



Modern applications nowadays use NoSQL Databases to manage flexible data. Many micro-services require a real-time stream of data to power up the application. There are many NoSQL databases available in the market. Amazon DynamoDB is a powerful Database that can auto-scale automatically and deliver high performance to the applications.
Amazon Redshift is a Data Warehouse service that stores business data for analysis. Connecting Redshift to DynamoDB allows users to transfer data from Redshift Data Warehouse to DynamoDB Database. It helps developers to use historical data from Redshift to DynamoDB and power up the application.
Connecting Amazon Redshift to DynamoDB Database enables easy data flow. In this article, you will learn about Amazon Redshift, DynamoDB, and its features. You will learn the steps to connect Amazon Redshift to DynamoDB Database.
Table of Contents
Prerequisites
- An active Amazon Redshift Cluster.
- An active Amazon DynamoDB Database.
- Access to AWS S3 Bucket.
Exporting your data from Redshift and DynamoDB doesn’t have to be complex. Relax and go for a seamless migration using Hevo’s no-code platform. With Hevo, you can:
- Effortlessly extract data from 150+ connectors.
- Tailor your data needs with features like drag-and-drop and custom Python scripts.
- Achieve lightning-fast data loading into your desired destination, making your data analysis-ready.
Try to see why customers like Eagle Point and Harmoney have upgraded to a powerful data and analytics stack by incorporating Hevo!
Get Started with Hevo for FreeWhat is Amazon Redshift?

Amazon Redshift is a fully managed Data Warehouse by Amazon Web Service (AWS) that can handle petabytes of data. It delivers high performance for querying data and real-time analysis, and as it is a part of AWS, it can easily integrate with other AWS products to expand its functionalities.
Amazon Redshift supports standard SQL to query data, and analyze structures as well as semi-structured data across Data Warehouses, Operational Databases, and Data Lakes.
Key Features of Amazon Redshift
Some of the main features of Amazon Redshift are listed below:
- Query Editor: Amazon Redshift comes with a powerful query editor that supports SQL to allow users to access data from Data Warehouses and Data Lakes. It helps you visualize query results in a single click.
- Fault Tolerant: Amazon Redshift continuously monitors the health of the clusters and automatically replicates data from nodes as necessary for fault tolerance which increases the reliability.
- Redshift ML: Amazon Redshift comes with its ML environment that makes it easier for users to create, train, and deploy Amazon SageMaker models using SQL.
To learn more about Amazon Redshift, visit the official website.
What is Amazon DynamoDB?

Amazon DynamoDB is a fully managed NoSQL Database that supports key–value and document data structures. It is a part of the Amazon Web Services portfolio. DynamoDB is designed to run a high-performance application at any scale.
It is well suited for real-time data capture, similar to CDC (Change Data Capture), it comes with DynamoDB Stream that stores the events in a log for 24 hours with no flexibility to extend.
Key Features of Amazon DynamoDB
Some of the main features of Amazon DynamoDB are listed below:
- Serverless: Amazon DynamoDB doesn’t require any server to provision, patch, or manage and no software to install or maintain. It automatically scales tables to maintain performance and storage.
- DynamoDB Accelerator (DAX): Amazon DynamoDB comes with a highly available in-memory cache that improves the performance by 10 times by adding in-memory acceleration to the tables.
- Auto-Scaling: Amazon DynamoDB automatically scales the throughput and storage of the Database based on the previous capacity.
To learn more about Amazon DynamoDB, visit the official website.
Steps to Connect Redshift to DynamoDB
In this section, you will go through the manual process to connect Amazon Redshift to DynamoDB. As DynamoDB doesn’t directly load data from Amazon Redshift. So for this, you need first extract data from Amazon Redshift to the S3 bucket and then load this data from AWS S3 to DynamoDB. The following steps to connect Redshift to DynamoDB via S3 are listed below:



Step 1: Unloading Data from Redshift to S3
- Go to your Amazon Redshift Console.

- Here, you are going to use the UNLOAD command with the SELECT statement to query your table and locate data then you need to provide the location of your S3 bucket where you want to load your data.
- Also, you need to provide your IAM Role. The following command is given below:
unload ('select * from venue')
to 's3://mybucket/tickit/unload/venue_'
iam_role 'arn:aws:iam::0123456789012:role/MyRedshiftRole';- Here, the example table name is “venue” and in the S3 location, the “venue_” is the prefix of the files that will save in your bucket. The files will save in a similar as shown below:
venue_0000_part_00
venue_0001_part_00
venue_0002_part_00
venue_0003_part_00Step 2: Importing Data from Amazon S3 to DynamoDB
To connect Amazon Redshift to DynamoDB, you need to export Redshift Data saved in the S3 bucket to DynamoDB. For this, your DynamoDB should already have the table created as per the data format of Redshift.
To load data from Redshift to DynamoDB, your table should not be empty. Though, while importing data from Redshift to DynamoDB, it will replace the existing data with a new one that has the same keys. To import data from S3 to DynamoDB follow the steps given below:
- Sign in to your AWS Management Console and open the AWS Data Pipeline.
- Here, click on the Create new pipeline button.
- Here, it will open a Create Pipeline page where you need to provide all the essential details.
- In the Name text field, you need to provide the name of your Pipeline to connect Redshift to DynamoDB. For example, you can name the Pipeline “RedshiftToDynamoDBPipeline”
- In the source parameter, you need to select the Build using a template option. Now from the drop-down list of templates, select the Import DynamoDB backup data from the S3 option.
- In the Input S3 Folder text field, you need to provide the URI of the location of the S3 bucket where your Redshift data exists. In this example, the location of the S3 bucker is “s3://mybucket/tickit/”.
- In the Target DynamoDB table name text field you need to provide the name of the DynamoDB table where you want to load your Redshift data.
- In the S3 location for the logs text field, you need to provide the URI of the S3 bucket where you want to write the log file for the import of data from Redshift to DynamoDB. For example, the URI can be “s3://mybucket/logs”
- Now, add a tag with the Key dynamodbdatapipeline and the Value true.
- After reviewing all the configurations, click on the Activate button.
- This will create your data pipeline to import data from Redshift to DynamoDB via AWS S3. The process may take several minutes to complete depending on the volume of data.
Also, take a look at how you can Connect Amazon Redshift to SQL Server to learn other ways in which you can export your Redshift data.
Using Hevo to Automate Data Sync from Redshift
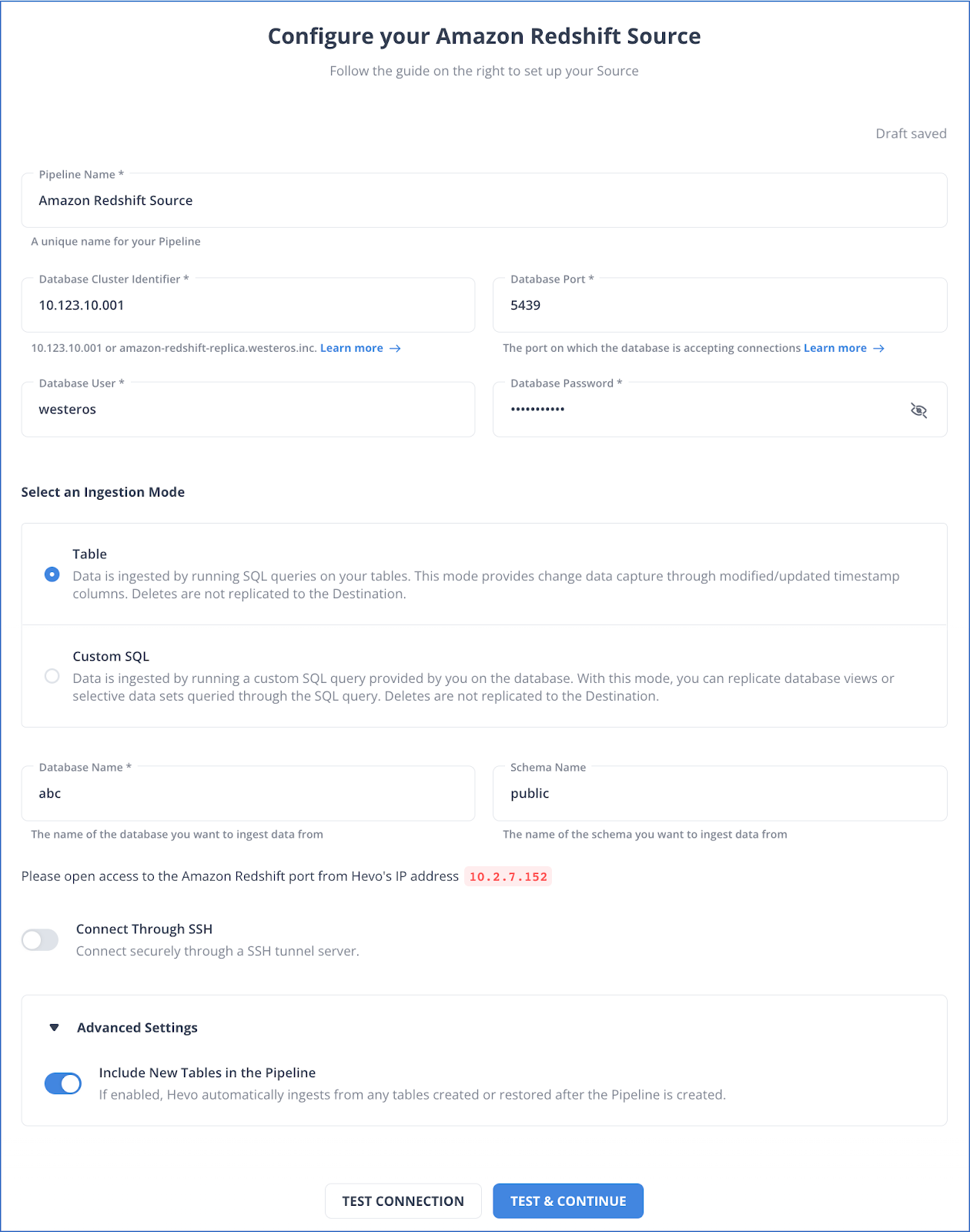
Step 1: Configure Redshift as your Source
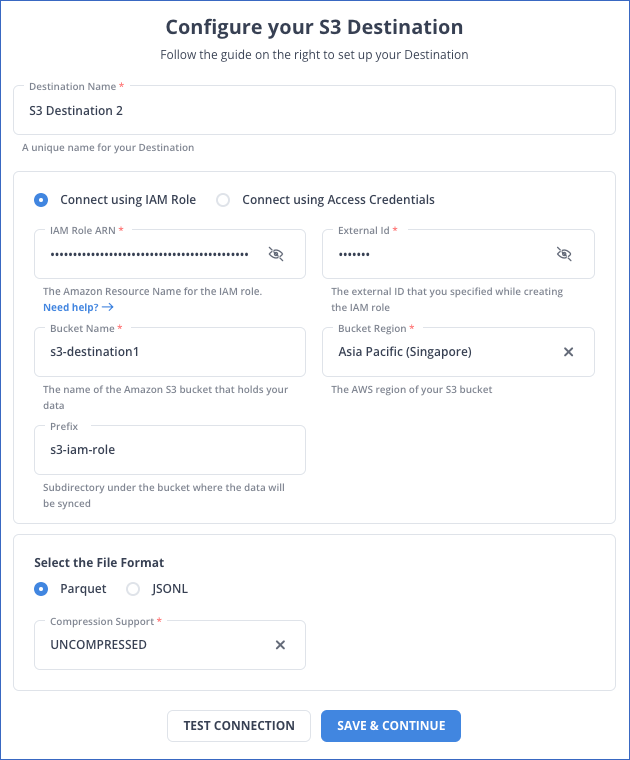
Step 2: Configure your Desired Destination
Hevo supports a wide range of destinations where you can replicate your Redshift data.For example, you can configure Amazon S3 as your desired destination.
What Makes Hevo Amazing?
- Secure: Hevo has a fault-tolerant architecture that ensures that the data is handled in a secure, consistent manner with zero data loss.
- Auto Schema Mapping: Hevo takes away the tedious task of schema management & automatically detects the schema of incoming data from Salesforce and replicates it to the destination schema.
- Quick Setup: Hevo with its automated features, can be set up in minimal time. Moreover, with its simple and interactive UI, it is extremely easy for new customers to work on and perform operations.
- Incremental Data Load: Hevo allows the transfer of data that has been modified in real-time. This ensures efficient utilization of bandwidth on both ends.
- Live Support: The Hevo team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.
Conclusion
In this article, you learned about Amazon Redshift, Amazon DynamoDB Database and their main features. You also went through the steps to how to transfer data from Amazon Redshift to DynamoDB Database. DynamoDB is a NoSQL Database and Amazon Redshift is a widely used Data Warehouse for fast performance and real-time analysis. Connecting Redshift to DynamoDB powers backend services, applications and web services.
Sign up for a 14-day free trial and simplify your data integration process. Check out the pricing details to understand which plan fulfills all your business needs.
Frequently Asked Questions
1. Is it possible to load data from Amazon DynamoDB into Amazon Redshift?
Yes, it is possible to load data from Amazon DynamoDB into Amazon Redshift.
2. Does DynamoDB replicate data?
Yes, Amazon DynamoDB replicates data to ensure high availability and durability.
3. What does DynamoDB do?
Amazon DynamoDB is a fully managed NoSQL database service provided by AWS that offers high performance, scalability, and reliability for applications that require consistent, single-digit millisecond response times.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





