




 Key Takeaways
Key TakeawaysMigrating data from BigQuery to SQL Server can be done in three ways:
Method 1: Using Hevo
Configure BigQuery as your source in Hevo with project, dataset, and table details
Select SQL Server as the destination and enter your server, database, schema, and credentials
Method 2: Using an ODBC Driver
In SQL Server Management Studio, create a Linked Server with the MSDASQL provider and your BigQuery DSN
Enable in-process execution and run queries against your linked BigQuery tables
Method 3: Using a BigQuery Operator
Install the Airflow Google provider and configure your GCP connection in Airflow
Use the BigQueryToMsSqlOperator to copy data from your BigQuery table into SQL Server
Unlock the full potential of your BigQuery data by integrating it seamlessly with SQL Server. With Hevo’s automated pipeline, get data flowing effortlessly—watch our 1-minute demo below to see it in action!
Today’s business landscape is becoming increasingly dependent on data. You need to harness the right tools to simplify the data in your databases and unlock its potential.
Migrating data from BigQuery to SQL Server is a powerful data integration method. SQL Server gives you control over storage procedures, query optimization, and user-defined functions, providing a better analysis of BigQuery data. This article will give you insights on migrating your data from BigQuery to SQL Server.
Let’s look at some methods to load data from BigQuery to SQL Server.
Method 1: Using Hevo to Migrate Data from BigQuery to SQL Server
Hevo offers a fully automated, no-code data pipeline to transfer data from BigQuery to SQL Server. It simplifies the process by automating data replication.
Method 2: Using ODBC Driver to Connect BigQuery to SQL Server
This method involves using an ODBC driver to establish a connection between BigQuery and SQL Server. It requires some technical knowledge for setup and configuration.
Method 3: Transferring Data from BigQuery to SQL Server Using BigQuery Operator
With the BigQuery Operator, you can transfer data directly from BigQuery to SQL Server by using predefined commands in an automated workflow. This method requires familiarity with scripting and BigQuery’s operator functionality.
Table of Contents
Overview of BigQuery

BigQuery is a serverless, cloud-based data warehouse. It assists you in storing, managing, and analyzing your data through machine learning, geospatial analysis, and business intelligence features.
The platform supports data ingestion from other Google services such as Google Sheets, Analytics, and Cloud Storage. You can process data and generate answers using SQL queries to obtain quick and logical insights.
Overview of SQL Server

SQL Server is a database system that stores structured, semi-structured, and unstructured data. It supports languages like Python and helps you extract data from different sources, sync it, and maintain consistency. The database provides controlled access to the data, making SQL Server more secure and ensuring regulatory compliance.
If you are looking for a BigQuery SQL Server tutorial to migrate data, read ahead and learn about methods that will help you in the process.
Method 1: Migrating Data from BigQuery to SQL Server Using Hevo
Prerequisites
- BigQuery Setup:
- Ensure your BigQuery project has at least one dataset and table, with an active billing account linked to ingest incremental data via temporary tables.
- You need Data Viewer, Data Editor, and Job User permissions, along with access to a Google Cloud Storage (GCS) bucket for data replication.
- SQL Server Setup:
- Your SQL Server should be running with the server host’s IP address and DNS port available.
- Grant necessary user privileges on your SQL Server database.
- Hevo User Roles:
- You must have a Team Collaborator, Team Administrator, or Pipeline Administrator role to create the pipeline.
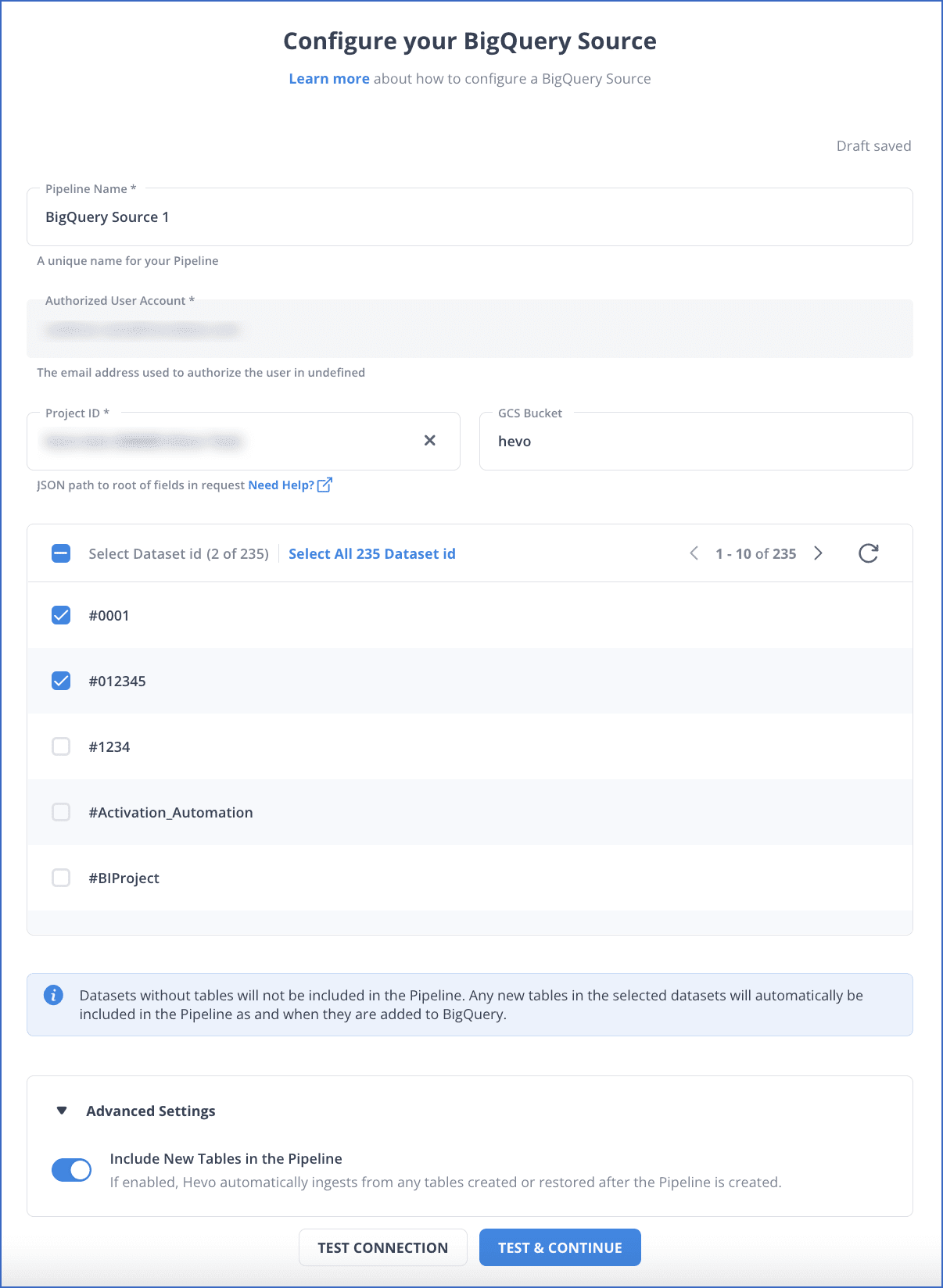
Step 1: Set BigQuery as Your Source
Fill in the required attributes to configure BigQuery as your source.
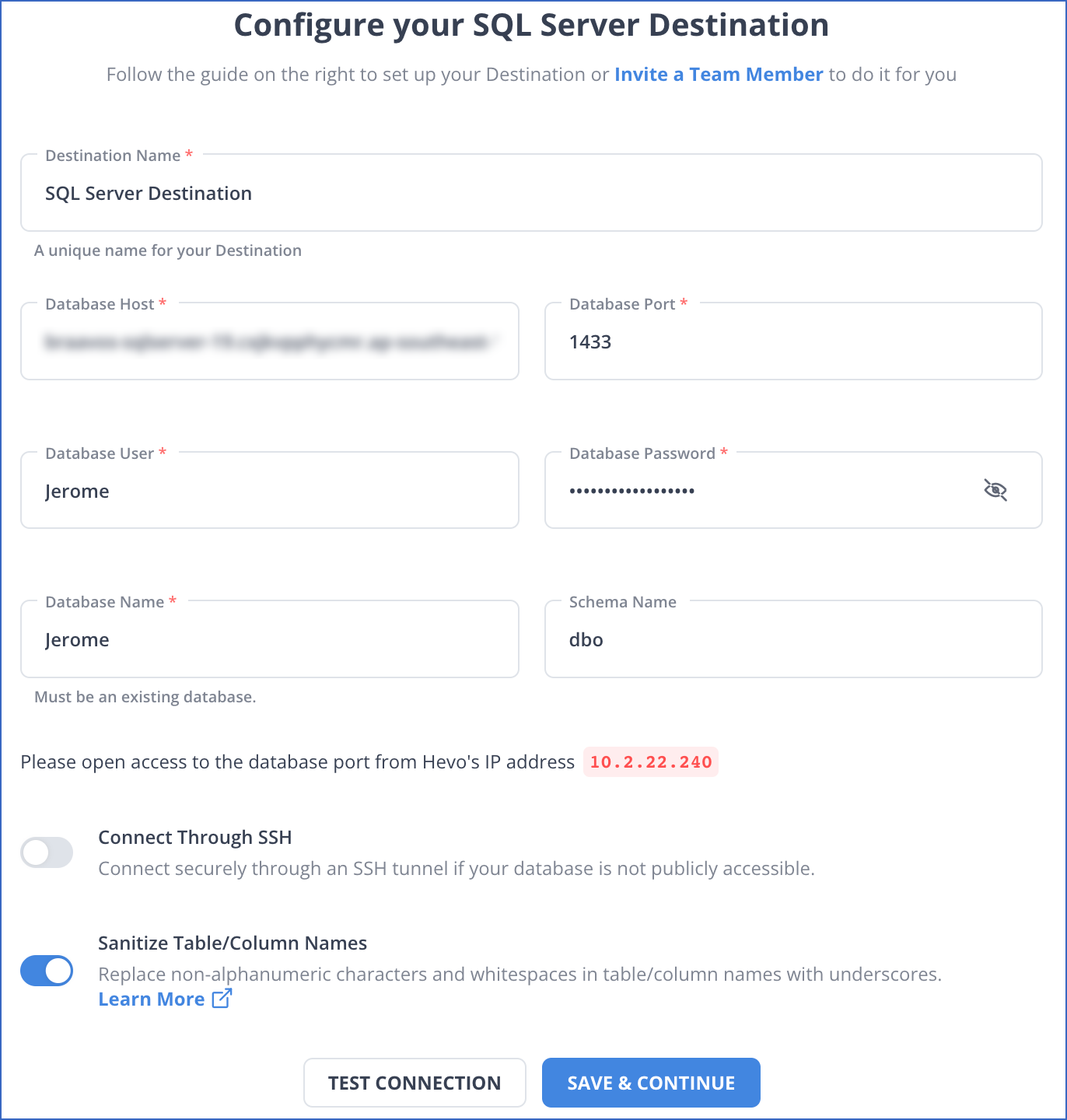
Step 2: Select the SQL Server as Your Destination
You need to configure SQL Server as destination.
Benefits of Using Hevo
- Data Transformation: Hevo’s data integration features, including transformations such as drag-and-drop, enable you to load your data smoothly in the BigQuery SQL Server pipeline.
- Auto Schema Mapping: When performing BigQuery to SQL Server integration, Hevo maps the schema of the data automatically to ensure data compatibility. This feature greatly reduces human intervention.
- Models and Workflow: Hevo assists you in making the data ready for analysis through this in-built intelligent assistant, providing complete control and visibility over the data. This feature is useful when connecting BigQuery to SQL Server, as it speeds up data loading.
Method 2: Connecting BigQuery to SQL Server Using ODBC Driver
You can connect BigQuery to SQL Server using Microsoft SQL Server Management Studio. The Server Management Studio allows you to migrate data from BigQuery to SQL instances through a few steps. A tool called ‘Linked Server’ helps you to execute queries stored in the referenced table on a non-SQL Server.
Prerequisites
1. SQL Server Setup:
- Use Management Studio to create a Linked Server by selecting Server Objects > Linked Servers > New Linked Server.
- Choose Microsoft OLE DB Provider under Other data source and input the ODBC driver connection string for BigQuery.
2. BigQuery Connection:
- Enable Allow in-process for MSDASQL in Linked Server settings and specify the DSN system for BigQuery.
3. ODBC Driver:
- Ensure the ODBC driver is installed and configured to retrieve data from BigQuery tables via SQL Server.
Step 1: Configuring Your SQL Server to Connect with BigQuery
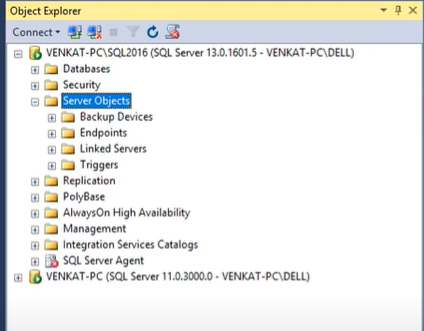
- Go to your Management Studio and choose the SQL Server instance you want to work with.
- Go to the Object Explorer pane, select Server Objects in the expand window, and click on Linked Servers. Once you click on the linked server, select the New Linked Server option there.
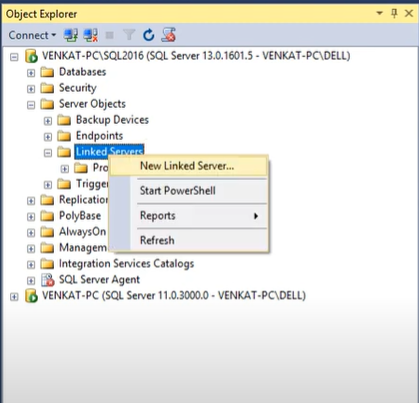
- Click on Other data source under Server Type.
- Click on Microsoft OLE DB Provider in the Provider list.
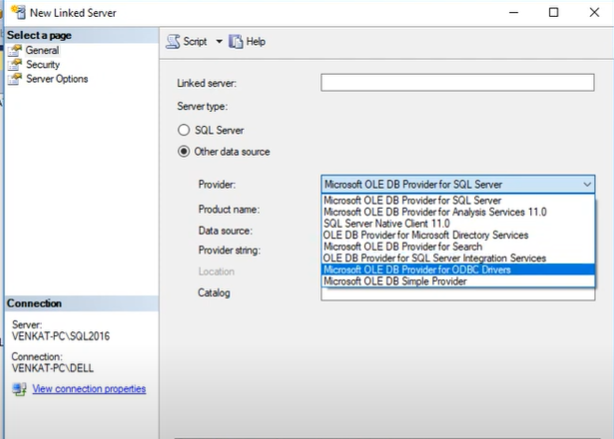
- Enter the name of your data source and input the ODBC driver connection string in the Provider field.
The Linked Server option will appear under Linked Services in the Object Explorer window. Once you are through, you can issue queries and access your BigQuery database through the SQL Server.
Step 2: Collection Data from BigQuery
- Select MSDQSQL from list of Linked Servers and enable Allow in-processes
- Create a new Linked Server by clicking on Linked Server in Object Explorer.
- Select Microsoft OLE DB Provider for your ODBC Driver in the New Linked Server Pane
- Input the name of the Linked Server and provide the product name and data source to indicate the DSN system you created earlier.
- The tables in BigQuery are ready to fetch your data. You just need to click on New Query to query your linked server.
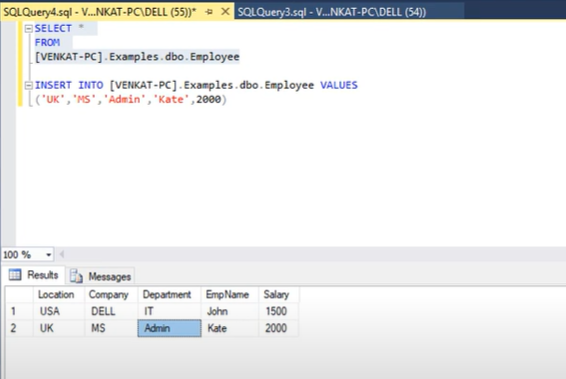
- Insert the query in the Editor pane and select Execute to run it. The ODBC Driver retrieves all the content from the BigQuery tables.
Limitations of Connecting BigQuery to SQL Server Using ODBC Driver
- The connections made through ODBC drivers are sensitive to network latency, resulting in slow data retrieval and affecting the system’s performance.
- ODBC Drivers sometimes don’t fully support the advanced SQL functionalities, making the data migration process lengthy and tedious.

Method 3: Transferring Data from BigQuery to MsSQL Server Using an Operator
Prerequisites
- Either Create or Select a Cloud Platform Project from Cloud Console.
- Enable billing for the Project that you created using Google Cloud Documentation.
- Enable an API as per the Cloud Console Documentation.
- Install the API library using pip
pip install 'apache-airflow[google]'
- Set up the Google Cloud Connection
Step 1: Using BigQuery Operator to Copy Data from BigQuery Table
- To define values separately, you should use Jinja templating with field names like table_name, table_id, dataset_id, etc.
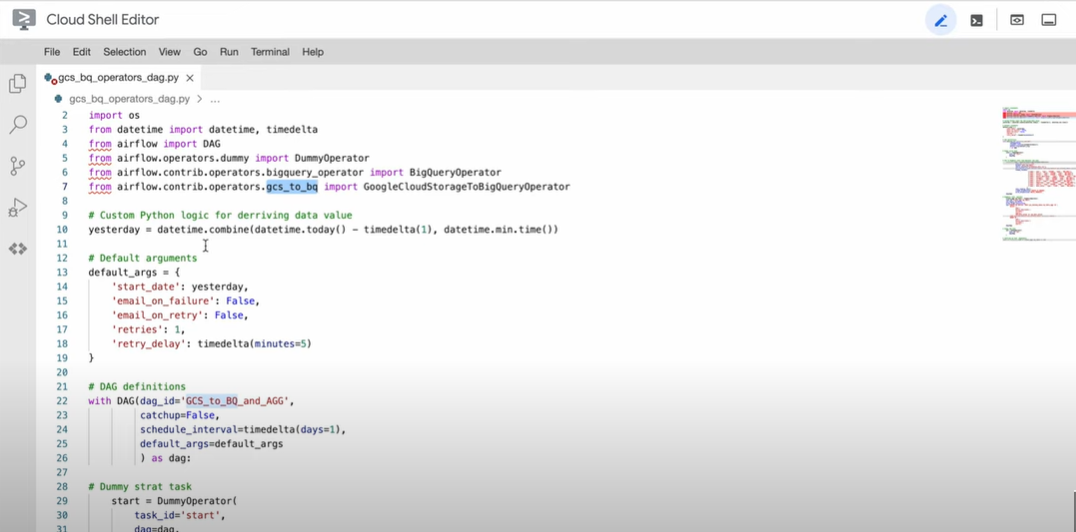
Step 2: Transferring Data from BigQuery Table to MsSQL Server
Use the following command to get the data from BigQuery. Here, BigQueryToMsSqlOperator helps you copy the data from the source to the destination.
BigQuery_to_mssql = BigQueryToMsSqlOperator(
task_id="BigQuery_to_mssql",
source_project_dataset_table=f"{PROJECT_ID}.{DATASET_NAME}.{TABLE}",
target_table_name=destination_table,
replace=False,
)
Limitations of Transferring Data from BigQuery to MySQL Server Using an Operator
- You may have to use additional tools for scripting and integration, which makes the process lengthy and complex.
- To use the BigQuery Operator, you must be familiar with its functionality and the platform it supports.
- You must understand the Google Cloud Platform and perform specific steps before proceeding with the scripting part.
Use Cases of BigQuery to MySQL Server Migration
- SQL Server provides greater control over data optimization and configuration compared to BigQuery, which has limited options for service customization.
- Unlike BigQuery, SQL provides better data replication methods such as snapshot, transactional, and merge replication. This makes SQL Server more flexible in synchronizing with different data environments, ensuring data consistency.
Learn more about How to Connect & Load Data from BigQuery to MySQL as well migrating data from BigQuery to PostgreSQL.
You can also read more about:
- SQL Server to Azure Synapse
- PostgreSQL to SQL Server
- PostgreSQL to SQL Server
- QuickBooks to SQL Server
Final Word
BigQuery and SQL Server are high-capacity storage platforms that help manage data for profound interpretation and analysis. If you want to organize your BigQuery data in an SQL Server, Hevo is a good choice among other ELT platforms for the task. You can also export data from BigQuery using ODBC Driver and BigQuery Operator.
FAQs
1. How to transfer data from BigQuery to SQL Server?
You can use Hevo to automate data transfer from BigQuery to SQL Server. Hevo provides a no-code platform to set up a pipeline between BigQuery and SQL Server, enabling seamless and real-time data transfer.
2. Can BigQuery connect to SQL Server?
Yes, BigQuery can connect to SQL Server. By using Hevo, you can easily set up a pipeline that transfers data between BigQuery and SQL Server, allowing you to sync data and perform analysis.
3. What is the difference between BigQuery and SQL Server?
BigQuery is a cloud-based, fully managed data warehouse designed for large-scale data analysis, optimized for querying massive datasets. SQL Server, on the other hand, is a relational database management system designed for transactional processing and handling structured data. With Hevo, you can easily integrate the two systems to leverage the strengths of both platforms.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



