



Amazon Aurora PostgreSQL is a relational database engine that is fully managed, PostgreSQL-compatible, and ACID-compliant. It combines the speed and reliability of high-end commercial databases with the simplicity and cost-effectiveness of open-source databases.
- Amazon Aurora PostgreSQL is a PostgreSQL drop-in replacement that makes it simple and cost-effective to set up, run, and scale new and existing PostgreSQL deployments, allowing you to focus on your business and applications.
- Amazon RDS handles routine database tasks such as provisioning, patching, backup, recovery, failure detection, and repair for Aurora.
- Amazon RDS also offers one-click migration tools for converting your existing Amazon RDS for PostgreSQL applications to Amazon Aurora PostgreSQL.
- AWS Aurora PostgreSQL is compatible with a wide range of industry standards. Under a completed Business Associate Agreement (BAA) with AWS
- For example, you can use Aurora PostgreSQL databases to build HIPAA-compliant applications and store healthcare-related information, including protected health information (PHI).
Table of Contents
Prerequisites
- The database version is 9.4, 9.5, 9.6, or 10.0, and an Amazon Aurora PostgreSQL instance is created.
- The Amazon Aurora PostgreSQL instance’s Public accessibility option is set to Yes. This ensures that DTS has Internet access to the Amazon Aurora PostgreSQL Instance.
Migrating your data from Amazon Aurora PostgreSQL doesn’t have to be complex. Relax and go for a seamless migration using Hevo’s no-code platform. With Hevo, you can:
- Effortlessly extract data from 150+ connectors.
- Tailor your data to Postgres’s needs with features like drag-and-drop and custom Python scripts.
- Achieve lightning-fast data loading into Amazon Aurora PostgreSQL, making your data analysis-ready.
Try to see why customers like EdApp and Harmoney have upgraded to a powerful data and analytics stack by incorporating Hevo!
Get Started with Hevo for FreeWhat is Amazon Aurora?
Amazon Aurora is a popular database engine with a robust feature set that can seamlessly import databases from MySQL and PostgreSQL. It provides enterprise-level performance while automating all traditional database tasks.
As a result, you won’t have to worry about manually managing processes such as data backups, hardware provisioning, software updates, and others.
Key Features of Amazon Aurora
The following features contribute to Amazon Aurora’s popularity:
- Exceptional Performance: Amazon employs software and hardware tweaks that enable the Aurora database engine to take advantage of Amazon’s computing, memory, and network resources. As a result, Aurora outperforms its competitors significantly.
- Scalability: Amazon Aurora will automatically scale from a minimum of 10 GB storage to 64 TB storage in increments of 10 GB at a time, based on your database usage.
- Data Backups: Amazon Aurora provides automatic, incremental, and continuous backups that do not impair database performance.
- High Availability and Durability: The health of your Amazon Aurora database and underlying Amazon Elastic Compute Cloud (Amazon EC2) instance is constantly monitored by Amazon RDS. In the event of a database failure, Amazon RDS will restart the database and related activities automatically.
- Highly Secure: Aurora is linked with AWS Identity and Access Management (IAM), giving you control over the actions your AWS IAM users and groups can do on individual Aurora resources (e.g., DB Instances, DB Snapshots, DB Parameter Groups, DB Event Subscriptions, DB Options Groups).
- Fully Managed: Your database will be kept up to date with the newest patches thanks to Amazon Aurora. DB Engine Version Management allows you to choose whether and when your instance is patched. With a few clicks, you may manually stop and start an Amazon Aurora database.
- Developer Productivity: Aurora provides machine learning capabilities directly from the database, allowing you to use the traditional SQL programming language to add ML-based predictions to your applications.
What is PostgreSQL?

PostgreSQL is well-known in the market for its ability to handle complex, high-volume data operations. PostgreSQL has a few more features and is extensible when compared to other Database Management Systems. It allows you to define index types, data types, and functional languages in addition to storing information in the form of tables and columns.
PostgreSQL is unique in that it is Object-Relational, ACID-compliant supports NoSQL and is highly concurrent. Let’s take a look at some additional features that make PostgreSQL a viable Database Management System for your requirements.
Key Features of PostgreSQL
Here are a few notable key features of PostgreSQL:
- Customizable: PostgreSQL can be customized by creating plugins to make the Database Management System meet your needs. PostgreSQL also allows you to include custom functions written in other programming languages such as Java, C, C++, and others.
- Long Tradition: PostgreSQL has been around for over 30 years, having first been released in 1988.
- MVCC Characteristics: PostgreSQL was the first database management system to include Multi-Version Concurrency Control (MVCC) capabilities.
- A Community That Cares: A dedicated community is always available to you. Private, third-party support services are also available. The PostgreSQL Global Development Group is where the community updates the PostgreSQL platform.
- Open-Source: An Object-Relational Database Management System is what this is (ORDBMS). PostgreSQL can now provide Object-Oriented and Relational Database functionality.
Working with Amazon Aurora PostgreSQL
AWS Aurora PostgreSQL is backwards compatible with PostgreSQL 9.6 and PostgreSQL 10. It is extremely simple to configure PostgreSQL with Amazon Aurora, which can improve the throughput and efficiency of database operations.
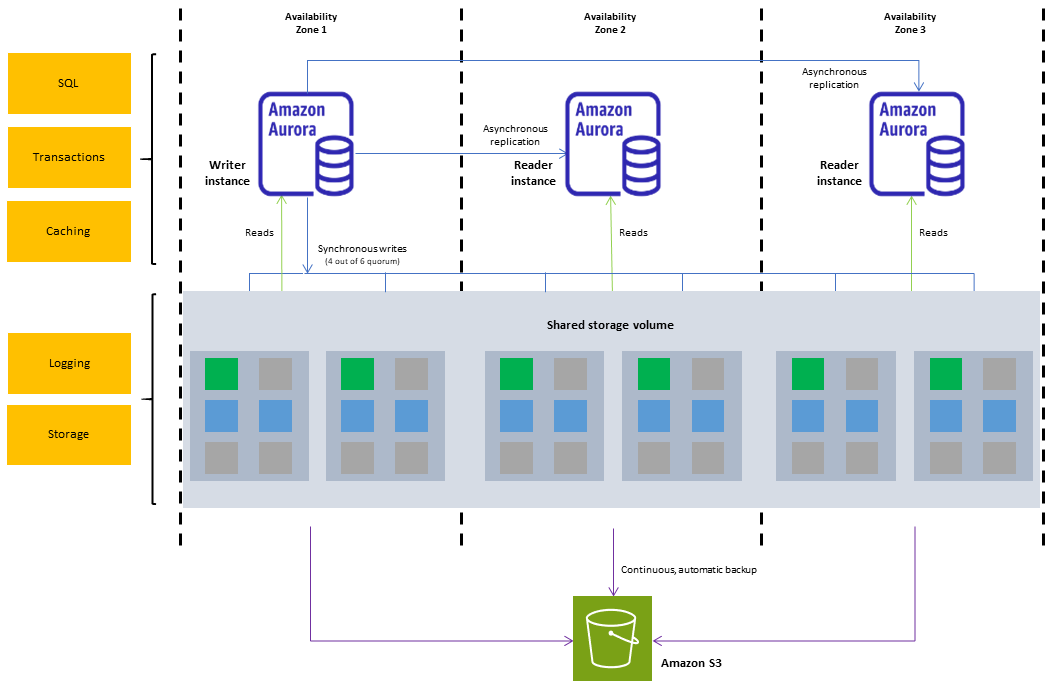
Here are some practices that meet with AWS Aurora PostgreSQL:
- Amazon Aurora PostgreSQL Security
- Data Migration to Amazon Aurora using PostgreSQL Compatibility
- Amazon Aurora PostgreSQL Integration with other AWS services
- Using AWS Aurora PostgreSQL and Machine Learning (ML)
- Using the pg_partman extension to manage PostgreSQL partitions
- Amazon Aurora PostgreSQL with Kerberos



Amazon Aurora PostgreSQL Security
AWS Identity and Access Management are used to control who can perform Amazon RDS management actions on Aurora PostgreSQL DB clusters and DB instances (IAM). When you use IAM credentials to connect to AWS, your AWS account must have IAM policies that grant the permissions required to perform Amazon RDS management operations.
Data Migration to Amazon Aurora using PostgreSQL Compatibility
- Using a snapshot to migrate an RDS for PostgreSQL DB instance: Data can be directly migrated from an RDS for PostgreSQL DB snapshot to an Aurora PostgreSQL DB cluster.
- Using an Amazon Aurora read replica to migrate an RDS for PostgreSQL DB instance: You can also migrate from an RDS for PostgreSQL DB instance by creating an AWS Aurora PostgreSQL read replica of that instance. You can stop replication when the replica lag between the RDS for the PostgreSQL DB instance and the Aurora PostgreSQL read replica is zero. You can now make the Aurora read replica a standalone AWS Aurora PostgreSQL DB cluster for reading and writing.
- Importing data from S3 into AWS Aurora PostgreSQL: Data can be moved by importing it from Amazon S3 into a table in an Aurora PostgreSQL DB cluster.
Amazon Aurora PostgreSQL Integration with other AWS services
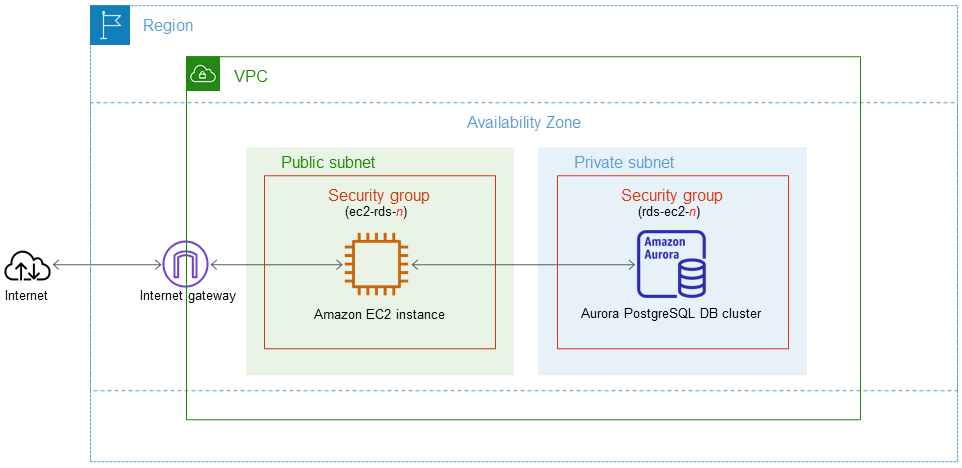
AWS Aurora PostgreSQL with other AWS services, allowing you to extend your Aurora PostgreSQL DB cluster to take advantage of additional AWS Cloud capabilities. AWS services can be used by your Aurora PostgreSQL DB cluster to do the following:
- With Amazon RDS Performance Insights, you can quickly collect, view, and assess performance for your Aurora PostgreSQL DB instances.
- Performance Insights enhances existing Amazon RDS monitoring features by displaying your database’s performance and assisting you in analyzing any issues that affect it.
- Aurora Auto Scaling allows you to automatically add or remove Aurora Replicas.
- Import data from an Amazon S3 bucket into an Aurora PostgreSQL DB cluster, or export data from an Aurora PostgreSQL DB cluster back to an Amazon S3 bucket.
- Using the SQL language, incorporate Machine Learning-based predictions into database applications.
- Amazon Aurora Machine Learning makes use of a highly optimized integration between the Aurora database and the Amazon Web Services (AWS) Machine Learning (ML) services SageMaker and Amazon Comprehend.
- The PostgreSQL oracle few extension, which provides a foreign-data wrapper, can be used to provide easy and efficient access to Oracle databases for Aurora PostgreSQL.
- Integrates Amazon Redshift and AWS Aurora PostgreSQL queries.
Using AWS Aurora PostgreSQL and Machine Learning (ML)
You can incorporate Machine Learning-based predictions into your existing database applications. You do not need to create custom integrations or learn new tools. You can incorporate machine learning processing directly into your SQL query as function calls.
The ML Integration is a quick way to give ML services access to transactional data. To perform Machine Learning operations, you do not need to move the data out of the database. To use the results of Machine Learning operations in your database application, you do not need to convert or reimport them.
You can control who has access to the underlying data and the generated insights using your existing governance policies.
AWS Machine Learning services are managed services that you configure and run in your production environment. Amazon Aurora Machine Learning currently integrates with Amazon Comprehend for sentiment analysis and SageMaker for a wide range of machine learning algorithms.
Using the pg_partman extension to manage PostgreSQL Partitions
Table partitioning in PostgreSQL provides a framework for high-performance data input and reporting. Partitioning is useful for databases that require large amounts of data to be entered quickly.
Partitioning also speeds up queries on large tables. Partitioning allows data to be maintained without affecting the database instance because it requires fewer I/O resources.
To enable the pg_partman extension for a specific database, first, create the partition maintenance schema, then the pg_partman extension, as shown below.
CREATE SCHEMA partman;
CREATE EXTENSION pg_partman WITH SCHEMA partman;Amazon Aurora PostgreSQL with Kerberos
When users connect to your PostgreSQL-powered database cluster, you can use Kerberos Authentication to authenticate them. In this case, your DB instance communicates with AWS Directory Service for Microsoft Active Directory to enable Kerberos Authentication.
AWS Directory Service for Microsoft Active Directory, also known as AWS Managed Microsoft AD, is a cloud-based directory service for Microsoft Active Directory.
Benefits of Amazon Aurora PostgreSQL
Here are a few benefits of AWS Aurora PostgreSQL:
- Amazon Aurora was created specifically for the cloud and has improved Scalability and Speed, which is three times faster than a standard Postgres database.
- Data is automatically replicated across three AWS availability zones, ensuring high availability.
- It also provides fault-tolerant and self-healing storage, instance monitoring, and database recovery in the event of a failure.
- There is no pricing or resource lock-in, the database will scale up and down as needed, and you will only ever pay for what you use.
Amazon Aurora PostgreSQL: Best practices
- Set TCP keepalives aggressively to ensure that longer-running queries that are awaiting a server response are terminated before the read timeout expires if the connection fails.
- To ensure that the Aurora read-only endpoint may properly cycle across read-only nodes on successive connection attempts, increase the Java DNS caching timeouts.
- Set the JDBC connection string’s timeout variables as low as possible. For a brief and long-running queries, use different connection objects.
- To connect to the cluster, use the read and write Aurora endpoints that are supplied.
- To test application response for server-side failures, utilize RDS APIs, and to test application response for client-side failures, use a packet dropping tool.
Conclusion
The article introduced you to Amazon Aurora and PostgreSQL, as well as their key features. Furthermore, the characteristics of both have been explained in this article. The article also listed the major advantages that they can bring to your company.
Sign up for a 14-day free trial and simplify your data integration process. Check out the pricing details to understand which plan fulfills all your business needs.
Frequently Asked Questions
Q1) What is Postgres Aurora?
Postgres Aurora is a fully managed relational database from AWS that is compatible with PostgreSQL. It offers better performance and scalability compared to standard PostgreSQL.
Q2) What is the difference between Postgres and Aurora PostgreSQL?
Aurora PostgreSQL is a version of PostgreSQL provided by AWS, offering faster performance, higher availability, and automatic scaling, while regular PostgreSQL doesn’t have these built-in cloud benefits.
Q3) What is the difference between RDS and Aurora?
RDS supports various databases (PostgreSQL, MySQL, etc.), while Aurora is optimized for performance and scalability, specifically for MySQL and PostgreSQL, offering better speed and fault tolerance.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





