




Easily move your data from HubSpot to Databricks to enhance your analytics capabilities. With Hevo’s intuitive pipeline setup, data flows in real-time. Check out our 1-minute demo below to see the seamless integration in action!
As a data engineer, you hold all the cards to make data easily accessible to your business teams. Your marketing team just requested a HubSpot to Databricks connection on priority. We know you don’t wanna keep your data scientists and business analysts waiting to get critical business insights. As the most direct approach, you can go straight for the CSV files export if this is a one-time thing. Or, hunt for a no-code tool that fully automates & manages data integration for you while you focus on your core objectives.
Well, look no further. With this article, get a step-by-step guide to connecting HubSpot to Databricks effectively and quickly, delivering data to your marketing team.
Table of Contents
Use Cases of Moving HubSpot Data to Databricks?
Once we got our HubSpot data into Databricks, we were amazed by the kind of insights we could finally explore. If you’re a data analyst or a curious marketer, these use cases might just sound like your next big win:
- Connect Spend to Performance: Analyze how your paid sessions and goal conversions change with shifts in marketing spend and cash flow; you’ll never guess where you’re overspending again.
- Visualize Where Your Audience Lives: Map engagement and conversions by region to discover which demographics bring in the most traffic or sales, and tailor your messaging accordingly.
- Predict Who’s Ready to Buy: Use machine learning models to score leads based on behavior, engagement, and demographics, so you know exactly who to follow up with (and when).
- Spot Your Most Profitable Customers: Combine revenue, usage, and campaign data to pinpoint the segments that drive the most value, then double down on what works.
Methods to Connect HubSpot to Databricks
Method 1: Replicate Data from HubSpot to Databricks Using CSV
To start replicating data from Hubspot to Databricks, first, you need to export data as CSV files from Hubspot, then import the CSV files into Databricks and modify your data according to your needs.
- Step 1: To export your Contacts data from HubSpot, go to Contacts > List, select the list, and click Export. Choose the desired properties and CSV as the file format, then click Export, and you’ll receive a download link via email.
You can download by selecting Download your export file by navigating to your mail inbox.
- Step 2: In the Databricks UI, you must click on Data by navigating through the Sidebar menu. Click on Create Table, after you browse your files from the local computer, or simply drag your CSV files into the drop zone and upload them. Your path will look something like this: /FileStore/tables/<fileName>-<integer>.<fileType>. After uploading, your data can be simply viewed by clicking the Create Table with UI button.
- Step 3: After uploading your CSV file to Databricks, click Preview Table under the selected cluster to view the data. By default, data types are set to string, but you can change them from a dropdown menu. Use the left navigation bar to modify settings like First Row Header, Multi-line, Table Name, File Type, and Column Delimiter. Once everything is configured, click Create Table. The file will be accessible from the cluster where it was uploaded.
This 3-step process using CSV files is a great way to effectively replicate data from HubSpot to Databricks. It is optimal for the following scenarios:
- One-Time Data Replication: Your marketing team needs the HubSpot data only once in a long time.
- No Data Transformation Required: This method is ideal if there is a negligible need for data transformation and your data is standardized.
Limitations of the Manual Method
- Time-consuming Process: Manually exporting and uploading CSV files from HubSpot to Databricks requires significant time and effort, especially for large datasets.
- No Real-Time Data Sync: The manual method does not support real-time data updates, causing delays in data availability for analysis.
- Error-Prone: Manual processes are susceptible to errors during data extraction, formatting, or import.
- Limited Automation: Lacks automation capabilities, requiring constant monitoring and manual interventions for data consistency.


Method 2: Automate the Data Replication process using a No-Code Tool
Step 1: Configure HubSpot as a Source
Authenticate and Configure your HubSpot Source.
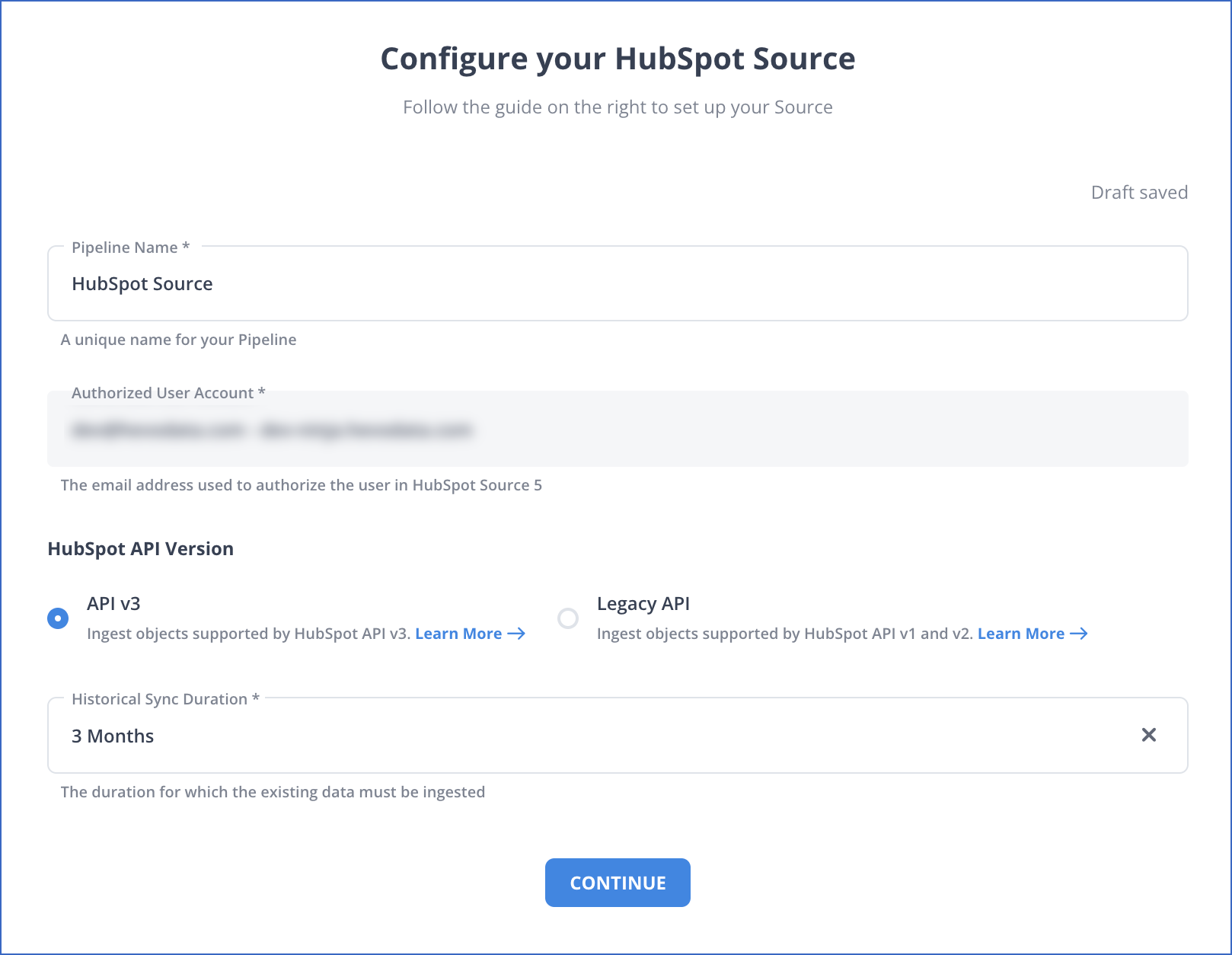
Step 2: Configure Databricks as a Destination
In the next step, we will configure Databricks as the destination.

Step 3: All Done to Set Up Your ETL Pipeline
Once your Hubspot to Databricks ETL Pipeline is configured, Hevo will collect new and updated data from Hubspot every five minutes (the default pipeline frequency) and duplicate it into Databricks. Depending on your needs, you can adjust the pipeline frequency from 5 minutes to an hour.
Data Replication Frequency
| Default Pipeline Frequency | Minimum Pipeline Frequency | Maximum Pipeline Frequency | Custom Frequency Range (Hrs) |
| 1 Hr | 15 Mins | 24 Hrs | 1-24 |
In a matter of minutes, you can complete this No-Code & automated approach of connecting HubSpot to Databricks using Hevo and start analyzing your data.
You can also read more about:
Summing It Up
Exporting and importing CSV files is the right path for you when your marketing teams need data from HubSpot once in a while. However, a custom ETL solution becomes necessary for real-time data demands such as monitoring campaign performance or viewing the recent user interaction with your product or marketing channel. You can free your engineering bandwidth from these repetitive & resource-intensive tasks by selecting Hevo’s 150+ plug-and-play integrations.
Saving countless hours of manual data cleaning & standardizing, Hevo’s pre-load data transformations get it done in minutes via a simple drag n drop interface or your custom python scripts. No need to go to your data warehouse for post-load transformations. You can simply run complex SQL transformations from the comfort of Hevo’s interface and get your data in the final analysis-ready form.
FAQ
How do I transfer data to Databricks?
You can transfer data to Databricks by uploading files directly to the workspace, connecting to cloud storage like AWS S3 or Azure Blob Storage, using Databricks connectors for databases, or employing ETL tools such as Hevo Data.
What type of data is stored in HubSpot?
HubSpot stores various types of data, including customer relationship management (CRM) data, marketing data (campaigns, email interactions), sales data (leads, deals), website analytics, and content management data (blog posts, landing pages).
How can I connect HubSpot to Databricks?
You can connect HubSpot to Databricks using APIs to extract data. You can also use ETL tools like Hevo Data to automate data transfer from HubSpot to Databricks, enabling you to load the data for analysis.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link










