




Data extraction is the backbone of the ETL (Extract, Transform, Load) process, which drives the data and analytics workflows of many organizations. It’s the most demanding stage of any data-related project, requiring careful planning and execution to ensure a smooth data pipeline. Factors like data sources, extraction methods, and the accuracy of the gathered information all play a role in determining the success of this crucial step.
In this blog, we’ll delve into the exciting world of gathering and processing data, exploring how a properly designed and executed approach can make the rest of the data pipeline more efficient and result-oriented. Get ready to learn how effective data handling can drive business growth and bring your insights to the next level.
Table of Contents
What Is Data Extraction?
Data extraction refers to the process of collecting information from various sources for transformation, storage, or feeding it to another system for further analysis. This process is also known as data collection, as it involves gathering data from different sources such as web pages, emails, flat files, Relational Database Management Systems (RDBMS), documents, Portable Document Format (PDFs), scanned text, and more. The sources from which this information is gathered can be structured or unstructured.
With structured data, the information follows a specific format or schema, such as a database table with clearly defined columns of particular data types and values contained in rows. On the other hand, unstructured data does not follow a definite format, making it more tedious to retrieve from sources like free-form text, images, and web pages.
In modern times, data is also being sourced from recording or measuring devices like sensors and Internet of Things (IoT) devices. As a result, data needs to be gathered from a variety of input sources, including some located at the edge of computing. Given this, it’s crucial for any collection process to be both robust and capable of providing consistent data to the next layer of the data pipeline toolchain.
Looking for the best ETL tools to connect your data sources? Rest assured, Hevo’s no-code platform helps streamline your ETL process. Try Hevo and equip your team to:
- Integrate data from 150+ sources(60+ free sources).
- Utilize drag-and-drop and custom Python script features to transform your data.
- Risk management and security framework for cloud-based systems with SOC2 Compliance.
Try Hevo and discover why 2000+ customers have chosen Hevo over tools like AWS DMS to upgrade to a modern data stack.
Sign up here for a 14-Day Free Trial!What Is the Need for the Extraction of Data?
The importance of gathering data cannot be ignored, as it is an integral part of the data workflow that transforms raw information into valuable insights that can significantly impact a company’s bottom line. Any successful data project must first get the data portion right, as inaccurate or faulty information will lead to incorrect results, regardless of how well-designed the data modeling techniques may be.
The process of pulling data typically shapes raw, scattered, and disorganized information into a more useful, structured form that can be further processed. It also opens up analytics and Business Intelligence tools to new sources of data from which valuable insights can be derived.
For instance, without proper data collection, information from web pages, social media feeds, video content, and other sources would be inaccessible for further analysis. In today’s interconnected world, data from online sources can be leveraged to gain a competitive edge through sentiment analysis, understanding user preferences, churn analysis, and more. Thus, it’s clear that any serious data operation must focus on fine-tuning this component to maximize the chances of a successful outcome.
What Are the Steps for Fetching Data in Etl?
A central data store like a cloud warehouse collects and stores information from one or more data sources using the Extract, Transform, and Load (ETL) process. Data extraction represents the first step in ETL, which is a tried and proven data paradigm for
- Extracting data from multiple sources using APIs or webhooks and staging it into files or relational databases.
- Transforming it into a format that’s suitable for reporting and analytics by enriching and validating the data, applying business rules, and enforcing consistency across all data fields.
Easily manage and transform your data on Snowflake with Hevo Transformer—automate dbt workflows, track versions via Git, and validate in real time.
- Quick Data Integration – Connect your warehouse in a snap and auto-fetch tables
- No-Hassle dbt Automation – Build, test, and deploy with ease
- Version Control with Git – Track changes effortlessly with Git integration
- Instant Data Transformation – Preview and push changes instantly
- Loading the high-quality, transformed data into a target data store like a data lake or a data warehouse to make it available for other stakeholders for reporting and analysis.
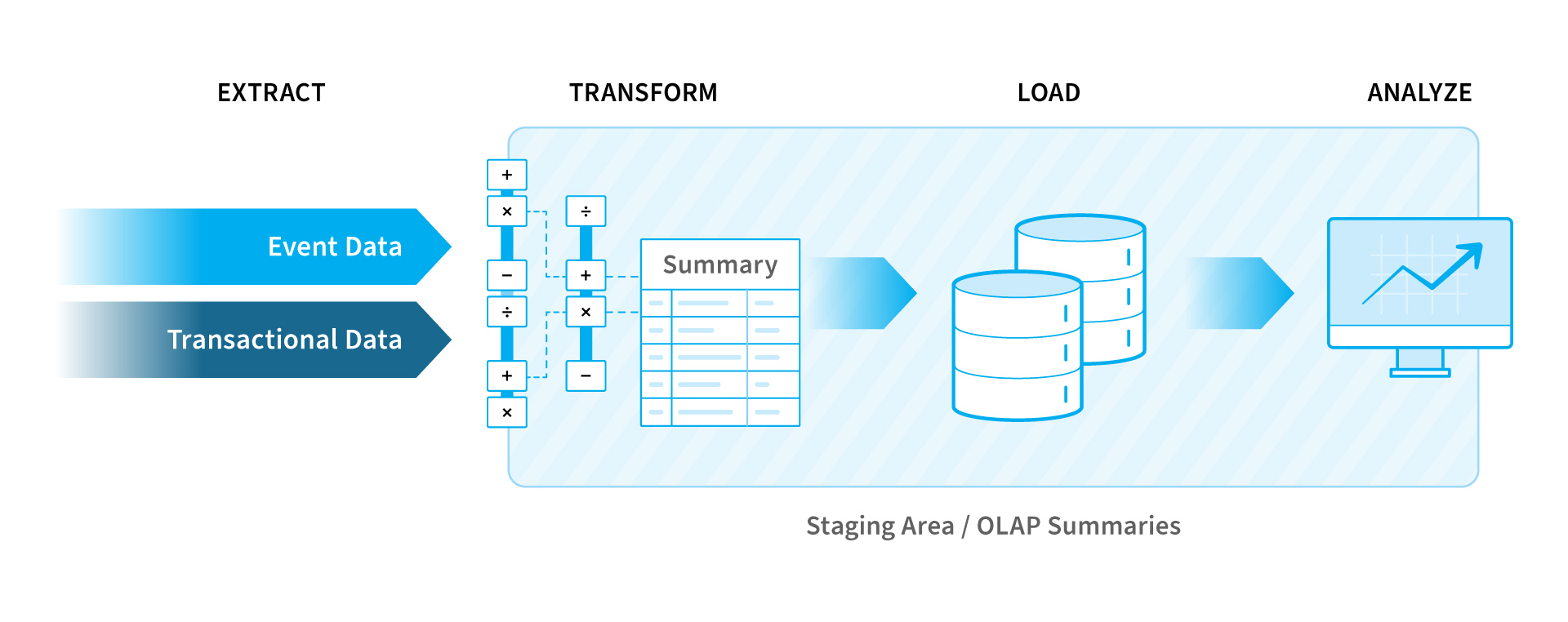
Organizations of all sizes and industries use the ETL approach for integrating their marketing, sales, and customer service applications, data services, and unstructured files.
A well-engineered ETL pipeline with an apposite data collection process can provide novel business insights and ensure the completeness of information, helping stakeholders make decisions with clear information, and eliminating confusion from indefinite data.
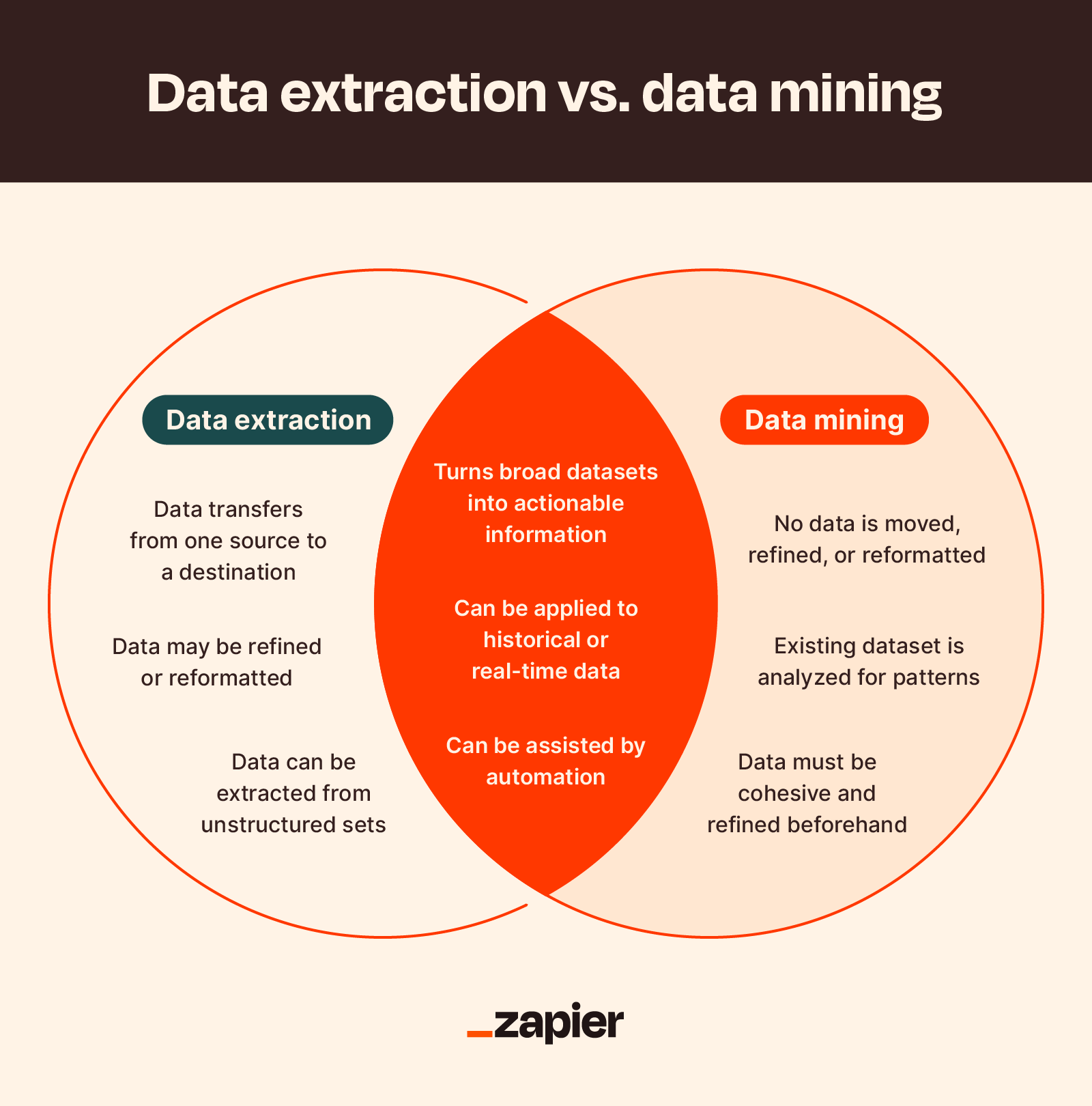
Data Extraction vs Data Mining
It’s easy to confuse data extraction with data mining. Although these two terms are related, they refer to different processes with different goals.
| Data Extraction | Data Mining | |
| Primary Use | Retrieve data efficiently from one or multiple data sources for storage or analysis. | Identify hidden patterns efficiently from large and existing data sets. |
| Operates On | Semi-structured and unstructured data sources. | Structured data sets. |
| Engineering Expertise Required | Minimal, because using the right ELT/ETL tool you can simplify the process. | High, since it involves knowledge of various techniques such as statistical analysis, machine learning, and artificial intelligence, along with other tools to extract useful information from data. |
| Methodology | Proven and definite. | Innovative and (often) experimental. |
| Operational Technologies Involved | ELT/ETL tool and a data store. | OLAP database systems, data warehouse, transformation tools, ML & AI systems. |
Challenges of Data Extraction
Even though data extraction is one of the most essential steps in the journey toward data analysis, it is not without its own challenges. Some of these include
- Data Volume Management: Your data architecture is designed to handle a specific ingestion volume. If processes are created for small amounts of data, they may not function properly when dealing with larger quantities. When this happens, parallel extraction solutions may be necessary, but they can be challenging to engineer and maintain.
- Data Source/API Constraints: Data sources vary and so do extractable fields. So it’s important to consider the limitations of your data sources when extracting data. For instance, some sources like APIs and webhooks may have restrictions on how much data can be extracted at once.
- Synchronous Extraction: Your extraction scripts must run with precision, taking into account factors such as data latency, volume, source limitations, and validation. The symphony of extraction becomes a complex masterpiece when multiple architectural designs are utilized to cater to different business needs.
- Prior Data Validation: Data validation can happen at the extraction stage or the transformation stage. If done during extraction, one should check for any missing or corrupted data, such as empty fields or nonsensical values.
- Intensive Data Monitoring: To ensure the proper functioning of your system, it is important to monitor it on several levels, including resource allocation (e.g. computational power and memory), error detection (e.g. missing or corrupted data), and reliability (e.g. proper execution of extraction scripts).

Data Extraction Techniques
There are broadly two ways to extract data from heterogeneous sources: logical extraction and physical extraction. Both methods involve crawling and retrieving data, but they differ in how the data is collected and processed.
1. Logical Extraction involves extracting data from a database or other structured data source in a way that preserves the relationships and integrity of the data.
Logical extraction typically uses a database management system’s (DBMS) query language or API to extract the data in a structured format that can be easily imported into another database or system. The extracted data will also retain the relationships and constraints that are defined in the source system’s schema, ensuring that the data is consistent and accurate.
It can be of four types:
- Full Extraction: Full extraction involves pulling all data from a source system, often used when migrating data or when the source system does not support incremental extraction. While it ensures a complete dataset, this method can be resource-intensive, so it’s recommended to perform it during off-peak hours to minimize system strain.
- Incremental Extraction: Incremental extraction only retrieves data that has changed or been updated since the last extraction. This method is more efficient than full extraction, as it reduces the amount of data that needs to be transferred and processed. It helps maintain data freshness while saving time and resources.
- Source-driven Extraction (or CDC) focuses on capturing and recording any changes made to a source system at regular intervals. This method ensures that only the latest changes are retrieved, keeping data synchronized and up-to-date without overloading the system with unnecessary data transfers.
- Structured Extraction utilizes tools to pull data from structured sources like relational databases or Excel files, where the data is organized into tables or records. This extraction method works with well-defined schemas, making it easier to process and analyze the extracted information.
2. Physical Extraction involves copying raw data files from a storage device without regard for the relationships between the data elements.
It can be of two types:
- Online Extraction, when extracting data directly from a live system while it is still in operation (real-time data replication).
- Offline extraction, when extracting data from a system that is not currently running (may not provide real-time data replication).
Additional Techniques for Data Extraction
Several other methods are also employed in fetching data such as:
- Optical Character Recognition (OCR): A technology that extracts text and data from images or scanned documents.
- Web Scraping: An automated technique that utilizes software or scripts to gather data from websites. This data is then stored in structured formats such as CSV, JSON, or databases.
Explore Data Extraction Techniques in more detail.
Data Extraction Methods
Data extraction methods can be scheduled jobs or performed on-demand based on business needs and analysis goals. There are three primary types, ranging from the most basic to the most complex:
- Update Notification:
- This method involves having the source system issue a notification when a record is changed.
- Many databases support automation mechanisms like database replication (change data capture or binary logs) for this purpose.
- SaaS applications often utilize webhooks to provide similar functionality.
- Change data capture allows for real-time or near-real-time data analysis.
- Incremental Extraction:
- In cases where the source system cannot provide notifications of updates, this method identifies modified records and extracts them.
- During subsequent ETL (Extract, Transform, Load) steps, the extraction code must recognize and propagate changes.
- One limitation is the difficulty in detecting deleted records in the source data, as there’s no indication of a record that no longer exists.
- Full Extraction:
- The initial replication of any source requires a full extraction, especially when the fsource lacks mechanisms to identify changed data.
- Some sources may not have the capability to track changes, necessitating the reloading of the entire table.
- Full extraction involves handling high volumes of data, potentially impacting network load, making it less preferable if alternatives are available.
Benefits of Data Extraction Tools
ETL/ELT tools that automate data extraction from disparate data sources can offer a lot of advantages to data engineers, scientists, and business analysts:
- Plug-and-Play Connectivity: Most tools like Hevo Data offer plug-and-play connectors to your most frequently used business applications. With a few clicks, you can connect your source and start ingesting data.
- Greater Sense of Control: Imagine the hassle of creating a new pipeline connection for each new data source, and fixing broken pipelines every time APIs change. With automated ETL/ELT tools, you can be worry-free, move fast, and spend time on high-value tasks.
- Economies of Scale: Scaling data by creating parallel solutions is like wheels within wheels. In such cases, data extraction tools can be more cost-effective than manually extracting the data.
- Easy Compliance: Tools can help organizations to comply with data governance regulations by allowing them to track and audit data changes.
Most Popular Data Extraction Tools
Improving data quality, automating data collection, and making data-driven decisions can be made simpler through the use of these widely used ETL/ELT tools.
- Hevo Data: Experience effortless data flow with our no-code pipeline platform. Enjoy easy setup and over 150+ connections, all backed by round-the-clock support at unbeatable prices.
Hevo has simplified a lot of our tasks. We have scrapped our entire manual data integration process and switched to automation. We use Hevo’s data pipeline scheduling, models, and auto-mapping features to seamlessly move our data to the destination warehouse. We flatten certain columns from our incoming data using the Python interface in Hevo and our risk team uses Models to write SQL queries to get the required data for reporting.
– Vivek Sharma, Data Engineering Lead, Slice
- Import.io: Extract web data at scale in a simple and efficient way, turning unstructured data into structured data ready for analysis.
- Octoparse: A visual web scraping tool with point and click interface that enables users to extract data from any dynamic website and save it in various formats like CSV, Excel, and more.
- Parsehub: Easily extract data from JavaScript and AJAX pages, search through forms, automate data collection processes, and integrate the collected data into various applications.
- OutWitHub: A powerful tool for everyone that offers an intuitive interface with sophisticated scraping functions and data structure recognition.
- Web Scraper: Another simple and powerful application to extract data from websites, automate data collection processes, and save the collected data in various formats like CSV, JSON, and more.
- Mailparser: An email parser that can extract data from your email, PDFs, DOC, DOCX, XLS, or CSV files and automatically import this data into Google Sheets.
Data Extraction Use Cases
Streamlining ERP Data Entry: How Alpine Industries Processes Thousands of Purchase Order PDFs

Alpine Industries, a leading manufacturer of solution-based products for commercial and institutional markets, faces a daily inundation of PDF documents such as purchase orders, invoices, shipment notifications, and backorder notifications. Previously, the team responsible for processing these documents had to manually read and enter the information into their ERP system, leading to time-consuming tasks like recording batch payments from large customers.
To overcome this challenge, Alpine Industries introduced a comprehensive data management platform powered by Google Cloud and Docparser, streamlining the entire data process from extraction to integration.
The platform allows for real-time updates of parsed invoices and accurate shipment tracking, enabling teams to easily access clean, enhanced data. This has significantly reduced the workload on customer service from hours to seconds.
Red Caffeine: Making Lead Management Easy

Red Caffeine, a growth consulting firm, assists businesses in enhancing their brand reputation and boosting sales through their diverse range of services like marketing strategy, brand development, website design, digital marketing, and advertising.
Customized solutions are offered to clients across different industries to help them reach their target audience and achieve growth. To provide these tailored solutions, Red Caffeine leverages multiple platforms and tactics for raising awareness, capturing interest, and managing leads.
The key to their success lies in the seamless integration of these groups through effective techniques for extracting data. This ensures all components are aligned and working together harmoniously, making data extraction a critical aspect of their business.
Embracing the Future of Data Extraction: Trends and Possibilities
Affordable cloud storage and lightning-fast computing are driving more and more solutions to operate in the cloud. In the years ahead, the cloud will continue to transform data gathering by providing fast, secure, and scalable access. More companies are adopting multi-cloud strategies with advanced capabilities to pull data from multiple sources in real-time.
As the volume of unstructured data grows, more efficient methods for handling and processing it will emerge. With an increasing number of sources, new techniques will be developed to ensure the protection of sensitive information during the collection process. AI and ML algorithms will play a significant role in automating and improving these workflows.
Additionally, the growing use of IoT devices will drive the expansion of edge computing, shaping the future of data collection by enabling access to data from remote locations.
Conclusion
Data Extraction is a vast field, as the amount of data being produced is increasing exponentially. Various tools in the market seek to address the challenges faced while extracting data. One such tool is Hevo Data.
Hevo is the only real-time ELT No-code Data Pipeline platform that cost-effectively automates data pipelines that are flexible to your needs. Hevo allows you to extract data from 150+ data sources, transform it into a form suitable for analysis, and connect it to your data warehouse or directly to a Business Intelligence tool of your choice to perform the required analysis. Sign up for a 14-day free trial and streamline your data workflows effortlessly!
FAQs
1. What are the key steps involved in extracting data?
Data extraction involves retrieving information from a source and converting it into a usable format. The process includes several steps: identifying data sources, discovering and profiling the data, choosing an extraction method, cleaning and transforming the data, and loading the extracted data for use.
2. What are the two types of data extraction?
Two categories are logical and physical. Logical extraction maintains the relationships and integrity of the data while extracting it from the source. Physical extraction, on the other hand, extracts the raw data as is from the source without considering the relationships.
3. Is SQL a data extraction technique?
SQL (Structured Query Language) is a popular language to extract data from relational databases. SQL allows you to query the data stored in a database and retrieve the desired information. This information can then be used to populate a data warehouse or for reporting, and analysis.
4. What is data pulling?
Data pulling involves extracting data from different sources and transforming it into a usable format. This essential step in data management enables the data to be integrated into applications or analytics platforms.


Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



