



Unlock the full potential of your Harvest data by integrating it seamlessly with BigQuery. With Hevo’s automated pipeline, get data flowing effortlessly—watch our 1-minute demo below to see it in action!
Time tracking lets you make smart decisions about how you run and price projects, how you spend your day, and how you schedule tasks for your team. An eagle-eye view into your operations will allow you to boost productivity and make sure you’re focusing on the right things to provide the best service for your customers.
So, you got a time-tracking tool in place; Harvest. For analysis, you need to consolidate the data in a central data repository, like a data warehouse.
You landed on this article, so I’m guessing you’re looking for easy ways to move your data from Harvest to BigQuery. Let’s dive in!
Use Hevo’s no-code data pipeline platform, which can help you automate, simplify, and enrich your data replication process in a few clicks. You can extract and load data from 150+ Data Sources, including Harvest, straight into your Data Warehouse, such as Bigquery or any Database.
Why Hevo?
- Incremental Data Load: Hevo allows the transfer of data that has been modified in real-time. This ensures efficient utilization of bandwidth on both ends.
- Live Support: Our team is available round the clock to extend exceptional support to our customers through Chat, Email, and Support Calls.
- Automapping: Hevo provides you with an automapping feature to automatically map your schema.
Explore Hevo’s features and discover why it is rated 4.3 on G2 and 4.7 on Software Advice for its seamless data integration. Try out the 14-day free trial today to experience hassle-free data integration.
Get Started with Hevo for FreeTable of Contents
Replicating Data from Harvest to BigQuery
Method 1: Automate the Data Replication process using a No-Code Tool
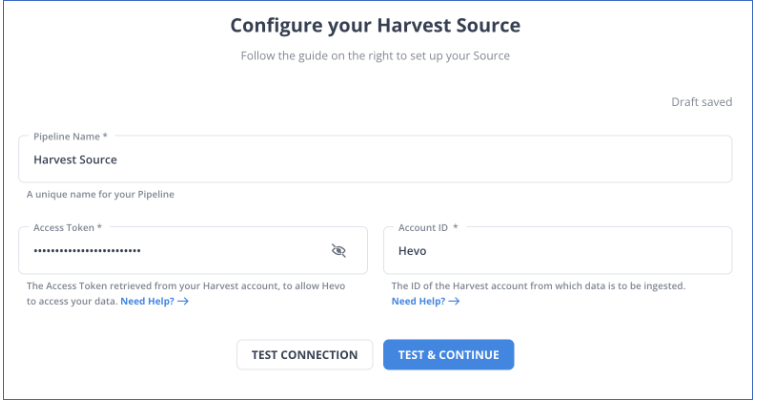
Step 1: Configure Harvest as a Source
Step 2: Configure BigQuery as a Destination
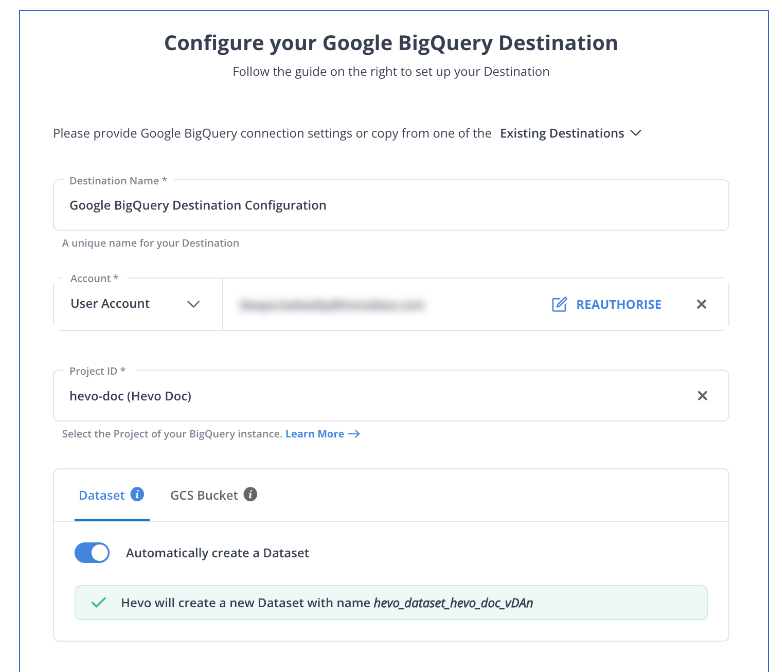
And that’s it! Based on your inputs, Hevo will start replicating data from Harvest to BigQuery.
Method 2: Using CSV Files for Harvest to BigQuery Integration
The data you can export from Harvest depends on your user permissions. There are three different levels of permissions in Harvest: Administrator, Manager, and Member. You can export data as needed through Reports across all permission levels. You can export these reports as CSV, Excel, or PDF files.
- You can export all your company time data and invoices from the Export data section of Settings. If you click on Export all invoices, you’ll get a zip file with PDFs of all invoices. Similarly, if you click on Export all estimates or Export all time, you’ll get a zip file with PDFs of all estimates and company time data respectively.
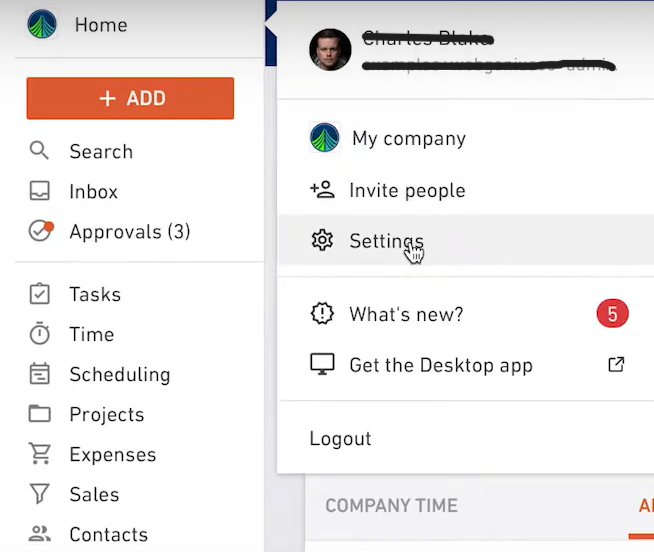
- As an administrator and as a manager, you can take a look at all the projects that you’re handling by exporting said projects from the main Projects section. You can even export more detailed project-specific data from a project’s analysis page.
For exporting Reports as CSV files, execute the following steps:
- Click on the Reports tab and select the name of the report you want to export.
- Next, add all the specifications for the report like filters, timeframe, and projects, to name a few.
- Run the report by clicking on the “Run Report” button. Next, click on the “Export” button and choose the format as CSV.
Similarly, you can export data around projects, estimates, contacts, tasks, invoices, etc., as well.
Now that you have your Harvest data in CSV files, you need to move it to BigQuery.
Say you have a dataset named htbdb and there exists a table named htbtable in it. You can use the bq load command to load the CSV data to BigQuery:
bq load htbdb.htbtable htbsource.txt name:string,count:integerYou can check if the table has been populated by running the following command:
bq show htbdb.htbtableThis method is suitable for the following scenarios:
- Low-Frequency Data Replication: If your finance team needs data from Harvest yearly, quarterly, or once in a while, then it’s recommended that you use CSV files for Harvest to BigQuery migration.
- Dedicated Personnel: If your organization has dedicated staff who manually select categories, customize templates, and download and upload CSV files, then replicating data from Harvest using CSV files is much simpler.
- Low Volume of Data: Repeatedly selecting/customizing categories and templates, and downloading/uploading CSV files can be tedious. Merging these CSV files from various departments to measure the business’s performance also takes time. Therefore, this method is best suited for replicating only a few files.
Stop wasting valuable engineering time and resources manually replicating and transforming data from Harvest. With more data sources, the tedious process of creating custom connectors, transforming and processing the data, tracking the flow, and fixing issues can quickly become a major burden.
To take back your time and start focusing on more productive tasks, you can…
What can you hope to achieve by replicating data from Harvest to BigQuery?
Replication of data from Harvest to BigQuery can help you answer the following questions:
- How much are we spending on each project and client?
- What’s the total number of billable hours for each client?
- Can we identify any patterns in client purchases?
- What’s the average income per client or project?
- Who are the vital players in a project?

Key Takeaways
You can replicate data from Harvest to BigQuery in two ways — using CSV files, and third-party data replication tools like Hevo Data. Each method has its own place and is suitable for different scenarios.
Hevo Data allows you to replicate data in near real-time from 150+ sources to the destination of your choice including Snowflake, BigQuery, Redshift, Databricks, and Firebolt, without writing a single line of code. We’d suggest you use this data replication tool for real-time demands like tracking the sales funnel or monitoring your email campaigns. This’ll free up your engineering bandwidth, allowing you to focus on more productive tasks.
Try a 14-day free trial to explore all features, and check out our unbeatable pricing for the best plan for your needs.
FAQ on Harvest to BigQuery
1. How do I transfer data to BigQuery?
To transfer data to BigQuery, you typically need to export your data from the source database and then load it into BigQuery using tools or methods supported by Google Cloud Platform.
– Export Data from Source Database
– Upload Data to Google Cloud Storage
– Load Data into BigQuery
2. How to migrate data from SQL Server to BigQuery?
– To Migrate data from SQL Server to BigQuery:
– Use the Google Cloud Data Transfer Service
– Set Up a Transfer Job
3. How to migrate Oracle database to BigQuery?
– Export Data from Oracle Database
– Upload File to GCS
– Load Data into BigQuery (bq command)
Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



