




Building an entirely new data connector is difficult, especially when you’re already heavily swamped with monitoring and maintaining your existing custom data pipelines. When you have an ad-hoc Harvest to Databricks connection request from your HR and accounting teams, you’ll have to compromise your engineering bandwidth with this manual task.
We understand you are pressed for time and require a quick solution. If the situation demands that you download and submit a couple of CSV files, then this task would seem like a cheery pie. However, with the increase in the frequency of data replication and the number of connectors, you can even choose to use an automated solution.
Well, worry no further! We’ve prepared a simple and straightforward guide to help you replicate data from Harvest to Databricks. Enough talk! Let’s get to it.
Table of Contents
Overview of Harvest

- Harvest is a popular time-tracking software used to monitor project hours, employee productivity, and time spent on tasks.
- It helps businesses manage projects more efficiently by providing insights into time allocation and budget tracking.
- Harvest allows users to generate invoices based on tracked hours and create detailed reports for project analysis.
- It integrates seamlessly with tools like Asana, Trello, and QuickBooks, making it easier to sync time-tracking data with other systems.
Method 1: Replicate Data from Harvest to Databricks Using an Automated ETL Tool
Hevo can help you export data from Harvest to Databricks in real-time, free of cost, without having to write a single line of code. With the help of Hevo’s pre-built integrations with 150+ sources (including 60+ free sources), such as Harvest, you can set up the whole data pipeline without any technical intervention and load data from Harvest to Databricks or a destination of your choice with ease.
Method 2: Replicate Data from Harvest to Databricks Using CSV Files
In this method, you will have to export data as CSV files and then import it into Databricks. This is a laborious task and prone to errors.
Get Started with Hevo for FreeOverview of Databricks

- Databricks provides a unified platform for data analytics that empowers simplicity in big data processing and machine learning, tightly integrating with Apache Spark for the power of an open-source analytics engine.
- It provides a cloud-based environment that simplifies the data pipeline from ingesting data to analyzing it.
- Principally, Databricks provides collaborative notebooks, automated cluster management, and advanced analytics capabilities that enable data engineers and data scientists to work more collaboratively on big data projects.
Method 1: Replicate Data from Harvest to Databricks Using an Automated ETL Tool
Step 1.1: Configure Harvest as a Source
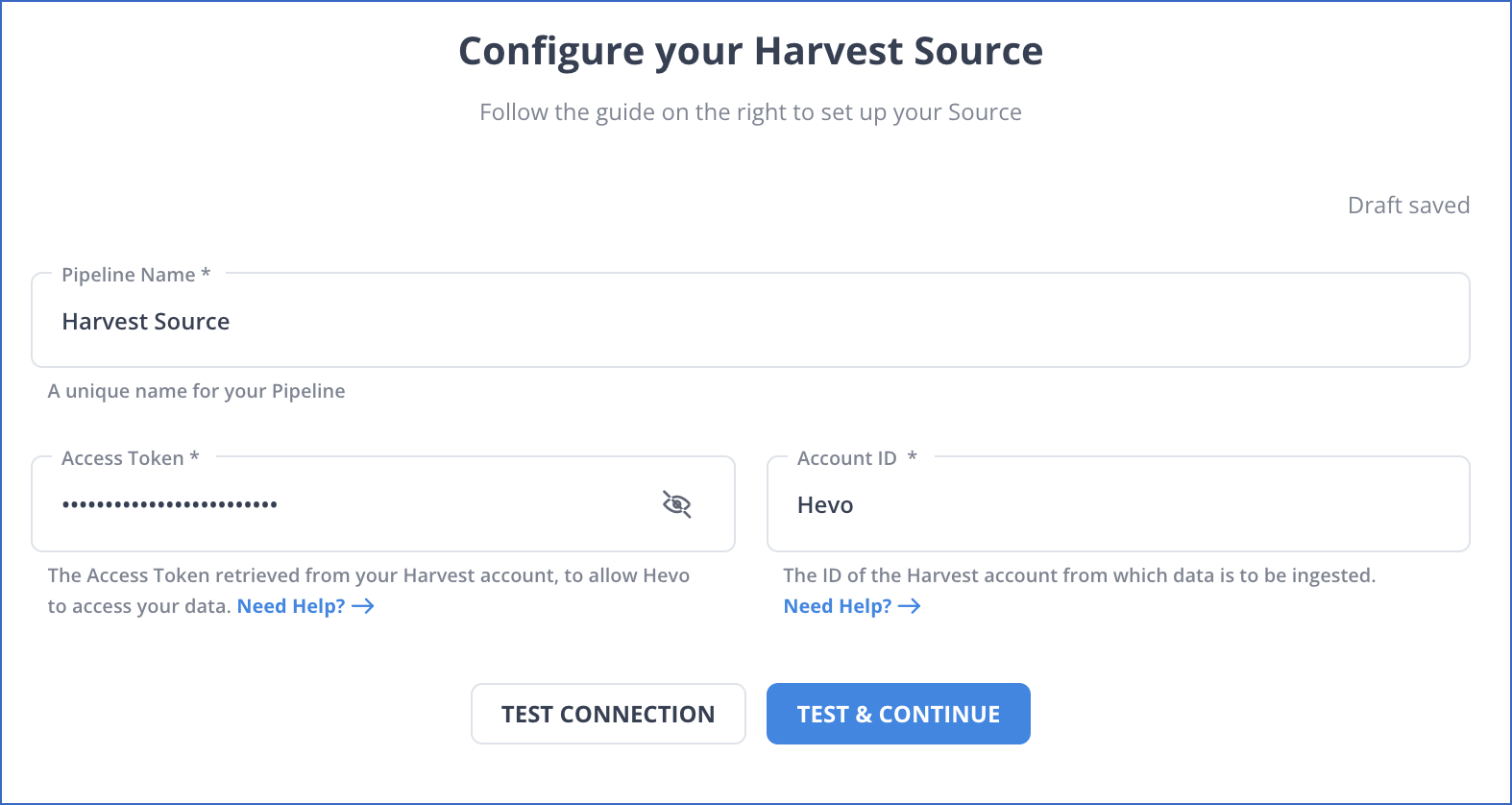
Step 1.2: Configure Databricks as a Destination

All Done to Setup Your ETL Pipeline
After implementing the 2 simple steps, Hevo Data will take care of building the pipeline for setting up Harvest to Databricks integration based on the inputs given by you while configuring the source and the destination.
The pipeline will automatically replicate new and updated data from Harvest to Databricks every 1 hr (by default). However, you can also adjust the data replication frequency as per your requirements.
Data Pipeline Frequency
| Default Pipeline Frequency | Minimum Pipeline Frequency | Maximum Pipeline Frequency | Custom Frequency Range (Hrs) |
| 1 Hr | 1 Hr | 24 Hrs | 1-24 |
For in-depth knowledge of how a pipeline is built & managed in Hevo Data, you can also visit the official documentation for Harvest as a source and Databricks as a destination.
Hevo’s Salient Features
Here’s how Hevo challenges the normal to beget the new ‘exceptional.’
- Fully Managed: Hevo requires no management and maintenance as it is a fully automated platform.
- Data Transformation: Hevo provides a simple interface to perfect, modify, and enrich the data you want to transfer.
- Faster Insight Generation: Hevo offers near real-time data replication, so you have access to real-time insight generation and faster decision making.
- Schema Management: Hevo can automatically detect the schema of the incoming data and map it to the destination schema.
- Scalable Infrastructure: As your sources and the volume of data grows, Hevo scales horizontally, handling millions of records per minute with very little latency.
- Live Support: The Hevo team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.

Method 2: Replicate Data from Harvest to Databricks Using CSV Files
Let’s dive into the process of replicating data from Harvest to Databricks in CSV format:
Step 2.1: Export Data from Harvest
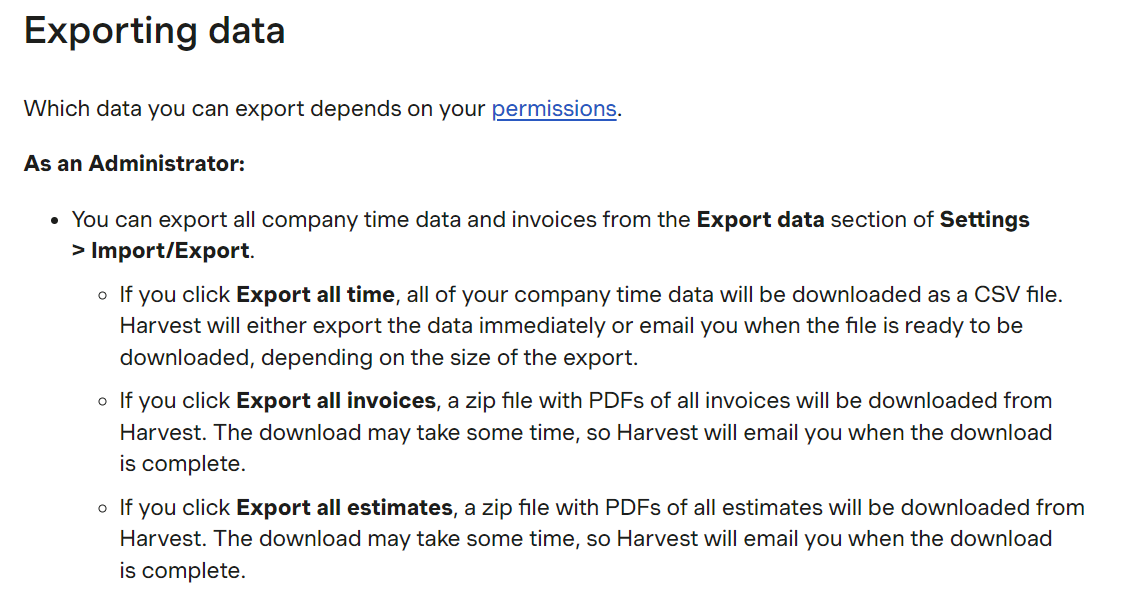
Here’s the data that you can export from your Harvest account:
- Reports
- Projects
- Teams
- Estimates
- Clients and Client Contacts
- Tasks
- Time
- Invoice
And the different types of reports in your Harvest account are:
- Time Report
- Detailed Time Report
- Detailed Expense Report
- Uninvoiced Report
- Invoiced Report
- Payments Received Report
- Contractor Report
Let’s dive into the steps for exporting data from Harvest in CSV format.
For Exporting Data about Contacts, People, Clients, and Tasks
- Click on the “Manage” tab.
- Now, click on the “Export” button at the top of the page.
- A list of your required data will be downloaded in Excel or CSV format.
For Exporting Projects data
- Click on the “Projects” tab.
- Now, click on the “Export” button at the top of the page.
- You can choose whether you want to export all active projects, only budgeted projects, or only archived projects.
- A list of your required project data will be downloaded in CSV format.
For Exporting Reports
- Click on the “Reports” tab.
- Select the name of the report you want to export.
- Now add all the specifications required specific to that report, such as timeframe, projects, filters, etc.
- Click the “Run Report” button.
- Now, click on the “Export” button at the top of the page. Then, choose the format as CSV.
For Exporting Estimates Data
- Click on the “Estimates” tab.
- To export a list of open estimates, click on the “Open” option and select the “Export” button.
- To export all of your estimates, click on the “All estimates” option. Now, you can filter the data by estimate status, client, or timeframe. Then select the “Export” button.
- Now, you can choose your format as CSV. A list of your estimates data will be downloaded in CSV format.
Step 2.2: Import CSV Files into Databricks
- In the Databricks UI, go to the side navigation bar. Click on the “Data” option.
- Now, you need to click on the “Create Table” option.
- Then drag the required CSV files to the drop zone. Otherwise, you can browse the files in your local system and then upload them.
Once the CSV files are uploaded, your file path will look like: /FileStore/tables/<fileName>-<integer>.<fileType>
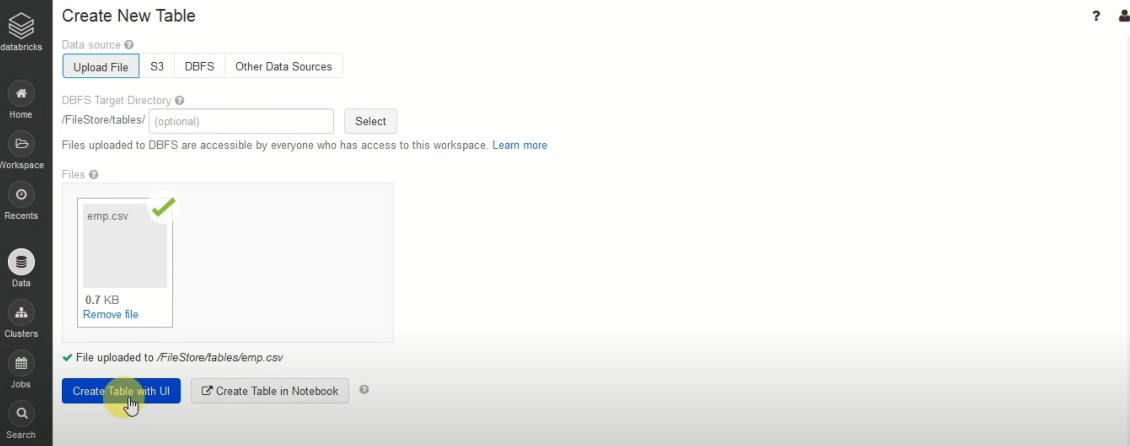
If you click on the “Create Table with UI” button, then go through the following steps:
- Then, select the cluster where you want to preview your table.
- Click on the “Preview Article” button. Then, specify the table attributes such as table name, database name, file type, etc.
- Then, select the “Create Table” button.
- Now, the database schema and sample data will be displayed on the screen.
Once you click on the “Create Table in Notebook” button, you can go through the following steps:
- A Python notebook is created in the selected cluster.
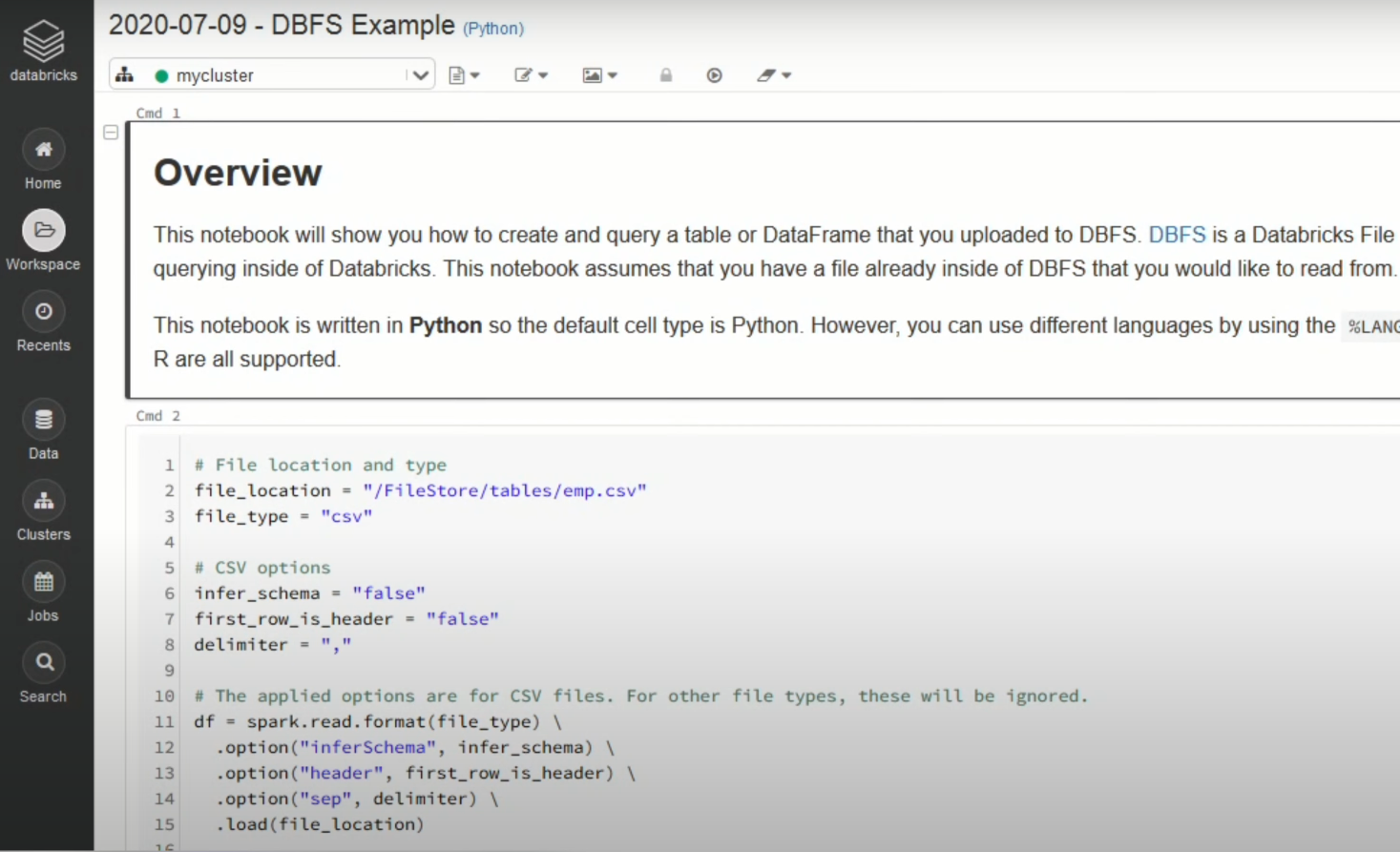
- You can edit the table attributes and format using the necessary Python code. You can refer to the below image for reference:
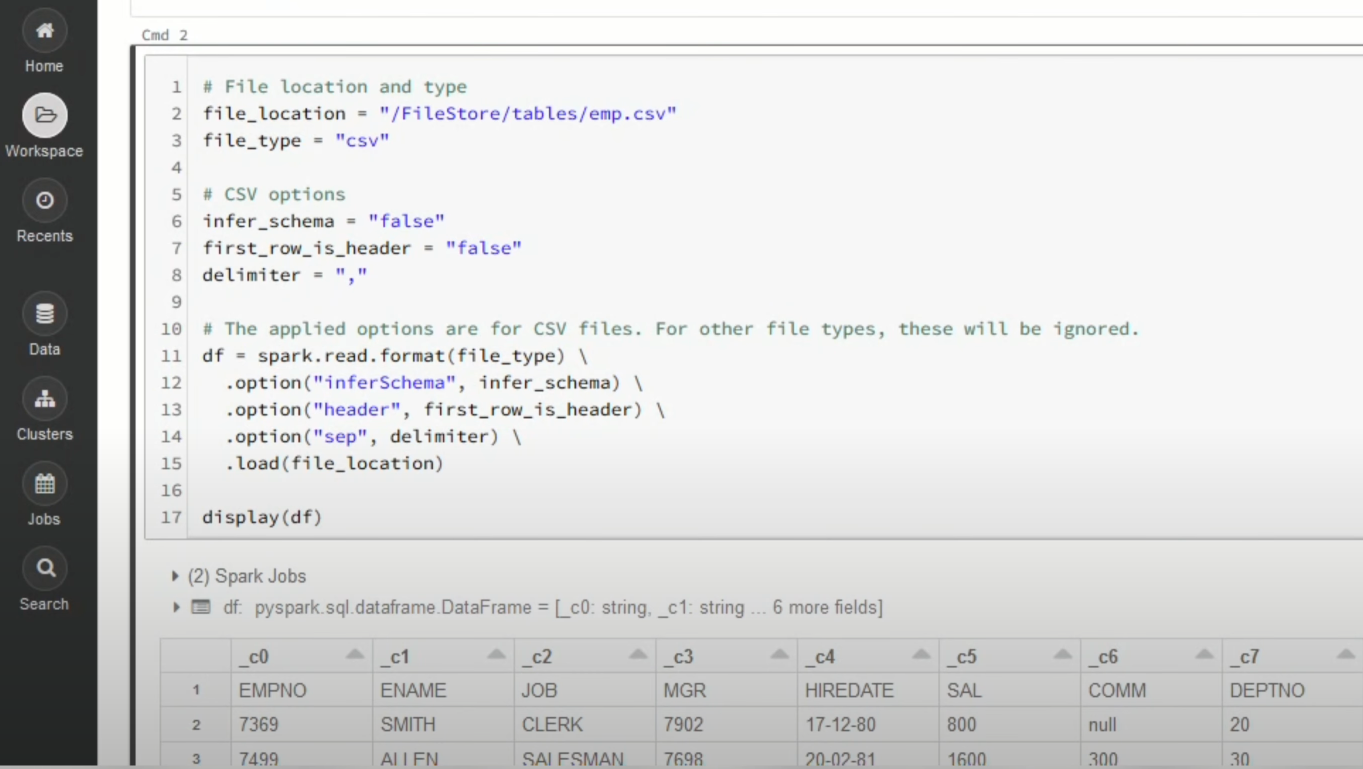
- You can also run queries on SQL in the notebook to get a basic understanding of the data frame and its description.
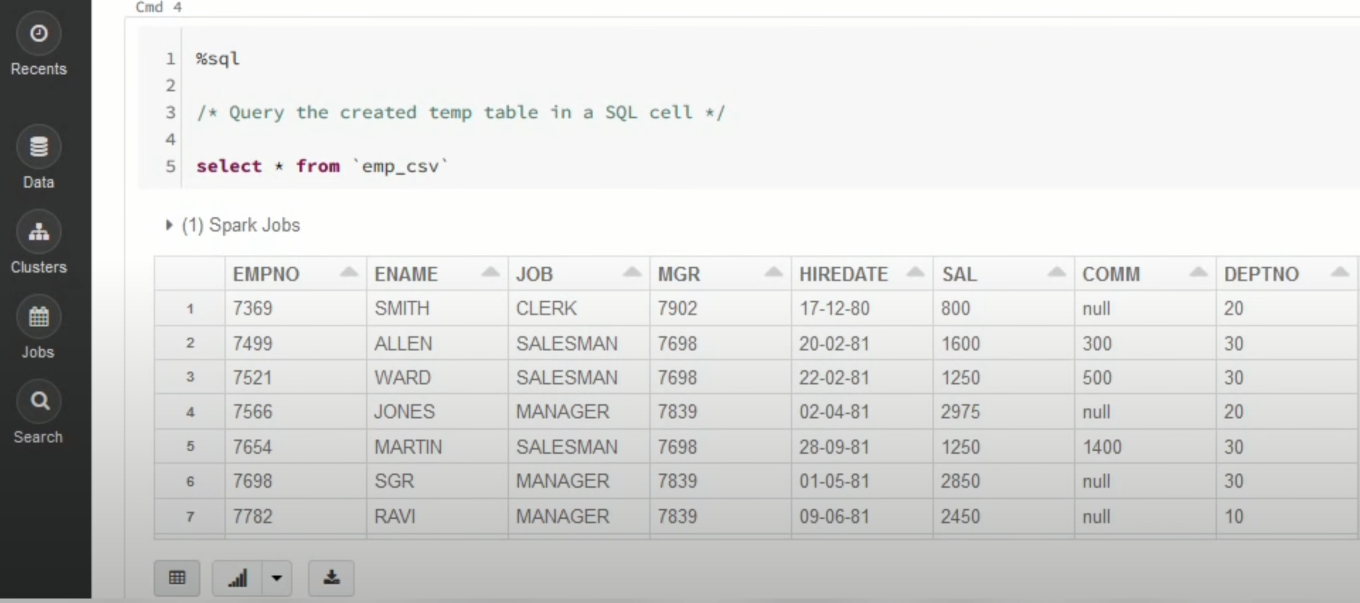
In this case, the name of the table is “emp_csv.” However, in your case, we can keep it according to your requirements.
- Now, on top of the Pandas data frame, you need to create and save your table in the default database or any other database of your choice.
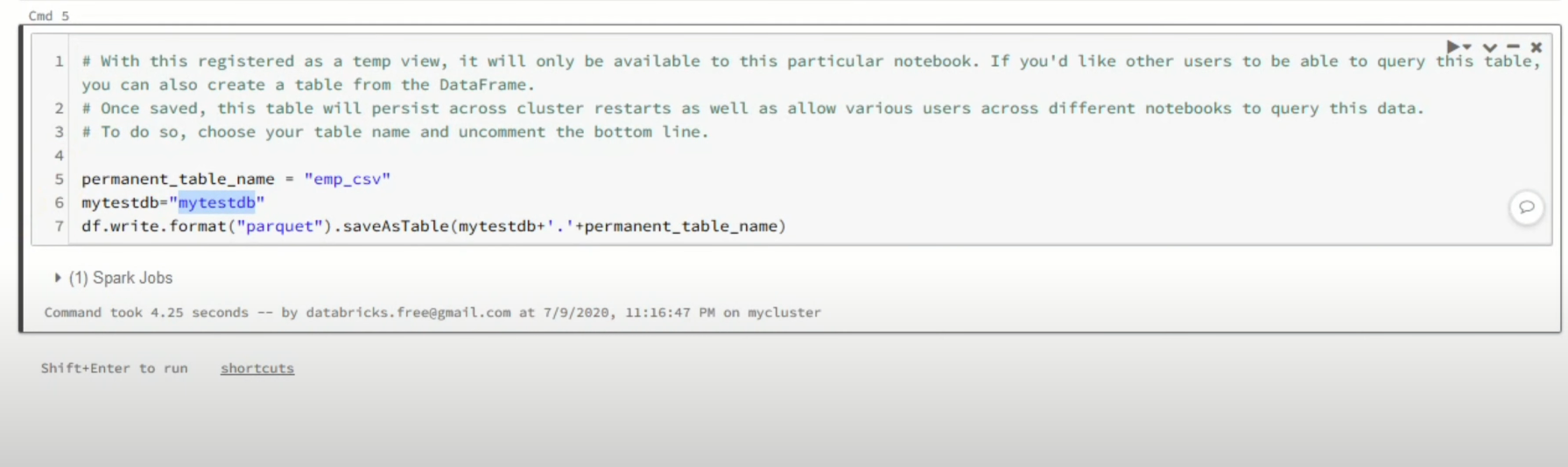
In the above screenshot mytestdb is the database where we intend to save our table.
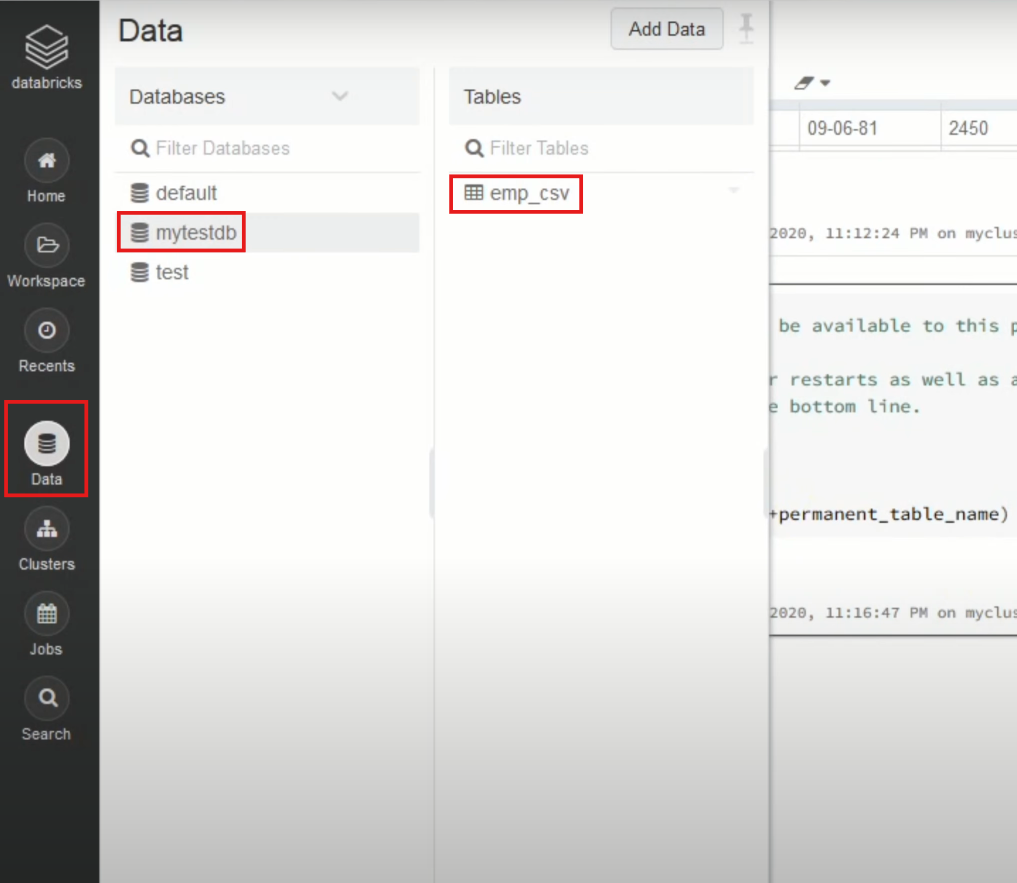
- After you save the table, you can click on the “Data” button in the left navigation pane and check whether the table has been saved in the database of your choice.
Step 2.3: Modify & Access the Data
- The data now gets uploaded to Databricks. You can access the data via the Import & Explore Data section on the landing page.
- To modify the data, select a cluster and click on the “Preview Table” option.
- Then, change the attributes accordingly and select the “Create Table” option.
When is Manually Connecting Harvest to Databricks Preferred?
- Low-frequency Data Replication: This method is appropriate when your product and marketing teams need the Harvest data only once in an extended period, i.e., monthly, quarterly, yearly, or just once.
- Dedicated Personnel: If your organization has dedicated people who have to select categories manually, customize templates, then download and upload CSV files, then accomplishing this task is not much of a headache.
- Low Volume Data: It can be a tedious task to repeatedly select different categories, select templates or customize them, and download & upload CSV files. Moreover, merging these CSV files from multiple departments is time-consuming if you are trying to measure the business’s overall performance. Hence, this method is optimal for replicating only a few files.
Limitations of Connecting Manually
- When the frequency of replicating data from Harvest increases, this process becomes highly monotonous.
- It adds to your misery when you have to transform the raw data every single time. With the increase in data sources, you would have to spend a significant portion of your engineering bandwidth creating new data connectors.
- Just imagine — building custom connectors for each source, transforming & processing the data, tracking the data flow individually, and fixing issues. Doesn’t it sound exhausting?
- Instead, you should be focusing on more productive tasks. Being relegated to the role of a ‘Big Data Plumber‘ that spends their time mostly repairing and creating the data pipeline might not be the best use of your time.
What Can You Achieve by Replicating Your Data from Harvest to Databricks?
Here are 5 instances where replicating data from Harvest to Databricks can help your data analysts get critical business insights. Does your use case make the list?
- For which geography the client expenses is maximum in the last 3 months?
- What should the project workflow look like for a certain category?
- What is the average daily variation of all the users?
- Who are the significant contributors to a project?
- How to optimize your employees’ workflow?
You can also learn more about:
- Google Sheets to Databricks
- Databricks Connect to SQL Server
- Databricks to S3
- Databricks ETL Methods
Summing It Up
- Exporting and importing CSV files would be the smoothest process when your HR & accounting teams require data from Harvest only once in a while.
- But what if the HR & accounting teams request data from multiple sources at a high frequency? Would you carry on with this method of manually importing & exporting CSV files from every other source?
- In this situation, you can choose to liberate your manual jobs by going for a custom ETL solution.
- A custom ETL solution becomes necessary for real-time data demands such as monitoring email campaign performance or viewing the sales funnel.
- You can free your engineering bandwidth from these repetitive & resource-intensive tasks by selecting Hevo Data’s 150+ plug-and-play integrations (including 60+ free sources).
Sign up for a 14-day free trial and simplify your data integration process. Check out the pricing details to understand which plan fulfills all your business needs.
Frequently Asked Questions
1. How do I transfer data to Databricks?
You can transfer data to Databricks using various methods like uploading files directly, using APIs, or connecting external storage systems like AWS S3, Azure Blob Storage, or Google Cloud Storage. For automated data transfer, you can also use tools like Hevo.
2. How do I save data to Databricks?
To save data to Databricks, you can write your DataFrame or table using commands like .write() in PySpark, specifying your preferred format (e.g., CSV, Parquet) and storage location within your Databricks environment.
3. How do I import data from Excel to Databricks?
To import data from Excel, first convert the file to a CSV or Parquet format, then upload it directly to Databricks or use external storage options. Once uploaded, use Databricks commands to read and analyze the file.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



