

Have you heard of the Google Cloud Platform, offering a completely managed stream and batch data processing service? Well, this modern data engineering technology plays an essential part in dealing efficiently and quickly with massive amounts of data. Designed to be highly scalable, highly reliable, and highly easy to use, it can easily support multiple purposes—real-time analytics, data transformation, or machine learning pipelines.
Yes, you guessed it right, it is Google Dataflow. Today, let us talk about its architecture, how it fits into the Google Cloud ecosystem for data architectures, and what kinds of pipelines can be built on top of it.
Let us dive right in.
Table of Contents
What is Google Dataflow?

Google Dataflow is a cloud-based data processing tool that works for streaming (real-time) and batch (historical) data workloads. It’s based on Apache Beam, an open-source programming model that allows developers to write a pipeline once and then run it across different environments, including Dataflow.
The following are the core capabilities of Dataflow:
- Stream Processing: You can use stream processing when you want to ingest and process data in real-time, which is helpful for applications like fraud detection and live dashboards.
- Batch Processing: You can use batch processing to process historical data in large volumes for reports, ETL, or ELT tasks.
- Autoscaling: Automatically adjusts resources to the current workload, saving cost and effort.
- Unified Programming Model: This lets you use the same programming concepts for batch and streaming scenarios.
Why Use Google Cloud Dataflow?
Key Features and Benefits
- Fully Managed: With Dataflow, you don’t need to worry about setting up or maintaining servers. It takes care of everything for you.
- Scalable by Design: Dataflow scales resources up or down depending on how much data you’re processing, so it’s always efficient.
- Highly Flexible: It supports many data formats and integrates seamlessly with other GCP tools like BigQuery for analytics, Pub/Sub for real-time messaging, and Cloud Storage for data storage.
- Cost-Effective: You only pay for what you use, and its autoscaling feature ensures no waste of resources.
Real-World Applications
- Fraud Detection: Analyzing transactions in real time to flag suspicious patterns.
- ETL Pipelines: Cleaning and transforming data before storing it in analytics systems.
- IoT Data: You can process data from devices like sensor data.
- Recommendation Systems: Using real-time user data to suggest personalized options.
Are you looking for ways to connect your GCP tools? Hevo has helped customers across 45+ countries connect their cloud storage to migrate data seamlessly. Hevo streamlines the process of migrating data by offering:
- Seamlessly data transfer from Google Cloud platforms and 150+ other sources.
- Risk management and security framework for cloud-based systems with SOC2 Compliance.
- Always up-to-date data with real-time data sync.
Don’t just take our word for it—try Hevo and experience why industry leaders like Whatfix say,” We’re extremely happy to have Hevo on our side.”
Get Started with Hevo for FreeGoogle Dataflow Architecture
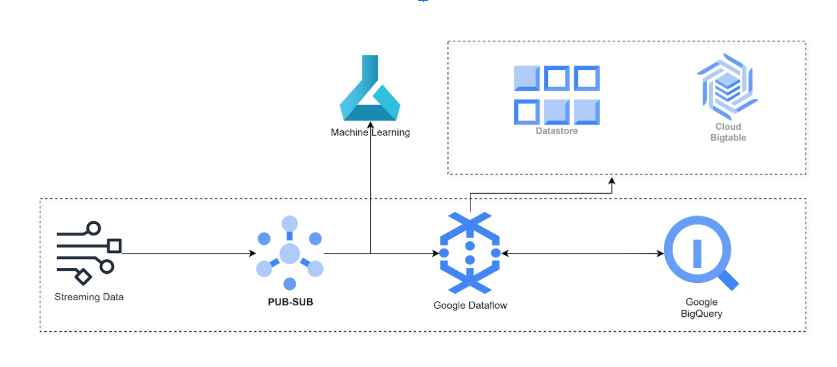
Dataflow’s architecture emphasizes distributed processing, scalability, and fault tolerance. Let us discuss the architecture in detail.
1. Apache Beam
It is the underlying programming model for Google Dataflow. It relies on Apache Beam for its programming interface. Apache Beam provides a unified way to define and manage data processing workflows. It includes:
- Transformations: These include filtering, mapping, and grouping data.
- Pipeline Abstraction: You define the pipeline in a Beam-supported language (like Python or Java), and Dataflow handles the execution.
2. Building and Deploying Pipelines
Here’s how pipelines are typically created:
- Define the Pipeline: Use Apache Beam SDK to describe the steps—from data ingestion to transformation and output.
- Deploy to Dataflow: Submit the pipeline to Dataflow, which runs it on distributed infrastructure.
3. GCP Integrations
- Google Cloud Storage: A common source and destination for pipeline data.
- BigQuery: Makes it easy to load processed data into tables for analysis.
- Pub/Sub: Publisher/Subscriber model data ingestion tool for real-time data streams.
Creating a Google Dataflow Pipeline with Python
Google Dataflow Python implementation can be performed in the following steps:
Step 1: Setting Up
- Install Apache Beam SDK
pip install apache-beam[gcp]- Configure GCP: Ensure your GCP project has billing enabled and the necessary APIs (like Dataflow and Pub/Sub) activated.
Example: Batch Pipeline
Here’s a Python example for a batch pipeline that reads data from cloud storage, processes it, and writes it to BigQuery:
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions
class TransformData(beam.DoFn):
def process(self, element):
fields = element.split(',')
return [{
'id': fields[0],
'value': int(fields[1])
}]
pipeline_options = PipelineOptions(
project='<your-gcp-project-id>',
region='<your-region>',
runner='DataflowRunner',
temp_location='gs://<your-bucket>/temp'
)
with beam.Pipeline(options=pipeline_options) as p:
(p
| 'Read from GCS' >> beam.io.ReadFromText('gs://<your-bucket>/input.csv')
| 'Transform Data' >> beam.ParDo(TransformData())
| 'Write to BigQuery' >> beam.io.WriteToBigQuery(
'<your-dataset>.<your-table>',
write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND
)
)Step 2: Deploying the Pipeline
Execute the script:
python your_pipeline.pyThis submits the pipeline to Dataflow for execution.
Google Dataflow Pricing
The pricing for Google Dataflow is based on a pay-as-you-go model. The total cost will depend on the following:
- Compute Resources: You are billed per CPU (vCPU) and memory usage of the compute resources per second. Depending on the workload streaming or batch type, your compute bill may vary.
- Storage: When dataflow pipelines require intermediate storage, the cost for this storage applies to the cost of the pipeline.
- Data Processing and Network: Additional charges are incurred for the volume of data that moves through the pipeline network.
Batch pipelines are usually cheaper because they run for limited durations. For an accurate estimate, you can use GCP’s pricing calculator.


Alternatives to Google Dataflow
Google Dataflow vs Hevo
- Hevo: Hevo is a no-code ETL platform designed for quick and easy data pipeline setups.
- Simplicity: Hevo’s interface is beginner-friendly, while Dataflow requires programming skills.
- Use Cases: Hevo is best for straightforward ETL tasks, while Dataflow can handle complex, large-scale workflows.
- Pricing: Hevo’s predictable and transparent pricing is attractive, whereas Dataflow charges vary, causing customer issues.
You should prefer Hevo over Google Dataflow because of the following limitations:
Limitation of Google Dataflow:
- Developing and managing data pipelines on Google Dataflow is no piece of cake and requires programming knowledge with experience in Apache Beam.
- Debugging and maintaining data pipelines is another challenge for someone without a tech background.
- Due to autoscaling and dynamic resource allocation, the pricing can be unpredictable.
This is where Hevo comes to rescue you:
- Hevo provides a no-code interface for anyone without programming experience to build, deploy, and maintain simple and complex data pipelines.
- You can build data pipelines with hundreds of prebuilt connectors and automated processes.
- Hevo provides a predictable pricing model without any unexpected usage surcharges.
Thus, for companies looking for a simple solution without much engineering, Hevo can be a better choice.
Conclusion
Google Dataflow is an essential tool within the Google Cloud Platform for organizations looking to streamline their data processing workflows. It can easily manage batch and streaming data and integrates well with other GCP services, making it versatile for a wide range of modern data analytics use cases.
However, when an organization is looking for a similar solution that requires less engineering expertise, Hevo provides compelling options depending on specific use cases and organizational requirements. Sign up for a 14-day free trial and see for yourself.
Frequently Asked Questions (FAQs)
1. Is Google Dataflow an ETL?
Yes, Google Dataflow can be used as a data ingestion tool as well as an ETL tool that facilitates the extraction, transformation, and loading of data.
2. What is the difference between Google Dataflow and Airflow?
They differ in terms of their usage and purpose. Google Dataflow is a cloud-based ETL tool whereas Apache Airflow is an open-source orchestration tool.
3. What is the difference between Google Dataflow and AWS?
Google Dataflow is a managed service for data processing using Apache Beam, whereas AWS is a public cloud service provider that offers multiple services like AWS Glue and Data Pipeline for similar tasks.
4. Is Google Dataflow free?
No, Google Dataflow is not free; it operates on a pay-as-you-go pricing model based on resource usage.
5. How is Dataflow verification done?
Dataflow verification is done through monitoring tools that provide diagnostics, logging, metrics, and performance insights to ensure pipeline accuracy and efficiency.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




