

 Key Takeaways
Key TakeawaysMigrating data from Jira to Databricks manually involves exporting data from Jira using its API or CSV export feature and then transforming it into a suitable format. The data is then loaded into Databricks using SQL commands or the Databricks API for processing and analysis.
However, with an automated ETL tool like Hevo, the migration can be done using an easy drag-and-drop interface along with features like automated schema management and in-flight transformations.
Detailed Method:
Method 1: Using Hevo
Step 1: Connect Jira as your Source
Step 2: Connect Databricks as your Destination
Easily move your data from JIRA to Databricks to enhance your analytics capabilities. With Hevo’s intuitive pipeline setup, data flows in real-time. Check out our 1 minute demo below to see the seamless integration in action!
Jira is commonly used for managing workflows, tracking issues, and other scenarios where streamlining is essential. However, Jira doesn’t have efficient reporting features for advanced analytics. For this reason, many users integrate their Jira data with Databricks to have the ability to run complex queries, merge data, and gain deeper insights. Realising the importance, in the blog, we have provided you with a step-by-step guide that can help you integrate your data from MongoDB to BigQuery.
Table of Contents
Use Cases of Connecting Jira to Databricks
- Data-Driven Project Management: Teams can make informed decisions based on real-time project data, improving overall project management.
- Performance Monitoring: Users can identify bottlenecks in workflows and improve team efficiency by leveraging data visualization tools in Databricks.
- Reporting and Dashboards: Provide stakeholders with a holistic view of project performance and progress, enhancing transparency and communication.
- Predictive Analytics: Enable proactive project management by anticipating issues and adjusting strategies accordingly.
- Root Cause Analysis: Enhance product quality and team performance by addressing underlying issues based on data insights.
Seamlessly migrate your Issues and project data from Jira. Hevo elevates your data migration game with its no-code platform. Ensure seamless data migration using features like:
- Seamless integration with your desired data warehouse, such as BigQuery or Redshift.
- Transform and map data easily with drag-and-drop features.
- Real-time data migration to leverage AI/ML features of BigQuery and Synapse.
Explore Hevo’s features and discover why it is rated 4.3 on G2 and 4.7 on Software Advice for its seamless data integration.
Get Started with Hevo for FreeWhat is the Easiest Way to Connect Jira to Databricks?
Step 1: Configure Jira as a Source
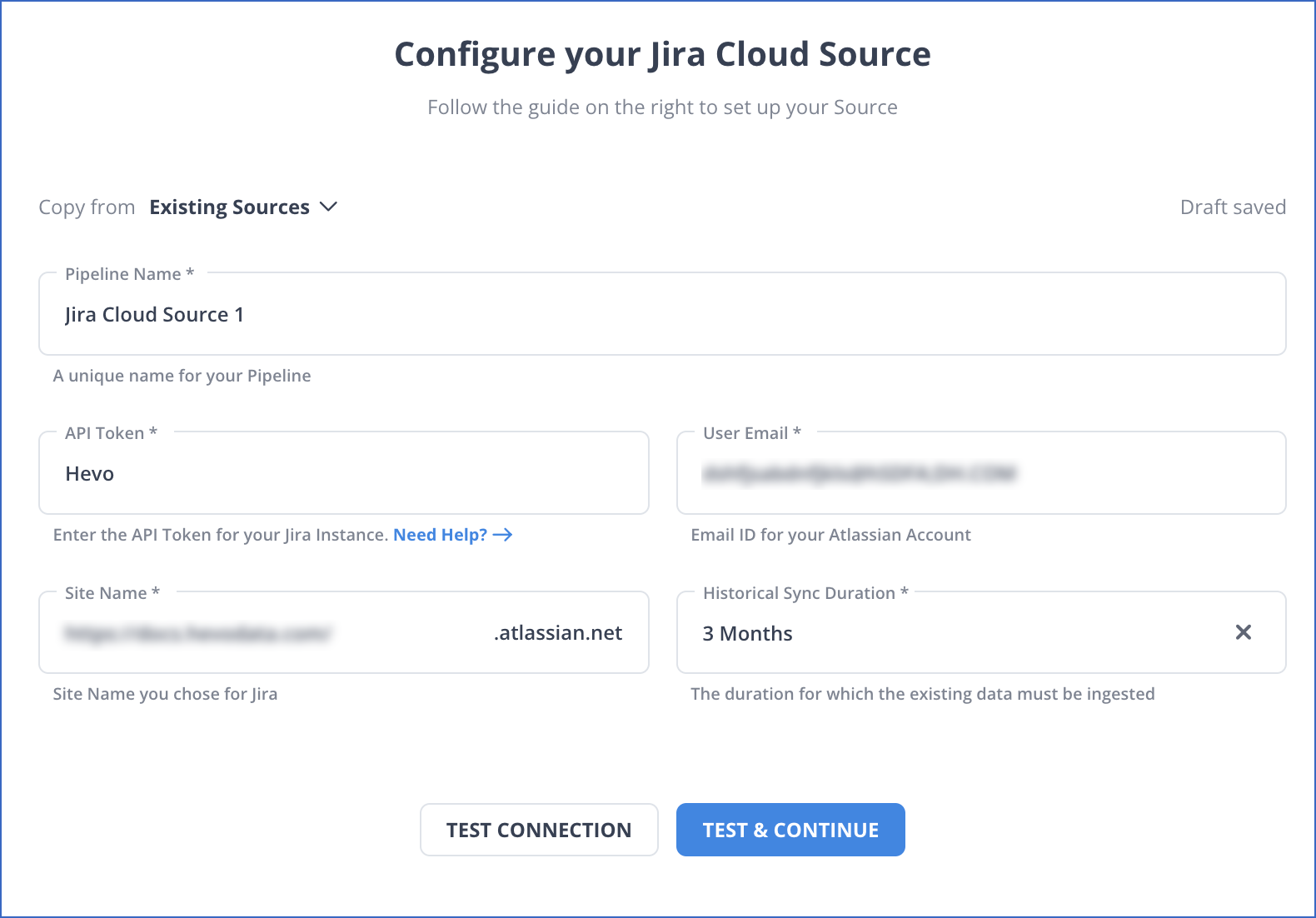
Step 2: Configure Databricks as a Destination

Now, everything will be taken care of by Hevo Data. It will automatically replicate new and updated data from Jira to Databricks every 1 hour (by default). However, you can also increase the pipeline frequency as per your requirements.
You can also visit the official documentation of Hevo Data for Jira as a source and Databricks as a destination to have in-depth knowledge about the process.
You can also read more about:
- Google Sheets to Databricks
- Databricks Connect to SQL Server
- Databricks to S3
- Databricks ETL Methods
Conclusion
In this blog, we have provided you with an easy step-by-step guide on how you can replicate your Jiraa data to Databricks using Hevo. This provides your organisation to receive updated data catered to your requirements, enabling them to track projects and sprint progress in real time.
Saving countless hours of manual data cleaning & standardizing, Hevo Data’s pre-load data transformations get it done in minutes via a simple drag-and-drop interface or your custom Python scripts. No need to go to your data warehouse for post-load transformations. You can simply run complex SQL transformations from the comfort of Hevo Data’s interface and get your data in the final analysis-ready form.
Saving countless hours of manual data cleaning & standardizing, Hevo Data’s pre-load data transformations get it done in minutes via a simple drag n drop interface or your custom python scripts. No need to go to your data warehouse for post-load transformations. You can simply run complex SQL transformations from the comfort of Hevo Data’s interface and get your data in the final analysis-ready form.
Want to take Hevo Data for a ride? Sign up for a 14-day free trial and simplify your data integration process. Check out the pricing details to understand which plan fulfills all your business needs.
FAQ
How to connect Jira to Databricks?
To connect Jira to Databricks, you can use a data integration tool like Apache NiFi or Talend to extract data from Jira and load it into Databricks. Alternatively, you can use the Jira REST API to retrieve data and then use Databricks to process it.
How do I pull data from Jira?
You can pull data from Jira using the Jira REST API, which allows you to query issues, projects, and other data. You can also use tools like Jira’s built-in export functionality to download data in formats like CSV or Excel.
How to connect Jira to a database?
You can connect Jira to a database by using an integration tool like Jira Database Connector or a middleware solution such as Apache Nifi. You may also write custom scripts using the Jira API to extract data and insert it into your target database.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





