




 Key takeaways
Key takeawaysa. Method 1: Replicate Data from MariaDB to Databricks Using Hevo (Recommended)
- Ideal when you need continuous updates from MariaDB to Databricks without manual intervention.
b. Method 2: Replicate Data from MariaDB to Databricks Using CSV
- Works well when the dataset is small to medium or when real-time replication is not required
c. Databricks Partner Connect (Recommended for Destination Setup)
- Ideal for teams using Databricks Premium who want a quick, hassle-free setup.
d. Databricks Credentials (Manual Destination Setup)
- Useful when Partner Connect is not available or you want granular customization.
Unlock the full potential of your MariaDB data by integrating it seamlessly with Databricks. With Hevo’s automated pipeline, get data flowing effortlessly—watch our 1-minute demo below to see it in action!
When your team needs to connect MariaDB to Databricks, they’re looking to you to get the job done quickly and smoothly. They’re ready to dive into the data for important insights, whether it’s for reporting or deeper analysis. If this is just a quick, one-time thing, exporting CSV files is the fastest way to go. But if you want something more sustainable and less manual, a no-code integration tool can automate everything, saving you time and effort while ensuring your team gets the data they need without delay.
Well, look no further. With this article, get a step-by-step guide to connecting MariaDB to Databricks effectively and quickly delivering data to your marketing team.
Table of Contents
Methods to Set up MariaDB to Databricks Migration
Method 1 : Using Hevo
Step 1: Configure MariaDB as a Source:
Once the database is ready, connect it to Hevo and configure MariaDB as your source.

- In the Navigation Bar, click Pipelines.
- Click + Create Pipeline.
- On the Select Source Type page, choose MariaDB.
- Enter the required details on the Configure your MariaDB Source page.
Step 2:
- Pipeline Name: Provide a unique name for your Pipeline (up to 255 characters).
- Database Host: Enter the IP address or DNS of your MariaDB server.
- Example hosts:
| Variant | Host Example |
| Amazon RDS MySQL | mysql-rds-1.xxxxx.rds.amazonaws.com |
| Azure MySQL | mysql.database.windows.net |
| Generic MySQL | 10.123.10.001 or mysql-replica.westeros.inc |
| Google Cloud MySQL | 35.220.150.0 |
- Note: Exclude http:// or https:// when entering hostnames.
- Database Port: The port used by your MariaDB server. The default is 3306.
- Database User: The user account with read permissions for your database.
- Database Password: The password for the above user.
- Database Name: The database you want to replicate. Required for Table or Custom SQL ingestion modes.
Step 3:

Select the mode for ingesting data:
- BinLog (default): Captures real-time changes.
- Table: Replicates entire table data.
- Custom SQL: Runs user-defined queries. (All events here are billable.)
Step 4:
- Connect through SSH: Use an SSH tunnel for added security, so your database is not directly exposed.
- If SSH is not enabled, ensure that Hevo’s IP addresses are whitelisted in your database configuration.
Step 5:

- Load All Databases: If enabled, Hevo replicates data from all databases on the host. If disabled, specify the databases manually.
- Load Historical Data: Choose whether Hevo should import all existing data during the first run or only capture new changes.
- Merge Tables: Allows merging of tables with the same name across multiple databases.
- Include New Tables: Automatically ingests data from new or recreated tables.
After filling in the details:
- Click Test Connection to verify the setup.
- If successful, click Test & Continue to proceed with setting up the Destination.
Configure Databricks as a Destination:
Hevo supports Databricks on AWS, Azure, and GCP. You can connect your Databricks warehouse to Hevo in two ways:
- Using Databricks Partner Connect (recommended)
- Using Databricks credentials
Prerequisites
Before you begin, ensure that the following requirements are met:
- Your Databricks account is on the Premium plan (or above) if you plan to use Partner Connect.
- An active AWS, Azure, or GCP account with a Databricks workspace already created.
- The workspace allows connections from Hevo’s IP addresses (relevant only if IP access lists are enabled).
Approach 1 – Connect Using Databricks Partner Connect (Recommended)
The easiest way to connect Databricks with Hevo is through Partner Connect.

- Log in to your Databricks account.
- From the left navigation pane, click Partner Connect.
- Under Data Ingestion, select Hevo.
- In the Connect to partner pop-up, choose the Catalog where Hevo should write data, and click Next.

- Review your Databricks resources. If needed, update the Compute field and click Next.

- Click Connect to Hevo Data.

- Sign up for or log in to Hevo. You’ll be redirected to the Configure your Databricks Destination page.

At this point, key fields like Server Hostname, Port, HTTP Path, PAT, and Catalog Name are auto-populated. Be sure to save the PAT securely as you may need it later.
Approach 2 – Connect Using Databricks Credentials
- On the Configure Destination page in Hevo, enter the following details:
- Destination Name: A unique identifier (up to 255 characters).
- Schema Name: The database schema where data will be loaded (default: default).
Advanced Settings
- Populate Loaded Timestamp: Adds a __hevo_loaded_at_ column to track when each record was ingested.
- Sanitize Table/Column Names: Cleans up column names by replacing spaces and non-alphanumeric characters with underscores.
- Create Delta Tables in External Location: Automatically managed when using Partner Connect.
- Vacuum Delta Tables: Periodic cleanup of Delta tables to remove old/uncommitted files (may incur Databricks charges).
- Optimize Delta Tables: Improves query performance by running optimization jobs weekly (may also incur charges).
Final Steps
- Click Test Connection to validate your setup.
- Once successful, click Save & Continue.
If your workspace has IP access lists enabled, ensure that Hevo’s IP addresses for your region are allowed.
Why Choose Hevo?
- Fully Managed: You don’t need to dedicate time to building your pipelines. With Hevo’s dashboard, you can monitor all the processes in your pipeline, thus giving you complete control over it.
- Data Transformation: Hevo provides a simple interface to cleanse, modify, and transform your data through drag-and-drop features and Python scripts. It can accommodate multiple use cases with its pre-load and post-load transformation capabilities.
- Faster Insight Generation: Hevo offers near real-time data replication, so you have access to real-time insight generation and faster decision-making.
- Schema Management: With Hevo’s auto schema mapping feature, all your mappings will be automatically detected and managed to the destination schema.
- Scalable Infrastructure: With the increase in the number of sources and volume of data, Hevo can automatically scale horizontally, handling millions of records per minute with minimal latency.
- Transparent pricing: You can select your pricing plan based on your requirements. Different plans are clearly put together on its website, along with all the features it supports. You can adjust your credit limits and spend notifications for any increased data flow.
- Live Support: The support team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.
Method 2: Replicate Data from MariaDB to Databricks Using CSV
To start replicating data from MariaDB to Databricks, firstly, you need to export data as CSV files from MariaDB, then import the CSV files into Databricks and modify your data according to the needs.
Step 1: Export the database as CSV from MariaDB
Below is the command in general format to export your data
Select field from table_name
INTO OUTFILE '/path/to/save/filename.csv'
FIELDS ENCLOSED BY ''
TERMINATED BY ','
ESCAPED BY '"'
LINES TERMINATED BY '\n';Step 2: Create a Table in Databricks by Uploading CSV Files
In the Databricks UI, use the sidebar menu to find data and create a table either by browsing your files from the local computer or dragging your CSV files into the drop zone.
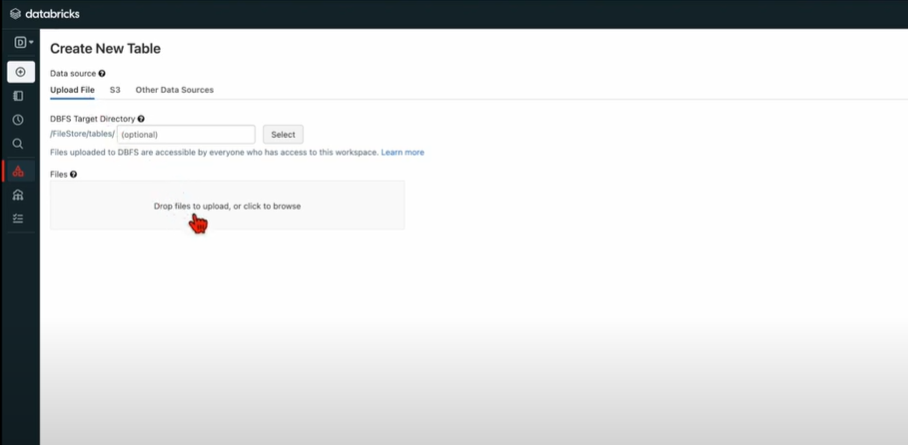
Your path will look something like this:
/FileStore/tables/<fileName>-<integer>.<fileType>
Once uploaded, you can simply view your data by clicking the Create Table with UI button.
Step 3: After you upload the CSV data to Databricks, you can read and modify the data.
- To preview a cluster, click on the Preview Table after selecting it. Databricks now lets you read your CSV data.
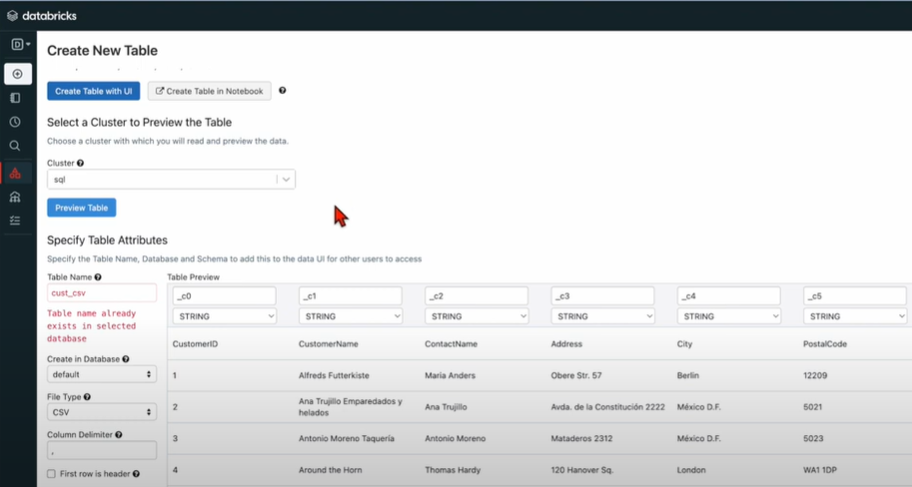
- In Databricks, data types are string by default. You can choose the data type from a list of options.
- The left navigation bar can help you modify the data easily. To create a table, click the “Create Table” button on the left navigation bar.
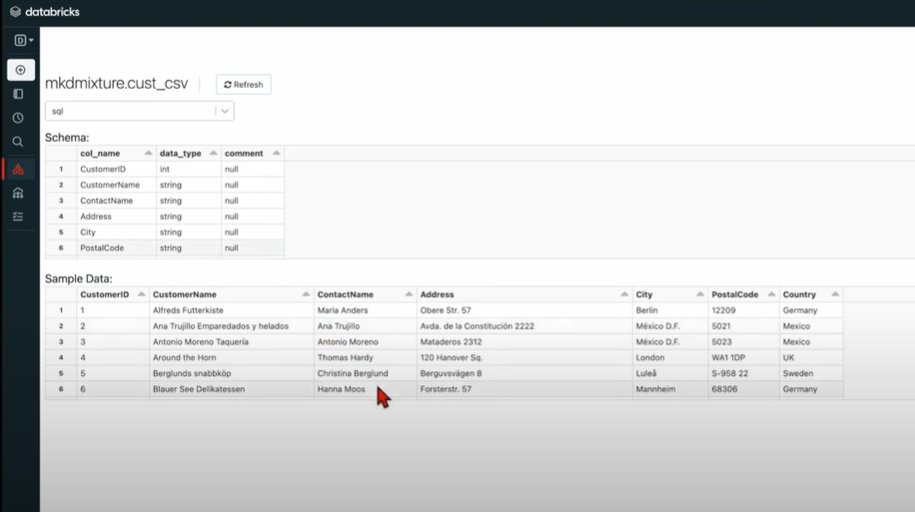
- Once all the table settings have been configured, click the “Create Table” button to finish.
The CSV files can be accessed from the cluster where you have stored that file.
This 3-step process using CSV files is a great way to effectively replicate data from MariaDB to Databricks. It is optimal for the following scenarios:
- One-Time Data Replication: When your marketing team needs the MariaDB data only once in a long period of time.
- No Data Transformation Required: If there is a negligible need for data transformation and your data is standardized, then this method is ideal.
In the following scenarios, using CSV files might be cumbersome and not a wise choice:
- Data Mapping: Only basic data can be moved. Complex configurations cannot take place. There is no distinction between text and numeric values and null and quoted values.
- Frequent changes in Source Data: To achieve two-way synchronization, the entire process must be run frequently to access updated data on the destination.
- Time Consuming: If you plan to export your data frequently, the CSV method might not be the best choice since it takes time to recreate the data using CSV files.
Say goodbye to the hassle of moving your MariaDB data to Databricks with Hevo! It’s fast, reliable, and lets you focus on what truly matters.
Why Hevo is the perfect choice?
- No need for complex configurations.
- Keeps your data up-to-date with continuous real-time syncing
- Spend less time on manual data tasks and more time on decision-making with automated data flows.
See why Databricks partnered with Hevo!
Let Hevo handle the heavy lifting and experience seamless data integration today
Get Started with Hevo for FreeWhat is MariaDB?

MariaDB is an open-source relational database management system (RDBMS) that was created as fork of MySQL. It is developed by the original developers of MySQL. It is designed to offer enhanced performance, improved scalability and data processing capabilities. It maintains its compatibility with MySQL.
Features of MariaDB
- MySQL Compatibility: It was designed to be fully compatible with MySQL, so the migration from one to another is pretty easy without major application or data changes.
- High Performance and Scalability: MariaDB is designed to efficiently serve hundreds of millions of records. It’s replication, and multiple storage engines enable MariaDB to scale as your application does.
- Security and Flexibility: Some of the advanced security features in MariaDB include encryption and user roles. Advanced SQL functions support complex queries and give you enormous flexibility in managing your data.
What is DataBricks?

Databricks is a cloud-based platform that helps companies manage and analyze big data using tools like Apache Spark. It simplifies the process of setting up and running data pipelines, allowing businesses to quickly make sense of large amounts of data and turn it into useful insights.
Features of Databricks
- Unified Data Platform: Databricks combines data engineering, data science, and machine learning into one place so teams can work together easily.
- Scalable: It can handle both small and huge data workloads, growing with your business as needed, without the hassle of managing servers.
- Integration: Databricks integrates well with cloud platforms like AWS, Azure, and Google Cloud, and also works with popular data storage systems like Snowflake, SQL databases, and data lakes.
What Can You Achieve by Migrating Your Data from MariaDB to Databricks?
Here’s a little something for the data analyst on your team. We’ve mentioned a few core insights you could get by replicating data from MariaDB to Databricks. Does your use case make the list?
- Aggregate the data of individual interactions of the product for any event.
- Finding the customer journey within the product.
- Integrating transactional data from different functional groups (Sales, Marketing, Product, Human Resources) and finding answers. For example:
- Which development features were responsible for an app outage in a given duration?
- Which product categories on your website were most profitable?
- How does failure rate in individual assembly units affect inventory turnover?
You can also read more about:
- MySQL to Databricks
- PostgreSQL to Databricks
- MongoDB to Databricks
- MariaDB to Redshift
- MariaDB to Snowflake
- MariaDB to BigQuery
Conclusion
Exporting and importing CSV files is the right path for you when your team needs data from MariaDB once in a while. However, a custom ETL solution becomes necessary for the increasing data demands of your product or marketing channel. You can free your engineering bandwidth from these repetitive & resource-intensive tasks by selecting Hevo’s 150+ plug-and-play integrations.
Discover how Databricks Lakehouse Monitoring complements seamless data migration from MariaDB to Databricks by providing robust tracking and insights.
Saving countless hours of manual data cleaning & standardizing, Hevo’s pre-load data transformations get it done in minutes via a simple drag-and-drop interface or your custom Python scripts. No need to go to your data warehouse for post-load transformations. You can simply run complex SQL transformations from the comfort of Hevo’s interface and get your data in the final analysis-ready form.
Want to take Hevo for a ride? Sign up for a 14-day free trial and simplify your data integration process. Check out the pricing details to understand which plan fulfills all your business needs.
FAQs
1. How do I transfer data to Databricks?
Use Hevo to transfer data to Databricks with a simple, no-code setup. It automates the process for you.
2. What is Databricks SQL?
Databricks SQL is a tool that helps you run queries on your data to understand and visualize it easily.
3. How to connect MySQL database to Databricks?
Select MySQL as a source and Databricks as a destination in Hevo to set up the data pipeline.
Share your experience of replicating data from MariaDB to Databricks! Let us know in the comments section below!

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link










