


Amazon Redshift is a petabyte-scale Cloud-based Data Warehouse service. It is optimized for datasets ranging from a hundred gigabytes to a petabyte can effectively analyze all your data by allowing you to leverage its seamless integration support for Business Intelligence tools Redshift offers a very flexible pay-as-you-use pricing model, which allows the customers to pay for the storage and the instance type they use. Increasingly, more and more businesses are choosing to adopt Redshift for their warehousing needs.
In this article, you will gain information about one of the key aspects of building your Redshift Data Warehouse: Loading Data to Redshift. You will also gain a holistic understanding of Amazon Redshift, its key features, and the different methods for loading Data to Redshift. Read along to find out in-depth information about Loading Data to Redshift.
Table of Contents
What is Redshift?
Amazon Redshift is a cloud-based, fully managed data warehousing service from AWS. It uses SQL-based tools to query and analyze large amounts of data quickly. Redshift is highly scalable and secure and integrates well with other AWS services.
Key Features:
- Massively Parallel Processing (MPP): Splits queries among a multitude of nodes to speed up processing.
- Columnar Storage: Data is stored in columns for the optimization of read performance for analytics.
- Scalability: Easily scales up or down by adding or removing nodes.
- Affordable: Pay-as-you-go pricing allows compression and scaling down the storage cost.
- Security: Can support encryption, VPC, and compliance certifications.
Looking for the best ETL tools to connect your data sources? Rest assured, Hevo’s no-code platform helps streamline your ETL process. Try Hevo and equip your team to:
- Integrate data from 150+ sources(60+ free sources).
- Simplify data mapping with an intuitive, user-friendly interface.
- Instantly load and sync your transformed data into your desired destination.
Try Hevo and join a growing community of 2000+ data professionals who rely on us for seamless and efficient migrations.
Get Started with Hevo for FreeMethods for Loading Data to Redshift
There are multiple ways of performing Redshift ETL from various sources. On a broad level, data loading mechanisms to Redshift can be categorized into the below methods:
Method 1: Loading an Automated Data Pipeline Platform to Redshift Using Hevo’s No-code Data Pipeline
Hevo’s Automated No Code Data Pipeline can help you move data from 150+ sources swiftly to Amazon Redshift. You can set up the Redshift Destination on the fly, as part of the Pipeline creation process, or independently. The ingested data is first staged in Hevo’s S3 bucket before it is batched and loaded to the Amazon Redshift Destination. Hevo can also be used to perform smooth transitions to Redshift such as DynamoDB load data from Redshift and to load data from S3 to Redshift.
Hevo’s fault-tolerant architecture will enrich and transform your data in a secure and consistent manner and load it to Redshift without any assistance from your side. You can entrust us with your data transfer process by both ETL and ELT processes to Redshift and enjoy a hassle-free experience.
Hevo Data focuses on two simple steps to get you started:
Step 1: Authenticate Source
- Connect Hevo Data with your desired data source in just a few clicks. You can choose from a variety of sources such as MongoDB, JIRA, Salesforce, Zendesk, Marketo, Google Analytics, Google Drive, etc., and a lot more.
Step 2: Configure Amazon Redshift as the Destination
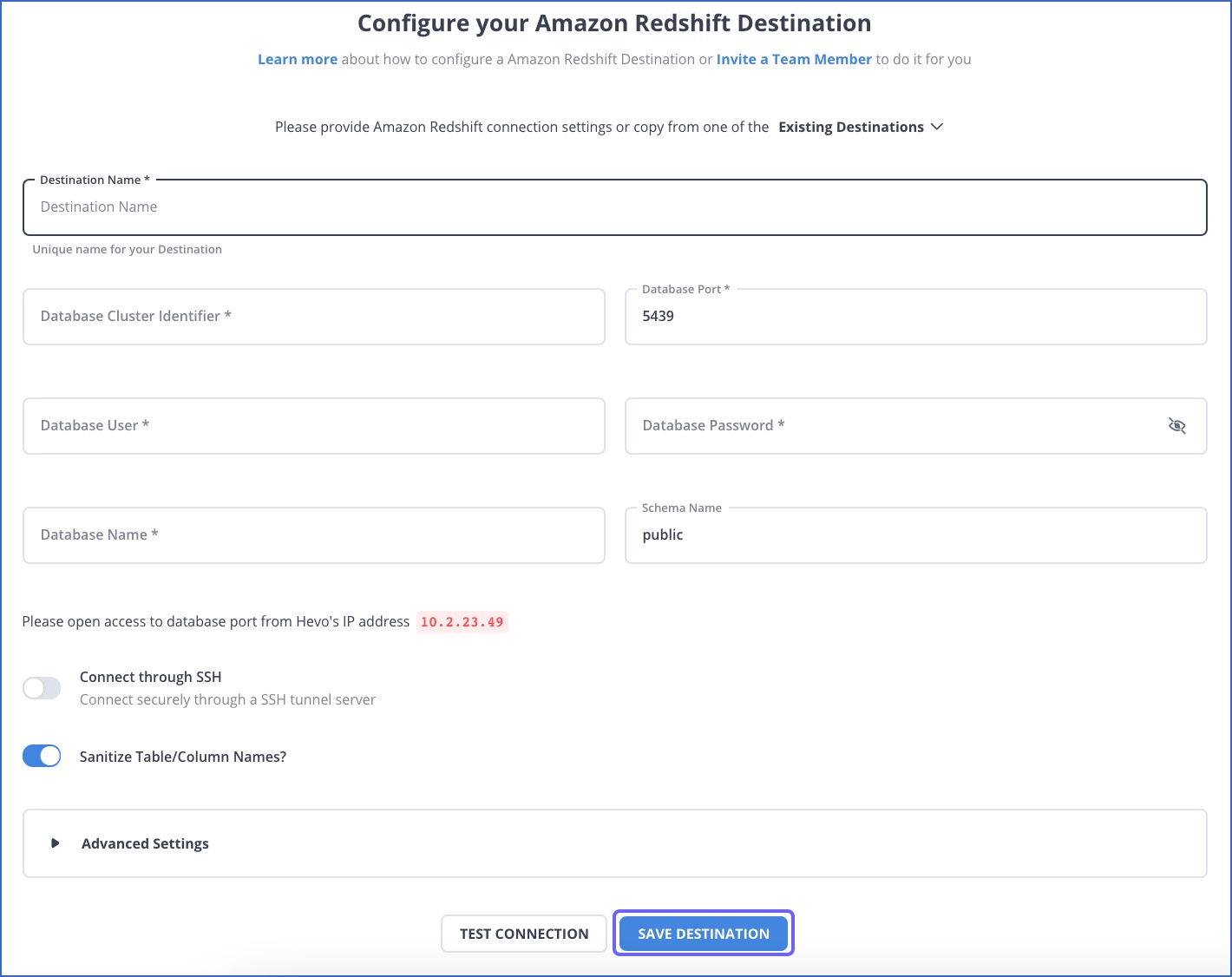
You can carry out the following steps to configure Amazon Redshift as a Destination in Hevo:
- Click on the “DESTINATIONS” option in the Asset Palette.
- Click the “+ CREATE” option in the Destinations List View.
- On the Add Destination page, select the Amazon Redshift option.
- In the Configure your Amazon Redshift Destination page, specify the following: Destination Name, Database Cluster Identifier, Database Port, Database User, Database Password, Database Name, Database Schema.
- Click the Test Connection option to test connectivity with the Amazon Redshift warehouse.
- After the is successful, click the “SAVE DESTINATION” button.
Here are more reasons to try Hevo:
- Integrations: Hevo’s fault-tolerant Data Pipeline offers you a secure option to unify data from 150+ sources (including 60+ free sources) and store it in Redshift or any other Data Warehouse of your choice. This way you can focus more on your key business activities and let Hevo take full charge of the Data Transfer process.
- Schema Management: Hevo takes away the tedious task of schema management & automatically detects the schema of incoming data and maps it to your Redshift schema.
- Quick Setup: Hevo with its automated features, can be set up in minimal time. Moreover, with its simple and interactive UI, it is extremely easy for new customers to work on and perform operations.
- Hevo Is Built To Scale: As the number of sources and the volume of your data grows, Hevo scales horizontally, handling millions of records per minute with very little latency.
- Live Support: The Hevo team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.
With continuous Real-Time data movement, Hevo allows you to assemble data from multiple data sources and seamlessly load it to Redshift with a no-code, easy-to-setup interface.
Method 2: Loading Data to Redshift using the Copy Command
The Redshift COPY command is the standard way of loading bulk data TO Redshift. COPY command can use the following sources for loading data.
Other than specifying the locations of the files from where data has to be fetched, the COPY command can also use manifest files which have a list of file locations. It is recommended to use this approach since the COPY command supports the parallel operation and copying a list of small files will be faster than copying a large file. This is because, while loading data from multiple files, the workload is distributed among the nodes in the cluster.
COPY command accepts several input file formats including CSV, JSON, AVRO, etc.
It is possible to provide a column mapping file to configure which columns in the input files get written to specific Redshift columns.
COPY command also has configurations to simple implicit data conversions. If nothing is specified the data types are converted automatically to Redshift target tables’ data type.
The simplest COPY command for loading data from an S3 location to a Redshift target table named product_tgt1 will be as follows. A redshift table should be created beforehand for this to work.
copy product_tgt1
from 's3://productdata/product_tgt/product_tgt1.txt'
iam_role 'arn:aws:iam::<aws-account-id>:role/<role-name>'
region 'us-east-2';Method 3: Loading Data to Redshift using Insert Into Command
Redshift’s INSERT INTO command is implemented based on the PostgreSQL. The simplest example of the INSERT INTO command for inserting four values into a table named employee_records is as follows.
INSERT INTO employee_records(emp_id,department,designation,category)
values(1,’admin’,’assistant’,’contract’);It can perform insertions based on the following input records.
- The above code snippet is an example of inserting single row input records with column names specified with the command. This means the column values have to be in the same order as the provided column names.
- An alternative to this command is the single row input record without specifying column names. In this case, the column values are always inserted into the first n columns.
- INSERT INTO command also supports multi-row inserts. The column values are provided with a list of records.
- This command can also be used to insert rows based on a query. In that case, the query should return the values to be inserted into the exact columns in the same order specified in the command.
Even though the INSERT INTO command is very flexible, it can lead to surprising errors because of the implicit data type conversions. This command is also not suitable for the bulk insert of data.
Method 4: Loading Data to Redshift using AWS Services
AWS provides a set of utilities for loading data To Redshift from different sources. AWS Glue and AWS Data pipeline are two of the easiest to use services for loading data from AWS table.
AWS Data Pipeline
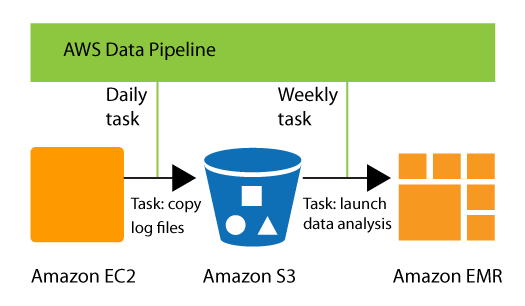
AWS data pipeline is a web service that offers extraction, transformation, and loading of data as a service. The power of the AWS data pipeline comes from Amazon’s elastic map-reduce platform. This relieves the users of the headache to implement a complex ETL framework and helps them focus on the actual business logic.
AWS Data pipeline offers a template activity called RedshiftCopyActivity that can be used to copy data from different kinds of sources to Redshift. RedshiftCopyActivity helps to copy data from the following sources.
RedshiftCopyActivity has different insert modes – KEEP EXISTING, OVERWRITE EXISTING, TRUNCATE, APPEND.


KEEP EXISTING and OVERWRITE EXISTING considers the primary key and sort keys of Redshift and allows users to control whether to overwrite or keep the current rows if rows with the same primary keys are detected.
AWS Glue
AWS Glue is an ETL tool offered as a service by Amazon that uses an elastic spark backend to execute the jobs. AWS Glue has the ability to discover new data whenever they come to the AWS ecosystem and store the metadata in catalogue tables.
Internally Glue uses the COPY and UNLOAD command to accomplish copying data to Redshift. For executing a copying operation, users need to write a glue script in its own domain-specific language.
Glue works based on dynamic frames. Before executing the copy activity, users need to create a dynamic frame from the data source. Assuming data is present in S3, this is done as follows.
connection_options = {"paths": [ "s3://product_data/products_1", "s3://product_data/products_2"]}
df = glueContext.create_dynamic_frame_from_options("s3_source", connection-options)The above command creates a dynamic frame from two S3 locations. This dynamic frame can then be used to execute a copy operation as follows.
connection_options = {
"dbtable": "redshift-target-table",
"database": "redshift-target-database",
"aws_iam_role": "arn:aws:iam::account-id:role/role-name"
}
glueContext.write_dynamic_frame.from_jdbc_conf(
frame = s3_source,
catalog_connection = "redshift-connection-name",
connection_options = connection-options,
redshift_tmp_dir = args["TempDir"])The above method of writing custom scripts may seem a bit overwhelming at first. Glue can also auto-generate these scripts based on a web UI if the above configurations are known.
Benefits of Loading Data to Redshift
Some of the benefits of loading data to Redshift are as follows:
1) It offers significant Query Speed Upgrades
Amazon’s Massively Parallel Processing allows BI tools that use the Redshift connector to process multiple queries across multiple nodes at the same time, reducing workloads.
2) It focuses on Ease of use and Accessibility
MySQL (and other SQL-based systems) continue to be one of the most popular and user-friendly database management interfaces. Its simple query-based system facilitates platform adoption and acclimation. Instead of creating a completely new interface that would require significant resources and time to learn, Amazon chose to create a platform that works similarly to MySQL, and it has worked extremely well.
3) It provides fast Scaling with few Complications
Redshift is a cloud-based application that is hosted directly on Amazon Web Services, the company’s existing cloud infrastructure. One of the most significant advantages this provides Redshift is a scalable architecture that can scale in seconds to meet changing storage requirements.
4) It keeps Costs relatively Low
Amazon Web Services bills itself as a low-cost solution for businesses of all sizes. In line with the company’s positioning, Redshift offers a similar pricing model that provides greater flexibility while enabling businesses to keep a closer eye on their data warehousing costs. This pricing capability stems from the company’s cloud infrastructure and its ability to keep workloads to a minimum on the majority of nodes.
5) It gives you Robust Security Tools
Massive data sets frequently contain sensitive data, and even if they do not, they contain critical information about their organisations. Redshift provides a variety of encryption and security tools to make warehouse security even easier.
These all features make Redshift one of the best Data Warehouses to securely and efficiently load data in. A No-Code Data Pipeline such as Hevo Data provides you with a smooth and hassle-free process for loading data to Redshift.
Conclusion
The above sections detail different ways of copying data to Redshift. The first two methods of COPY and INSERT INTO command use Redshift’s native ability, while the last two methods build abstraction layers over the native methods. Other than this, it is also possible to build custom ETL tools based on the Redshift native functionality. AWS’s own services have some limitations when it comes to data sources outside the AWS ecosystem. All of this comes at the cost of time and precious engineering resources.
Visit our Website to Explore HevoHevo Data is the only real-time ELT No-code Data Pipeline platform that cost-effectively automates data pipelines that are flexible to your needs. With integration with 150+ Data Sources such as PostgreSQL, MySQL, and MS SQL Server, we help you not only export data from sources & load data to the destinations but also transform & enrich your data, & make it analysis-ready.
Want to take Hevo for a spin? Sign Up for a 14-day free trial and experience the feature-rich Hevo suite firsthand.
Frequently Asked Questions
1. What is the preferred way to load data into Redshift is through?
The preferred way to load data into redshift is by using automated tools like Hevo.
2. How do I transfer data to Redshift?
Data can be transferred using:
–S3 to Redshift (using COPY command)
-AWS Data Pipeline
-Hevo
-Redshift Data API
3. How do you add data to a Redshift table?
Use the INSERT statement for small datasets or the COPY command for large datasets from external sources like S3 or Amazon DynamoDB.




