




You are going about your day setting up your organization’s data infrastructure and preparing it for further analysis. Suddenly, you get a request from one of your team members to replicate data from Toggl to Databricks.
We are here to help you out with this replication. You can replicate Toggl to Databricks using CSV or pick an automated tool to do the heavy lifting for you. This article provides a step-by-step guide for both of them.
Table of Contents
Toggl: Key Features for Smarter Time Tracking
- One-Click Time Tracking: Easily start and stop time tracking with a single click, ideal for seamless task management.
- Project & Client Tracking: Organize time entries by projects or clients to streamline billing and performance insights.
- Reporting & Analytics: Generate detailed reports on time usage, team productivity, and project status to guide data-driven decisions.
- Integrations: Connect with tools like Asana, Trello, and Slack for enhanced project management.
- Mobile and Desktop Access: Track time from anywhere with apps for mobile and desktop, keeping productivity insights always accessible.
Databricks: Key Features for Unified Data Analytics
- Unified Data Analytics Platform: Combines data engineering, data science, and analytics in one platform.
- Integrated with Apache Spark: Provides high-performance data processing using Apache Spark.
- Collaborative Notebooks: Interactive notebooks for data exploration and collaboration.
- Delta Lake for Reliable Data Lakes: Ensures data reliability and quality with ACID transactions.
- Machine Learning Capabilities: Supports the full machine learning lifecycle from model development to deployment.
Streamline your time-tracking data by migrating from Toggl to Databricks! Effortlessly consolidate and analyze your time entries with powerful analytics capabilities, enabling you to uncover insights and optimize productivity like never before. Use Hevo for:
- Simple two-step method for replicating Toggl to Databricks.
- Performing pre/post load transformations using drag-and-drop features.
- Real-time data sync to get analysis-ready data.
You can see it for yourselves by looking at our 2000+ happy customers, such as Airmeet, Cure.Fit, and Pelago.
Get Started with Hevo for FreeWhat is the Easiest and Fastest Way to Connect Toggl to Databricks?
The best way to connect Toggl to Databricks is by using an automated no-code platform like Hevo. Hevo lets you connect 150+ sources with your desired destination within minutes. Follow these two simple steps to perform this migration:
Step 1: Configure Toggl as your source.
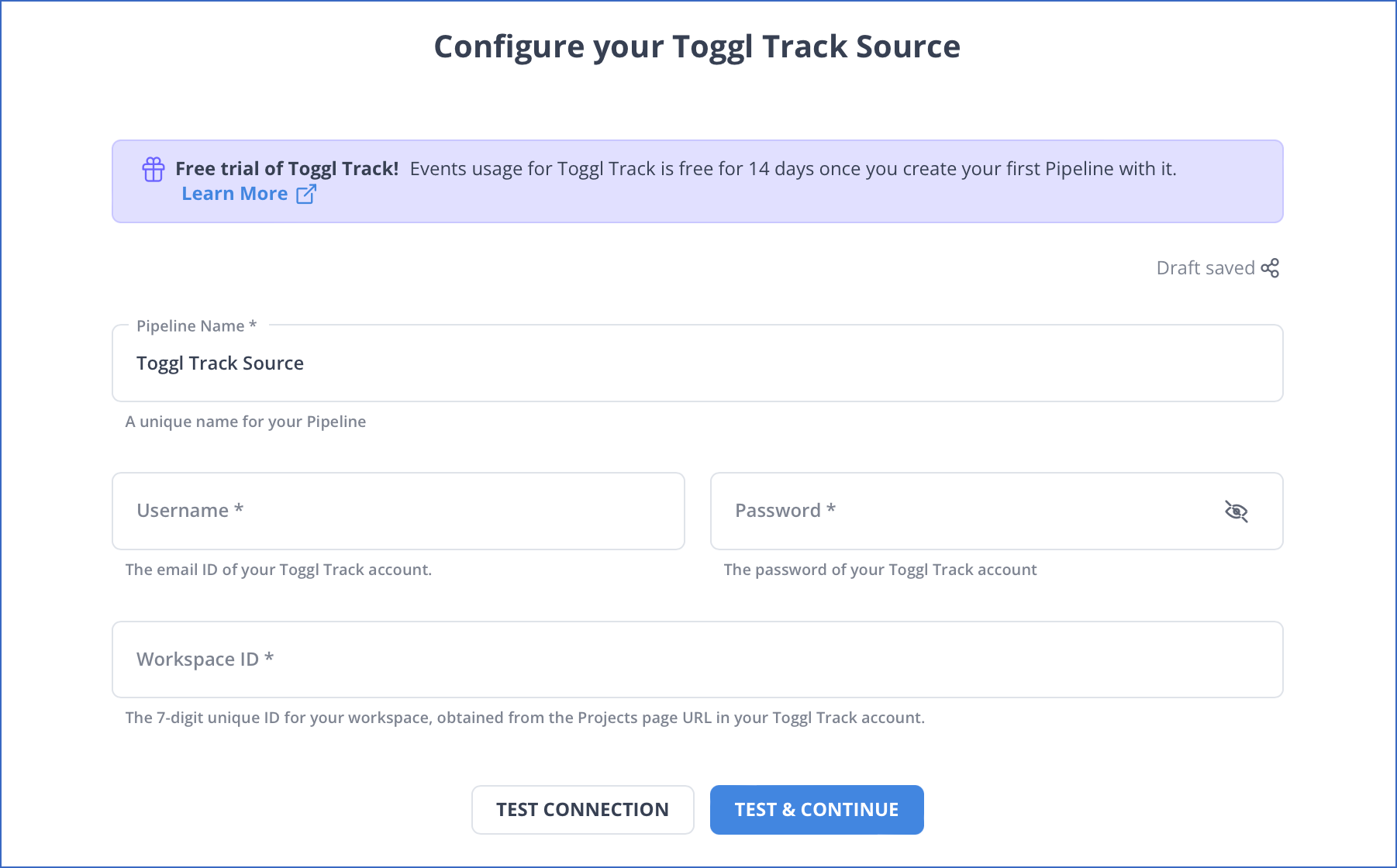
Step 2: Configure Databricks as your destination.

Wasn’t this super easy? Hevo is the best solution available in the market for seamless data migration. Don’t trust our word? See for yourself by trying more such migrations.
How to Connect Toggl to Databricks Manually?
To replicate data from Toggl to Databricks, you can use CSV or a no-code automated solution. We’ll cover replication using CSV files first.
Extract Data from Toggl in the form of CSV files
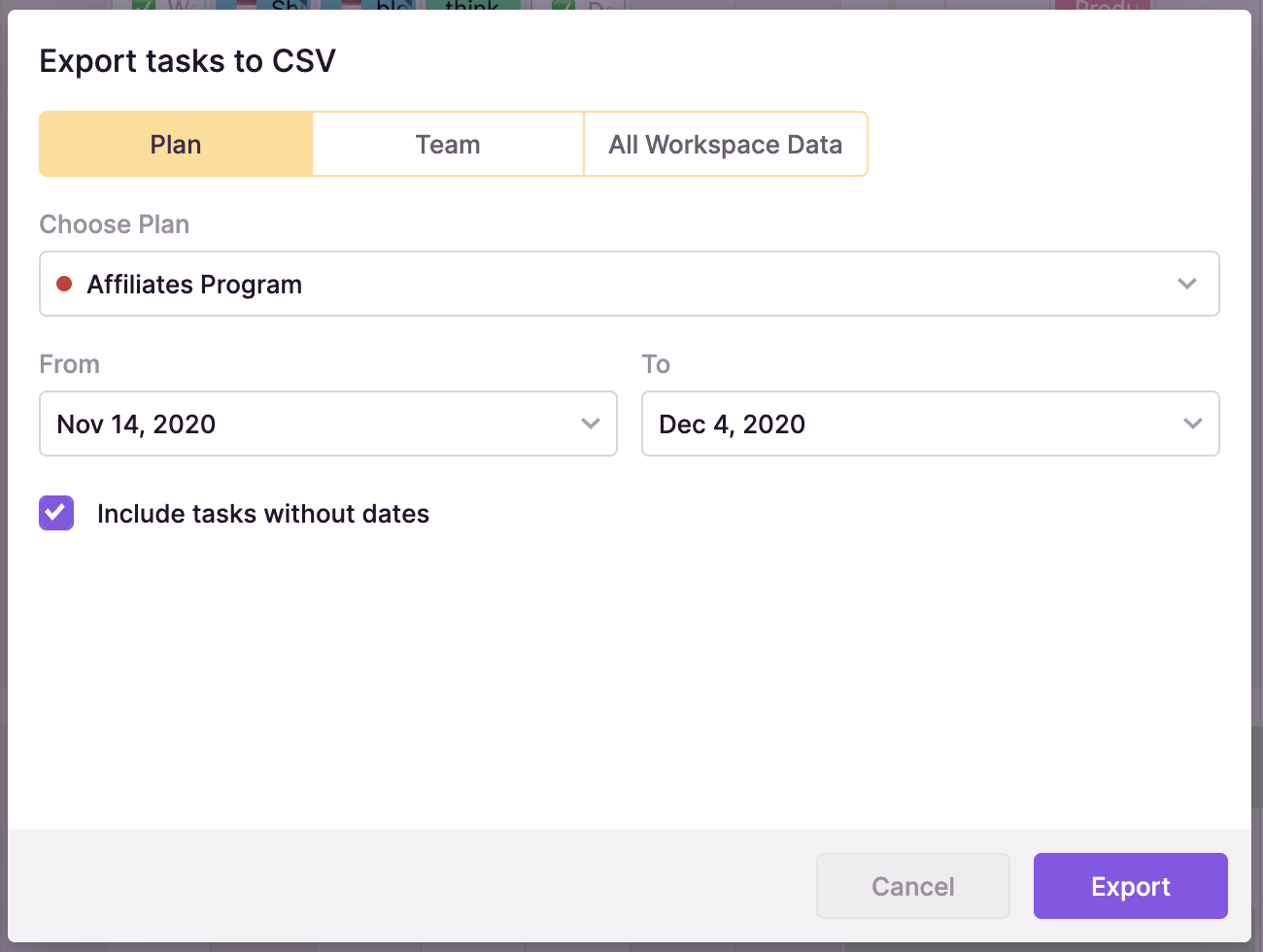
The “Export Tasks” button and data export options are under the three-dot menu in the upper right corner of the Team and Plan views, respectively. Three tiers are available for data export:
- Export the entire workspace’s data, including all Projects, Teams, archived Projects, and Task box tasks.
- Choose the Project, the dates, and whether or not you want to add tasks without dates when you export a specific project.
- Export a certain Team: Select the Team, the dates, and whether or not you wish to include tasks without due dates.
The .csv files can be opened, for instance, in Excel or Google Sheets. To ensure that the data is shown appropriately in the applications, use the Import function.
Import CSV Files to Databricks using the UI
- Step 1: Select the Admin Console option by clicking on the Settings icon in the Workspace UI’s lower left corner.
- Step 2: The Workspace Settings tab should now be selected.
- Step 3: To use Databricks Read CSV, open the Advanced section, activate the Upload Data using the UI toggle, and then click Confirm.
Using CSV is a great way to replicate data from Toggl to Databricks. It is ideal in the following situations:
- One-Time Data Replication: When your business teams require these Toggl files quarterly, annually, or for a single occasion, manual effort and time are justified.
- No Transformation of Data Required: This strategy offers limited data transformation options. Therefore, it is ideal if the data in your spreadsheets is accurate, standardized, and presented in a suitable format for analysis.
- Lesser Number of Files: Downloading and composing SQL queries to upload multiple CSV is time-consuming. It can be particularly time-consuming if you need to generate a 360-degree view of the business and merge spreadsheets containing data from multiple departments across the organization.
You face a challenge when your business teams require fresh data from multiple reports every few hours. For them to make sense of this data in various formats, it must be cleaned and standardized. This eventually causes you to devote substantial engineering bandwidth to creating new data connectors. To ensure a replication with zero data loss, you must monitor any changes to these connectors and fix data pipelines on an ad hoc basis. These additional tasks consume forty to fifty percent of the time you could have spent on your primary engineering objectives.
How about you focus on more productive tasks than repeatedly writing custom ETL scripts, downloading, cleaning, and uploading CSV? This sounds good, right?
What can you hope to achieve by replicating data from Toggl to Databricks?
By migrating your data from Toggl to Databricks, you will be able to help your business stakeholders find the answers to these questions:
- Clients from which geography do you serve the most?
- Which project members work heavily in the US region?
- What is the daily average variation of all the users?
- Who are the significant contributors to a project?

Use Cases of Migrating Data from Toggl to Databricks
- Moving Toggl data to Databricks allows for in-depth analysis of time logs across projects and teams. For example, a consultancy firm can analyze employee productivity and pinpoint which tasks or projects consume the most time, helping optimize work distribution.
- By integrating Toggl’s time-tracking data into Databricks, finance teams can compare time spent on projects with budgets and forecast costs more accurately.
- Databricks enables companies to analyze patterns in Toggl data to forecast workload and resource needs. For example, a digital marketing agency can examine time logs to plan staff allocation during peak campaign seasons.
- Managers can use Databricks to analyze individual or team-level Toggl data, identifying high performers or areas needing support.
You can also read more about:
Key Takeaways
These data requests from your marketing and product teams can be effectively fulfilled by replicating data from Toggl to Databricks. If data replication must occur every few hours, you will have to switch to a custom data pipeline. This is crucial for marketers, as they require continuous updates on the ROI of their marketing campaigns and channels. Instead of spending months developing and maintaining such data integrations, you can enjoy a smooth ride with Hevo Data’s 150+ plug-and-play integrations (including 60+ free sources such as Toggl).
Databrick’s “serverless” architecture prioritizes scalability and query speed and enables you to scale and conduct ad hoc analyses much more quickly than with cloud-based server structures. The cherry on top — Hevo Data will make it further simpler by making the data replication process very fast!
Saving countless hours of manual data cleaning & standardizing, Hevo Data’s pre-load data transformations get it done in minutes via a simple drag n drop interface or your custom python scripts. No need to go to your data warehouse for post-load transformations. You can simply run complex SQL transformations from the comfort of Hevo Data’s interface and get your data in the final analysis-ready form.
Sign for a 14-day free trial and simplify your data integration process. Check out the pricing details to understand which plan fulfills all your business needs.
Frequently Asked Questions
1. How do I push data to Databricks?
Use Databricks REST API, Azure Data Factory, or Spark connectors to ingest data from various sources directly into Databricks.
2. What is the best ETL tool for Databricks?
Hevo, Apache Spark, Azure Data Factory, and Databricks Delta are popular ETL tools optimized for Databricks.
3. How to migrate data from SQL Server to Databricks?
Use Azure Data Factory to create a pipeline that extracts data from SQL Server and loads it into Databricks. Alternatively, use JDBC connections within Databricks.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



