
Google BigQuery is a fully managed data warehouse tool. It allows scalable analysis over a petabyte of data, querying using ANSI SQL, integration with various applications, etc. To access all these features conveniently, you need to understand BigQuery architecture, maintenance, pricing, and security.
This guide decodes the most important components of Google BigQuery: BigQuery architecture, maintenance, performance, pricing, and security.
Table of Contents
What Is Google BigQuery?

Google BigQuery is a cloud data warehouse run by Google. It is capable of analyzing terabytes of data in seconds. If you know how to write SQL queries, you already know how to query it. In fact, there are plenty of interesting public data sets shared in BigQuery, ready to be queried by you.
You can access BigQuery by using the GCP console or the classic web UI, by using a command-line tool, or by making calls to BigQuery REST API using a variety of client libraries such as Java, and .Net, or Python.
There are also a variety of third-party tools that you can use to interact with BigQuery, such as visualizing the data or loading the data.
Are you having trouble integrating your data into BigQuery? With our no-code platform and competitive pricing, Hevo makes the process seamless and cost-effective.
Check out why Hevo is best:
- Easy Integration: Connect and migrate data into BigQuery without any coding.
- Auto-Schema Mapping: Automatically map schemas to ensure smooth data transfer.
- In-Built Transformations: Transform your data on the fly with Hevo’s powerful transformation capabilities.
- 150+ Data Sources: Access data from over 150 sources, including 60+ free sources.
Join 2000+ happy customers like Whatfix and Thoughtspot, who’ve streamlined their data operations. See why Hevo is the #1 choice for building modern data stacks.
Get Started with Hevo for FreeWhat are the Key Features of Google BigQuery?
Why did Google release BigQuery and why would you use it instead of a more established data warehouse solution?
- Ease of Implementation: Building your own is expensive, time-consuming, and difficult to scale. With BigQuery, you need to load data first and pay only for what you use.
- Speed: It processes billions of rows in seconds and handles the real-time analysis of streaming data.
What Is the Google BigQuery Architecture?
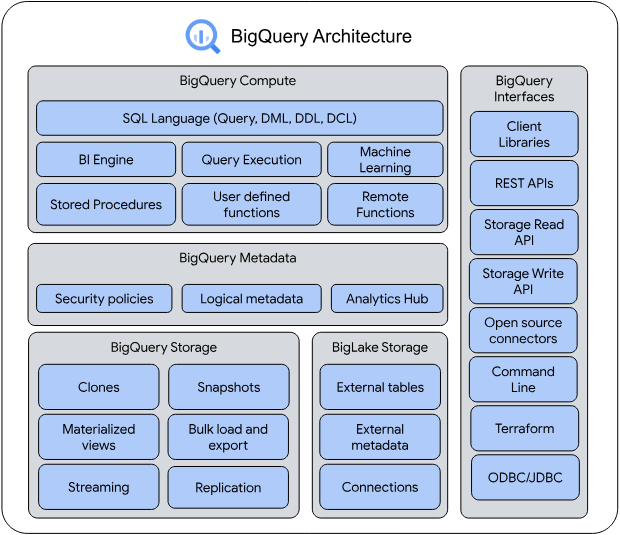
BigQuery architecture is based on Dremel technology. Dremel is a tool used in Google for about 10 years.
- Dremel: BigQuery architecture dynamically apportions slots to queries on an as-needed basis, maintaining fairness amongst multiple users who are all querying at once. A single user can get thousands of slots to run their queries. It takes more than just a lot of hardware to make your queries run fast. BigQuery requests are powered by the Dremel query engine.
- Colossus: BigQuery architecture relies on Colossus, Google’s latest generation distributed file system. Each Google data center has its own Colossus cluster, and each Colossus cluster has enough disks to give every BigQuery user thousands of dedicated disks at a time. Colossus also handles replication, recovery (when disks crash), and distributed management.
- Jupiter Network: It is the internal data center network that allows BigQuery to separate storage and compute.
Data Model/Storage
- Columnar storage.
- Nested/Repeated fields.
- No Index: Single full table scan.
Query Execution
- The query is implemented in tree architecture.
- The query is executed using tens of thousands of machines over a fast Google network.

What Is BigQuery’s Columnar Database?
- Google BigQuery architecture uses column-based storage or columnar storage structure that helps it achieve faster query processing with fewer resources. It is the main reason why Google BigQuery handles large datasets quantities and delivers excellent speed.
- Row-based storage structure is used in relational databases where data is stored in rows because it is an efficient way of storing data for transactional databases. Storing data in columns is efficient for analytical purposes because it needs a faster data reading speed.
- Suppose a database has 1000 records or 1000 columns of data. If we store data in a row-based structure, then querying only 10 rows out of 1000 will take more time as it will read all the 1000 rows to get 10 rows in the query output.
- But this is not the case in Google BigQuery’s columnar database, where all the data is stored in columns instead of rows.
- The columnar database will process only 100 columns in the interest of the query, which in turn makes the overall query processing faster.
The Google Ecosystem

Google BigQuery is a cloud data warehouse that is a part of Google Cloud Platform (GCP) which means it can easily integrate with other Google products and services.
Google Cloud Platforms is a package of many Google services used to store data such as Google Cloud Storage, Google Bigtable, Google Drive, databases, and other data processing tools.
Google BigQuery can process all the data stored in these other Google products. Google BigQuery uses standard SQL queries to create and execute machine learning models and integrate with other business intelligence tools like Looker and Tableau.
Google BigQuery Comparison with Other Databases and Data Warehouses
Here, you will be looking at how Google BigQuery is different from other databases and data Warehouses:
1) Comparison with MapReduce and NoSQL
MapReduce vs. Google BigQuery
| MapReduce | BigQuery |
|
|
NoSQL Datastore vs. Google BigQuery
| NoSQL Datastore | BigQuery |
|
|
2) Comparison with Redshift and Snowflake
| Name | Redshift | BigQuery | Snowflake |
| Description | Large-scale data warehouse service for use with business intelligence tools | Large-scale data warehouse service with append-only tables | Cloud-based data warehousing service for structured and semi-structured data |
| Primary database model | Relational DBMS | Relational DBMS | Relational DBMS |
| Developer | Amazon | Snowflake Computing | |
| XML support | No | No | Yes |
| APIs and other access methods | JDBC
ODBC | RESTfull HTTP/JSON API | CLI Client
JDBC ODBC |
| Supported programming languages | All languages supporting JDBC/ODBC | .Net, Java, JavaScript, Objective-C, PHP, Python. | JavaScript (Node.js)
Python |
| Partitioning methods | Sharding | None | Yes |
| MapReduce | No | No | No |
| Concurrency | Yes | Yes | Yes |
| Transaction concepts | ACID | No | ACID |
| Durability | Yes | Yes | Yes |
| In-memory capabilities | Yes | No | No |
| User concepts | Fine-grained access rights according to SQL-standard | Access privileges (owner, writer, reader) for whole datasets, not for individual tables | Users with fine-grained authorization concepts, user roles and pluggable authentication |
Some important considerations about these comparisons:
- If you have a reasonable volume of data, say, dozens of terabytes that you rarely use to perform queries and it’s acceptable for you to have query response times of up to a few minutes when you use, then Google BigQuery is an excellent candidate for your scenario.
- If you need to analyze a big amount of data (e.g.: up to a few terabytes) by running many queries which should be answered each very quickly — and you don’t need to keep the data available once the analysis is done, then an on-demand cloud solution like Amazon Redshift is a great fit.
But keep in mind that differently from Google BigQuery, Redshift does need to be configured and tuned in order to perform well. - BigQuery architecture is good enough if not to take into account the speed of data updating. Compared to Redshift, Google BigQuery only supports hourly syncs as its fastest frequency update. This made us choose Redshift, as we needed the solution with the support of close to real-time data integration.
Key Concepts of Google BigQuery
Now, you will get to know about the key concepts associated with Google BigQuery:
1) Working
BigQuery is a data warehouse, implying a degree of centralization. The query we demonstrated in the previous section was applied to a single dataset.
However, the benefits of BigQuery become even more apparent when we do joins of datasets from completely different sources or when we query against data that is stored outside BigQuery.
If you’re a power user of Sheets, you’ll probably appreciate the ability to do more fine-grained research with data in your spreadsheets. It’s a sensible enhancement for Google to make, as it unites BigQuery with more of Google’s own existing services. Previously, Google made it possible to analyse Google Analytics data in BigQuery.
2) Querying
Google BigQuery Architecture supports SQL queries and supports compatibility with ANSI SQL 2011. BigQuery SQL support has been extended to support nested and repeated field types as part of the data model.
For example, you can use GitHub public dataset and issue the UNNEST command. It lets you iterate over a repeated field.
SELECT
name, count(1) as num_repos
FROM
`bigquery-public-data.github_repos.languages`, UNNEST(language)
GROUP BY name
ORDER BY num_repos
DESC limit 10A) Interactive Queries
Google BigQuery architecture supports interactive querying of datasets and provides you with a consolidated view of these datasets across projects that you can access. Features like saving as and shared ad-hoc, exploring tables and schemas, etc. are provided by the console.

B) Automated Queries
You can automate the execution of your queries based on an event and cache the result for later use. You can use Airflow API to orchestrate automated activities. For simple orchestrations, you can use corn jobs.
C) Query Optimization
Each time a Google BigQuery executes a query, it executes a full-column scan. It doesn’t support indexes. As you know, the performance and query cost of Google BigQuery Architecture is dependent on the amount of data scanned during a query, you need to design your queries to reference the column that is strictly relevant to your query.
When you are using data partitioned tables, make sure that only the relevant partitions are scanned.

D) External sources
With federated data sources, you can run queries on the data that exists outside of your Google BigQuery. But this method has performance implications. You can also use query federation to perform the ETL process from an external source to Google BigQuery.
E) User-defined functions
Google BigQuery supports user-defined functions for queries that can exceed the complexity of SQL. User-defined functions allow you to extend the built-in SQL functions easily. It is written in JavaScript. It can take a list of values and then return a single value.
F) Query sharing
Collaborators can save and share the queries between the team members. Data exploration exercise, getting desired speed on a new dataset or query pattern becomes a cakewalk with it.
3) ETL/Data Load
There are various approaches to loading data to BigQuery. In case you are moving data from Google Applications – like Google Analytics to a data warehouse, Google Adwords, or even collecting responses through tools like Google Forms or its Google Form alternatives– Google provides a robust BigQuery Data Transfer Service. This is Google’s own intra-product data migration tool.
Data load from other data sources – databases, cloud applications, and more can be accomplished by deploying engineering resources to write custom scripts.
The broad steps would be to extract data from the data source, transform it into a format that BigQuery accepts, upload this data to Google Cloud Storage (GCS) and finally load this to Google BigQuery from GCS.
A few examples of how to perform this can be found here –> PostgreSQL to BigQuery and SQL Server to BigQuery
A word of caution though – custom coding scripts to move data to Google BigQuery is both a complex and cumbersome process. A third-party data pipeline platform such as Hevo can make this a hassle-free process for you.
4) Pricing Model
| Category | Price | Note |
| Storage Cost | $0.020 per GB per month | |
| Query Cost | $5 per TB | 1st TB per month is free |
A) Google BigQuery Storage Cost
- Active – Monthly charge for stored data modified within 90 days.
- Long-term – Monthly charge for stored data that have not been modified within 90 days. This is usually lower than the earlier one.
B) Google BigQuery Query Cost
- On-demand – Based on data usage.
- Flat rate – Fixed monthly cost, ideal for enterprise users.
Free usage is available for the below operations:
- Loading data (network pricing policy applicable in case of inter-region).
- Copying data.
- Exporting data.
- Deleting datasets.
- Metadata operations.
- Deleting tables, views, and partitions.
View Google BigQuery pricing plans in detail by visiting the official website.
5) Maintenance
Google has managed to solve a lot of common data warehouse concerns by throwing order of magnitude of hardware at the existing problems and thus eliminating them altogether. Unlike Amazon Redshift, running VACUUM in Google BigQuery is not an option.
Google BigQuery is specifically architected without the need for the resource-intensive VACUUM operation that is recommended for Redshift. BigQuery Pricing is way different compared to the redshift.
6) Security
The fastest hardware and most advanced software are of little use if you can’t trust them with your data. BigQuery’s security model is tightly integrated with the rest of Google’s Cloud Platform, so it is possible to take a holistic view of your data security.
BigQuery uses Google’s Identity and Access Management (IAM) access control system to assign specific permissions to individual users or groups of users.
BigQuery also ties in tightly with Google’s Virtual Private Cloud (VPC) policy controls, which can protect against users who try to access data from outside your organization, or who try to export it to third parties.
7) Interaction
A) Web User Interface
- Run queries and examine results.
- Manage databases and tables.
- Save queries and share them across the organization for re-use.
- Detailed Query history.
B) Visualize Data Studio
- View BigQuery results with charts, pivots, and dashboards.
C) API
- A programmatic way to access Google BigQuery.
D) Service Limits for Google BigQuery
- The concurrent rate limit for on-demand, interactive queries: 50.
- Daily query size limit: Unlimited by default.
- Daily destination table update limit: 1,000 updates per table per day.
- Query execution time limit: 6 hours.
- A maximum number of tables referenced per query: 1,000.
- Maximum unresolved query length: 256 KB.
- Maximum resolved query length: 12 MB.
- The concurrent rate limit for on-demand, interactive queries against Cloud Big table external data sources: 4.
E) Integrating with Tensorflow
BigQuery has a new feature BigQuery ML that let you create and use a simple machine learning (ML) model as well as deep learning prediction with the TensorFlow model. This is the key technology to integrate the scalable data warehouse with the power of ML.
The solution enables a variety of smart data analytics, such as logistic regression on a large dataset, similarity search, and recommendation on images, documents, products, or users, by processing feature vectors of the contents. Or you can even run TensorFlow model prediction inside BigQuery.


9) Performance
Google BigQuery rose from Dremel, Google’s distributed query engine. Dremel held the capability to handle terabytes of data in seconds flat by leveraging distributed computing within a serverless BigQuery Architecture.
This BigQuery architecture allows it to process complex queries with the help of multiple servers in parallel to significantly improve processing speed. In the following sections, you will take a look at the 4 critical components of Google BigQuery performance:
Tree Architecture

BigQuery architecture and Dremel can scale to thousands of machines by structuring computations as an execution tree. A root server receives an incoming query and relays it to branches, also known as mixers, which modify incoming queries and deliver them to leaf nodes, also known as slots.
Working in parallel, the leaf nodes handle the nitty-gritty of filtering and reading the data. The results are then moved back down the tree where the mixers accumulate the results and send them to the root as the answer to the query.
Serverless Service
In most data warehouse environments, organizations have to specify and commit to the server hardware on which computations are run. Administrators have to provision for performance, elasticity, security, and reliability.
A serverless model can come in handy in solving this constraint. In a serverless model, processing can automatically be distributed over a large number of machines working simultaneously.
SQL and Programming Language Support

Users can avail BigQuery architecture through standard-SQL, which many users are quite familiar with. Google BigQuery also has client libraries for writing applications that can access data in Python, Java, Go, C#, PHP, Ruby, and Node.js.
Real-time Analytics
Google BigQuery can also run and process reports on real-time data by using other GCP resources and services. Data warehouses can provide support for analytics after data from multiple sources is accumulated and stored- which can often happen in batches throughout the day.
10) Use Cases
You can use Google BigQuery data warehouse in the following cases:
- Use it when you have queries that run more than five seconds in a relational database. The idea of BigQuery is running complex analytical queries, which means there is no point in running queries that are doing simple aggregation or filtering. BigQuery is suitable for “heavy” queries, those that operate using a big set of data.
The bigger the dataset, the more you’re likely to gain performance by using BigQuery. The dataset that I used was only 330 MB (megabytes, not even gigabytes). - BigQuery is good for scenarios where data does not change often and you want to use the cache, as it has a built-in cache. What does this mean? If you run the same query and the data in tables are not changed (updated), BigQuery will just use cached results and will not try to execute the query again. Also, BigQuery is not charging money for cached queries.
- You can also use BigQuery when you want to reduce the load on your relational database. Analytical queries are “heavy” and overusing them under a relational database can lead to performance issues. So, you could eventually be forced to think about scaling your server.
However, with BigQuery you can move these running queries to a third-party service, so they would not affect your main relational database.
Also, take a look at BigQuery Cached Query Results to get a better understanding of your BigQuery data.
Conclusion
BigQuery is a sophisticated mature service that has been around for many years. It is feature-rich, economical, and fast. BigQuery integration with Google Drive and the free Data Studio visualization toolset is very useful for comprehension and analysis of Big Data and can process several terabytes of data within a few seconds. This service needs to deploy across existing and future Google Cloud Platform (GCP) regions. Serverless is certainly the next best option to obtain maximized query performance with minimal infrastructure cost.
If you want to integrate your data from various sources and load it in Google BigQuery, then try Hevo.
Sign up for a 14-day free trial and simplify your data integration process. Check out the pricing details to understand which plan fulfills all your business needs.
Frequently Asked Questions (FAQs)
Q1) What is Google BigQuery used for?
Google BigQuery is a cloud-based data warehouse used for analyzing and processing large datasets quickly. It’s ideal for running complex SQL queries on massive datasets without needing extra infrastructure.
Q2) What is the difference between SQL and BigQuery?
SQL is a query language used for managing databases, while BigQuery is a data warehouse service that uses SQL to analyze big data in the cloud. BigQuery is optimized for large-scale data processing and storage, unlike traditional SQL databases.
Q3) Why is BigQuery so popular?
BigQuery is popular for its speed, scalability, and cost-efficiency in handling big data. It’s serverless, meaning no infrastructure management is needed, and it integrates well with other Google Cloud services.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





