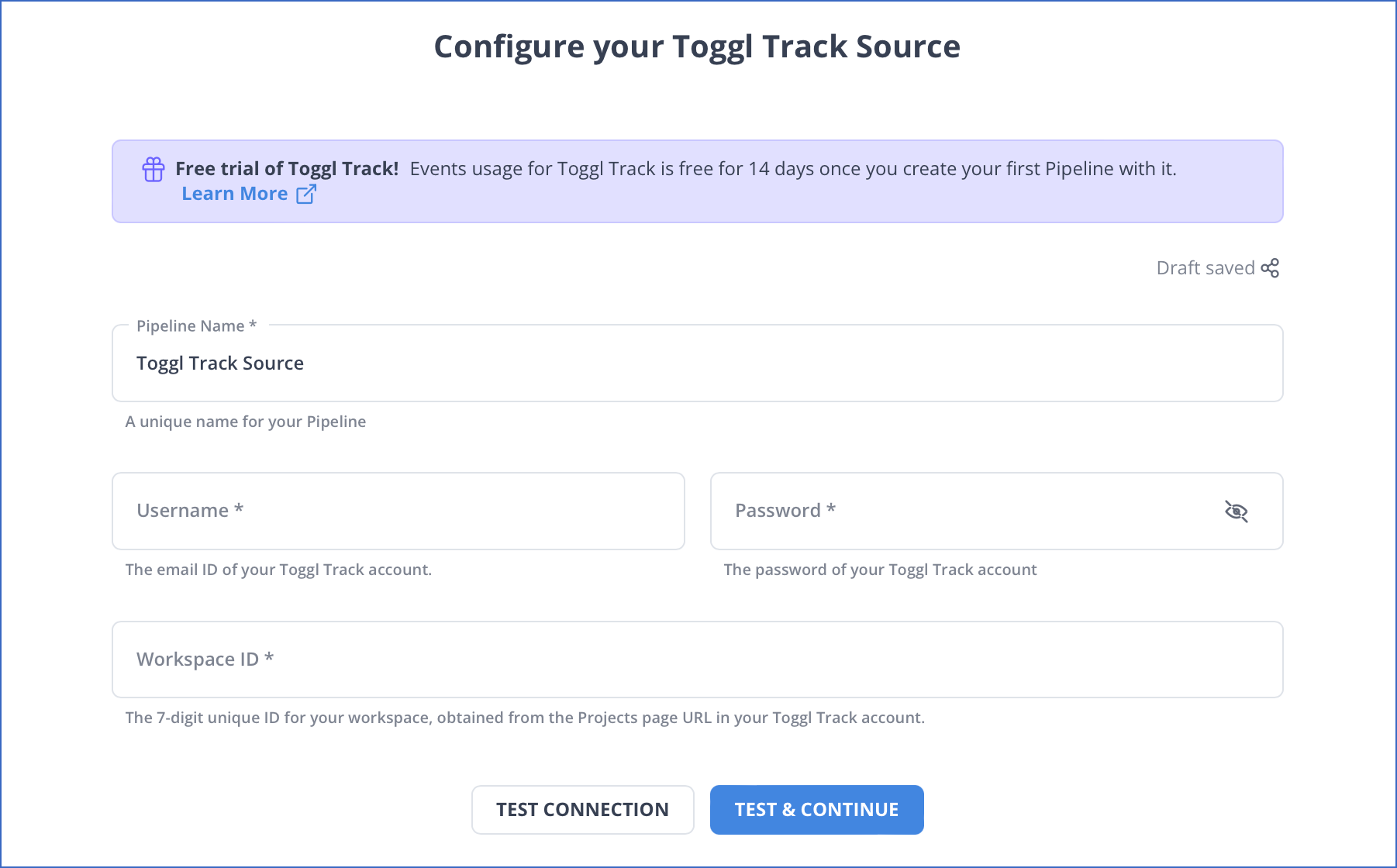
Step 2: Configure Redshift as Destination.
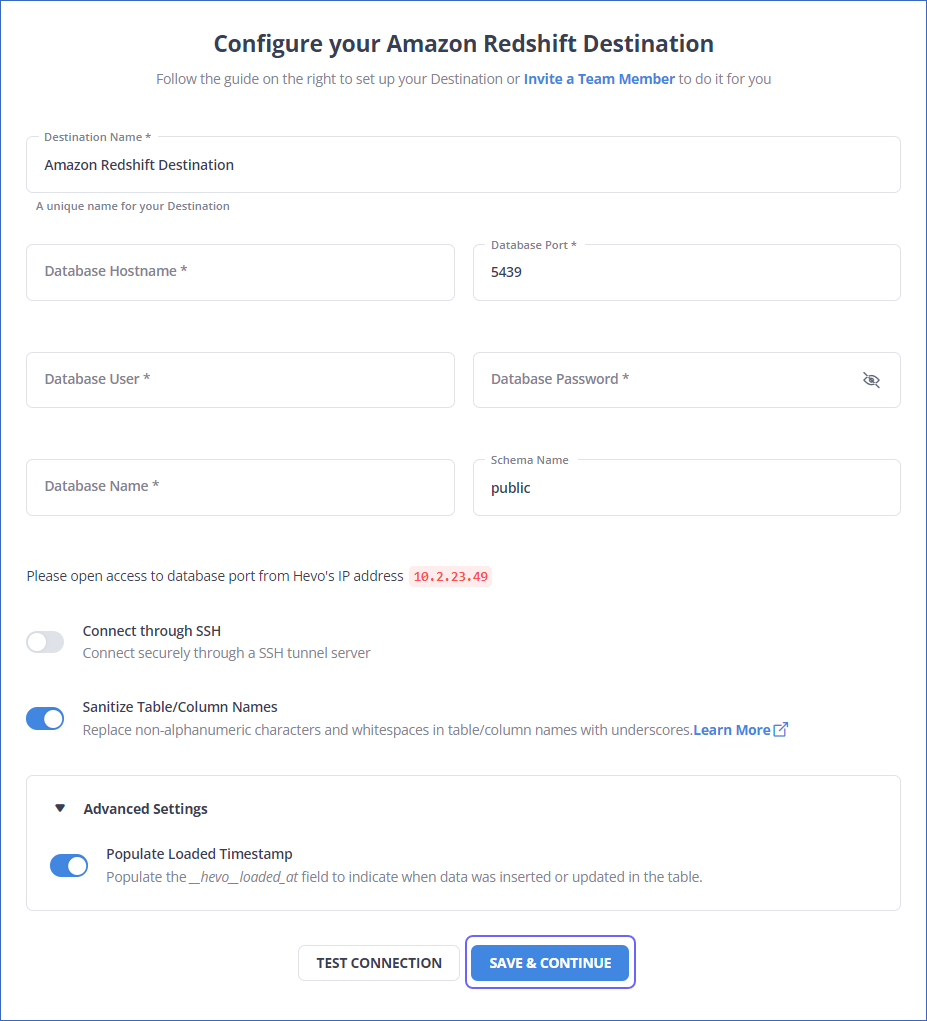
We’ll cover replication via CSV files next.
Method 2: Replicate Data from Toggl to Redshift Using CSV Files
Follow along to replicate data from Toggl to Redshift in CSV format:
Step 1: Export CSV Files from Redshift
For Exporting Time Entries
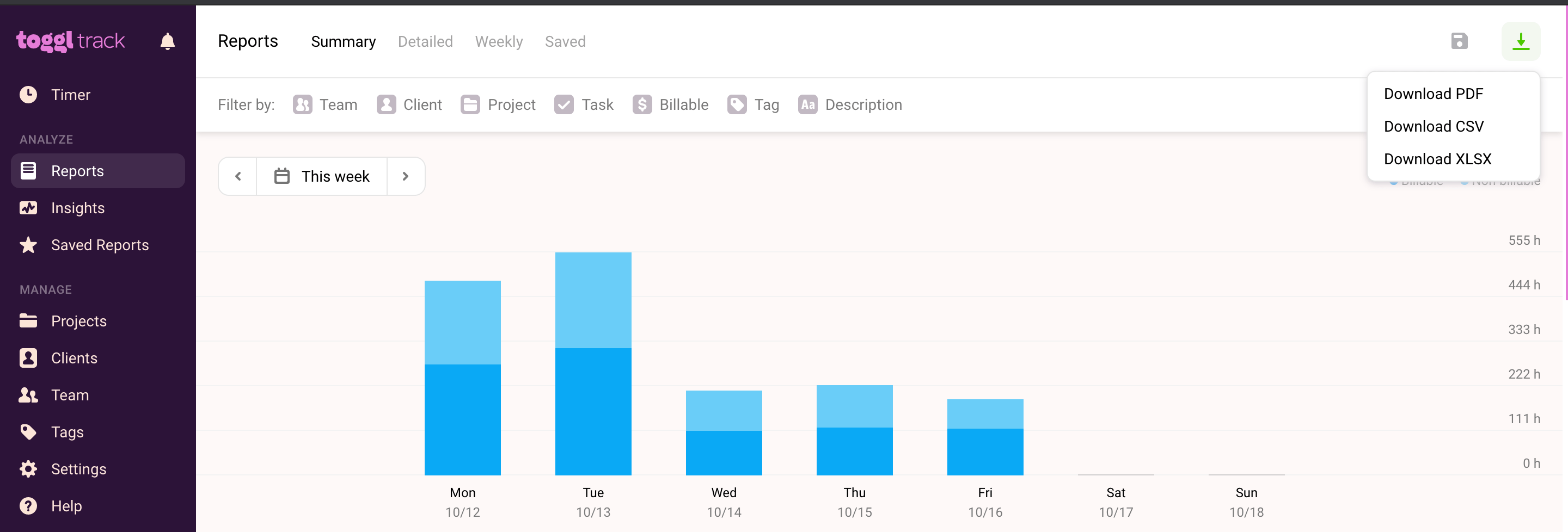
- Open the Toggltrack window.
- Go to the left navigation pane, then in the ANALYZE section, click on the “Reports” option.
- Select the reports you want to export.
- Then, to the top-left corner of the screen, click on the download icon. Click on the “Download CSV” option.
You can visit here for further information about downloading detailed reports from Toggl.
For Exporting User and Timeline Data
Users can download their profile data as well.
- Visit the Profile Settings page.
- Click on the “Export account data” button towards the top-right corner.
- Now, check the items you want to export. Then click the “Compile file and send to email” button.
- This file would be in a zip folder. Using a CSV file converter, you can extract and convert the data into CSV.
For Exporting Workspace Data
Only workspace admins have access to export workspace data.
- Go to the left navigation pane, then click on the “Settings” option.
- Now, select the “Data export” tab. You can export projects, project members, tasks, clients, tags, user groups, clients, teams, subscription invoices, and more here.
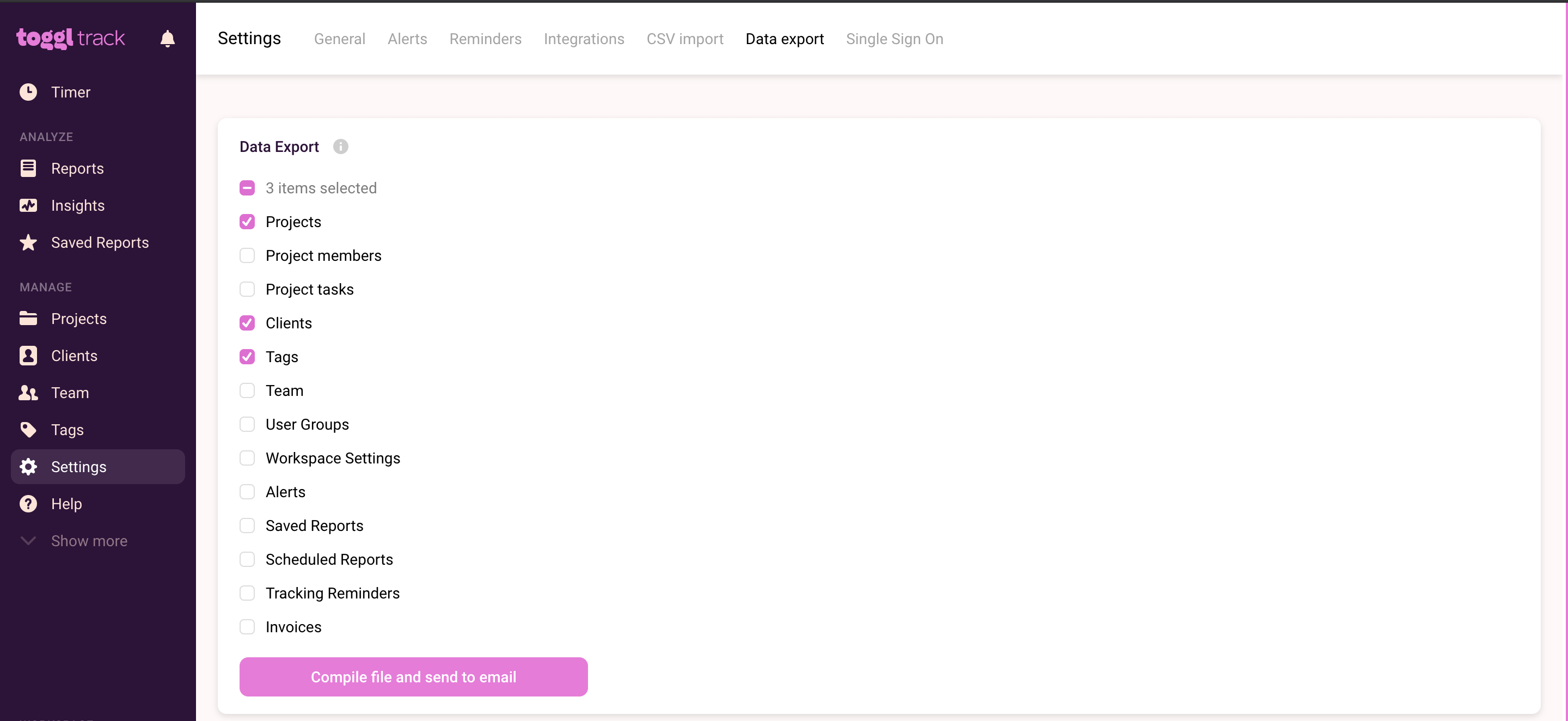
- After choosing the data you want to export, you can select the “Compile file and send to email” button.
- Data will be exported in JSON format except for invoices in pdf format.
- You can then convert all these files into CSV format using a CSV converter.
For Exporting Ingishts and Data Trends
- Open the Toggltrack window.
- Go to the left navigation pane, then in the ANALYZE section, click on the “Insights” option.
- Then select the appropriate choice from the options available.

- Then, to the top-left corner of the screen, click on the download icon. Click on the “Download CSV” option.
Step 2: Import CSV Files into Redshift
- Create a manifest file that contains the CSV data to be loaded. Upload this to S3 and preferably gzip the files.
- Once loaded onto S3, run the COPY command to pull the file from S3 and load it to the desired table. If you have used gzip, your code will be of the following structure:
COPY <schema-name>.<table-name> (<ordered-list-of-columns>) FROM '<manifest-file-s3-url>'
CREDENTIALS'aws_access_key_id=<key>;aws_secret_access_key=<secret-key>' GZIP MANIFEST;
- You also need to specify any column arrangements or row headers to be dismissed, as shown below:
COPY table_name (col1, col2, col3, col4)
FROM 's3://<your-bucket-name>/load/file_name.csv'
credentials 'aws_access_key_id=<Your-Access-Key-ID>;aws_secret_access_key=<Your-Secret-Access-Key>'
CSV;
-- Ignore the first line
COPY table_name (col1, col2, col3, col4)
FROM 's3://<your-bucket-name>/load/file_name.csv'
credentials 'aws_access_key_id=<Your-Access-Key-ID>;aws_secret_access_key=<Your-Secret-Access-Key>'
CSV
INGOREHEADER 1;
This process will load your desired CSV datasets to Amazon Redshift in a pretty straightforward manner.
You will need to generate AWS Access and Secret Key to use the COPY command and complete the Toggl to Redshift data replication process.
With the above 2-step approach, you can easily replicate data from Toggl to Redshift using CSV files and SQL queries. This method performs exceptionally well in the following scenarios:
- Low-frequency Data Replication: This method is appropriate when your HR & accounting teams need the Toggl data only once in an extended period, i.e., monthly, quarterly, yearly, or just once.
- Limited Data Transformation Options: Manually transforming data in CSV files is difficult & time-consuming. Hence, it is ideal if the data in your spreadsheets is clean, standardized, and present in an analysis-ready form.
- Dedicated Personnel: If your organization has dedicated people who have to manually download and upload CSV files, then accomplishing this task is not much of a headache.
- Low Volume Data: It can be a tedious task to repeatedly download & write SQL queries for uploading several CSV files. Moreover, merging these CSV files from multiple departments is time-consuming if you are trying to measure the business’s overall performance. Hence, this method is optimal for replicating only a few files.
When the frequency of replicating data from Toggl increases, this process becomes highly monotonous. It adds to your misery when you have to transform the raw data every single time. With the increase in data sources, you would have to spend a significant portion of your engineering bandwidth creating new data connectors. Just imagine — building custom connectors for each source, transforming & processing the data, tracking the data flow individually, and fixing issues. Doesn’t it sound exhausting?
Instead, you should be focussing on more productive tasks. Being relegated to the role of a ‘Big Data Plumber‘ that spends their time mostly repairing and creating the data pipeline might not be the best use of your time.’

Limitations of Using CSV files to Transfer Data from Toggl to Redshift
- Time-Consuming: The data exported from Lemlist needs to be extracted in CSV files and imported manually in Snowflake, so it is more of a human-intensive process. This process will be inefficient if one were to transfer large or frequent loads.
- Human Error: There is a high probability of probable mistakes in information extraction, transformation, or uploading in manual processes that would make the data inconsistent.
- No Real-Time Updates: CSV transfers can be only batched based, meaning data isn’t updated in real-time. This might result in analytics and reporting conducted in Snowflake based on outdated information.
- Lack of Data Validation: CSV files never force proper validation on input data. As a result, such faulty data may be transferred into Snowflake, thus posing difficulties to query or further analyze.
Use Cases of Connecting Toggl with Redshift
- Custom Reporting: Redshift enables you to create tailored dashboards through combining data from Toggl with other BI tools, thereby keeping track of the cost of projects and how much time has been invested in the project.
- Project Performance Analysis: Load the Toggl time-tracking report into Redshift, which will then empower you in finding the duration of projects, identifying bottlenecks, and tracking the better resources engaged.
- Team Productivity Insights: Combine data from Toggl with other datasets to measure the productivity trend of individuals as well as teams. This can assist you in making proper data-driven decisions about optimizing team management and improvement of performance.
- Account for Your Finances: Track the number of hours spent on billable tasks. You can relate this to billing systems in Redshift, which means that your revenues are now credibly invoiced and you have cash flow predictions that are more accurate.
What Can You Achieve by Replicating Your Data from Toggl to Redshift?
Replicating data from Toggl to Redshift can help your data analysts get critical business insights. Does your use case make the list?
- Clients from which geography do you serve the most?
- Which project members work heavily in the US region?
- What is the average daily variation of all the users?
- Who are the significant contributors to a project?
- How to optimize your employees’ workflow?
Read More About: How to Connect Toggl to Databricks
Summing It Up
Exporting and importing CSV files would be the smoothest process when your HR & accounting teams require data from Toggl only once in a while. But what if the HR & accounting teams request data from multiple sources at a high frequency? Would you carry on with this method of manually importing & exporting CSV files from every other source? In this situation, you would rather choose to liberate your manual jobs by going for a custom ETL solution.
However, a custom ETL solution becomes necessary for real-time data demands, such as monitoring daily activities across different platforms or viewing the division of billable working hours across divisions. You can free your engineering bandwidth from these repetitive & resource-intensive tasks by selecting Hevo Data’s 150+ plug-and-play integrations (including 60+ free sources such as Toggl).
Sign up for a 14-day free trial and simplify your data integration process. Check out the pricing details to understand which plan fulfills all your business needs.
Frequently Asked Questions
1. Can we do ETL in Redshift?
Yes, ETL can be done in Redshift using SQL commands, AWS Glue, or third-party ETL tools like Hevo or Fivetran for data extraction, transformation, and loading.
2. How to load data from JSON to Redshift?
-Store the JSON files in Amazon S3.
-Use the COPY command in Redshift with the JSON or AUTO option to load the data.
3. How to schedule SQL in Redshift?
You can schedule SQL queries in Redshift using AWS EventBridge (formerly CloudWatch Events) or Amazon Redshift Query Scheduling with the Redshift Console to automate and run SQL commands at specific intervals.t

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



