
 Key Takeaways
Key TakeawaysMigrating data from Oracle to Amazon Redshift using custom ETL scripts involves exporting data from Oracle typically as CSV files then uploading these files to Amazon S3, and finally loading them into Redshift using the COPY command.
With Hevo, this migration can be achieved using two simple steps with a friendly UI. Here’s a breakdown of the two methods:
Method 1: Using Manual ETL Scripts
Step 1: Exporting Data from an Oracle Table via Spool
Step 2: Copying a Flat File onto an AWS S3 Bucket
Step 3: Creating an Empty Table and Loading Data from the AWS S3 Bucket
Method 2: Using Hevo Data
Step 1: Configure Oracle as your Source
Step 2: Configure Amazon Redshift as your Destination
Is your Oracle server getting too slow for analytical queries now? Or do you think you are paying too much money to increase the storage capacity or compute power of your Oracle instance? Or are you looking to join and combine data from multiple databases seamlessly? Whatever the case may be, Amazon Redshift offers amazing solutions to the above problems. Hence there is little to think about before moving your data from an Oracle to Amazon Redshift cluster.
This article covers the basic idea behind the two architectures and the detailed steps you need to follow to migrate data from Oracle to Redshift. Additionally, it also covers why you should consider implementing an ETL solution such as Hevo Data to make the migration smooth and efficient.
Table of Contents
Overview of Oracle

Oracle Corporation offers an integrated workgroup of enterprise software, mostly spotlighted by its relational database management system. Oracle Database is highly rated in terms of performance, scalability, and reliability in service delivery, suiting diverse business applications.
It supports complex transactions, high-volume data processing, and enterprise-level applications. Oracle Database also supports advanced features like in-memory processing, real-time analytics, and multi-model capabilities, making it a versatile solution for diverse data management needs.
Use Cases
Let’s discuss some of Oracle’s key use cases.
- Enterprise Resource Planning (ERP): By using Oracle, you can manage core business processes such as finance, HR and supply chain.
- Customer Relationship Management (CRM): You can also use it for customer data handling, sales processes, and marketing effort handling.
- Application Development: It supports the development and fielding of complex applications with high availability and performance requirements.
Method 1: Custom ETL Scripts to Load Data from Oracle to Redshift
In this method, you can integrate your data from Oracle to Redshift using Custom ETL Scripts in a full load or incremental load manner. Even though this method works, but it can be complex and time-consuming.
Method 2: Setting Up Oracle to Redshift Integration using Hevo Data
Alternatively, using Hevo you can be rest assured that your integration will take place seamlessly in just two easy steps. Hevo supports 150+ sources like Oracle to destination warehouses such as Redshift, all you need to do is provide Hevo access to your data.
Get Started with Hevo for FreeOverview of Amazon Redshift

Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. It provides swift query and analytics functionality across large sets of data using SQL. Redshift is optimised for high-performance analytics and works seamlessly with other AWS services. It provides scalability, cost efficiency, and usability to big data environments.
Use Cases
- Data Warehousing: It centralises large amounts of structured data from various sources and analyzes the data with the purpose of business intelligence and reporting.
- Business Intelligence (BI): It can integrate with BI tools to visualise and explore data for strategic decision-making.
- Real-Time Analytics: Inspecting streaming data and logs nearly in real time, it is capable of monitoring and reacting to operational metrics.
Methods to Load Data from Oracle to Redshift

There are majorly 2 methods of loading data from Oracle to Redshift:
Let’s walk through these methods one by one.
Method 1: Custom ETL Scripts to Load Data from Oracle to Redshift
It is a really easy and straightforward way to move data from Oracle to Amazon Redshift. This method involves 4 major steps:
- Step 1: Exporting Data from an Oracle Table via Spool
- Step 2: Copying a Flat File onto an AWS S3 Bucket
- Step 3: Creating an Empty Table and Loading Data from the AWS S3 Bucket
These steps are illustrated in technical detail via an example in the following section. You can also simplify this process by using efficient Oracle ETL tools.
Step 1: Exporting Data from an Oracle Table via Spool
One of the most common ways to export Oracle data onto a flat-file is using the Spool command. Here’s an example of how to do it –
SPOOL c:oracleorgemp.csv
SELECT employeeno || ',' ||
employeename || ',' ||
job || ',' ||
manager || ',' ||
TO_CHAR(hiredate,'YYYY-MM-DD') AS hiredate || ',' ||
salary || ',' ||
FROM employee
ORDER BY employeeno;
SPOOL OFFThe above code exports all records available in employees into the emp.csv file under the org folder as mentioned. The CSV file could then be zipped (using “$ gzip emp.csv”) for compression before moving to the AWS S3 Bucket.
Here’s how the output of your command will be in the c:oracleorgemp.csv file:
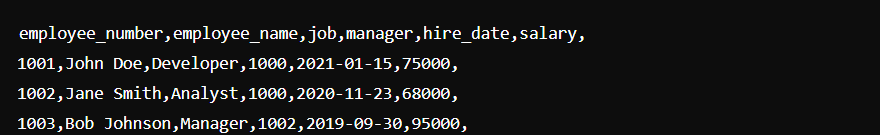
Step 2: Copying a Flat File onto an AWS S3 Bucket
AWS provides S3 Buckets to store files that could be loaded into an Amazon Redshift instance using the COPY command. To drop a local file into an AWS S3 Bucket, you could run a ‘COPY command’ on the AWS Command Line Interface. Here’s how you would do it –
aws s3 cp //oracle/org/emp.csv s3://org/empl/emp.csv.gzHowever, if you’d prefer the Graphical User Interface (GUI) way, you could go over to your AWS S3 console https://console.aws.amazon.com/s3/home, and copy-paste your “emp.csv” file into the desired Amazon S3 Bucket.

Step 3: Creating an Empty Table and Loading Data from the AWS S3 Bucket
Before running the COPY command, an empty table must be created in the database to absorb the “emp.csv” file now available on the Amazon S3 Bucket.
The employee table on Redshift can be created using the following code:
SET SEARCH_PATH TO PUBLIC; // selecting the schema
CREATE TABLE EMPLOYEE (
cmployeeno INTEGER NOT NULL,
employeename VARCHAR,
job VARCHAR,
manager VARCHAR,
hiredate DATE,
salary INTEGER
DISTKEY(hiredate)
SORTKEY(employeeno)
)The flat file copied over to S3 can be loaded into the above table using the following :
SET SEARCH_PATH TO PUBLIC;
COPY EMPLOYEE
FROM 's3://org/empl/emp.csv.gz'
'AWS_ACCESS_KEY_ID=MY_ACCESS_KEY AWS_SECRET_ACCESS_KEY=MY_SECRET_KEY'
GZIP;Once you are done with the above steps, you need to increment the load from Oracle to Redshift. So, keep reading!
Incremental Load from Oracle to Redshift
The above is an example to demonstrate the process of moving data from Oracle to Redshift. In reality, this would be performed, typically every day, on an entire database consisting of 10s or 100s of tables in a scheduled and automated fashion. Here is how this is done.
- Step 1: Iterative Exporting of Tables
- Step 2: Copying CSV Files to AWS S3
- Step 3: Importing AWS S3 Data into Redshift
Step 1: Iterative Exporting of Tables
The following script will go through each table one by one. Next, it will export the data in each of them into a separate CSV file with the filename as the *name of the table*_s3.
begin
for item in (select table_name from user_tables)
loop
dbms_output.put_line('spool '||item.table_name||'_s3.csv');
dbms_output.put_line('select * from'||item.table_name||’;’);
dbms_output.put_line('spool off');
end loop;
end;
Step 2: Copying CSV Files to AWS S3
The exported .csv files can be uploaded to an S3 bucket using the following command:
aws s3 cp <your directory path> s3://<your bucket name> --grants read=uri=http://acs.amazonaws.com/groups/global/AllUsers --recursive
Step 3: Importing AWS S3 Data into Redshift
As mentioned before, this process is typically done every 24 hours on a whole lot of data. Hence, you must ensure that there is no data loss as well as no duplicate data. The 2nd part (duplicate data) is particularly relevant when copying data over to Redshift because Redshift doesn’t enforce Primary Key constraints.
Now, you can drop all the data in your Redshift instance and load the entire Oracle Database every time you are performing the data load. However, this is quite risky in regards to data loss and also very inefficient and computationally intensive. Hence, a good way to efficiently perform the data loads while ensuring data consistency would be to:
- Copy the AWS S3 flat file data into a temp table: This is achieved by running the ‘COPY’ command the same way as explained in “Step 3” before.
- Compare the temp table data with the incoming data (the .csv files): See the section Data Loads: SCD Type 1 and Type
- Resolve any data inconsistency issues: See the section Data Loads: SCD Type 1 and Type 2
- Remove data from the Parent Table and copy the new and clean up data from the Temp Table. Run the following commands:
You can simplify this whole method by connecting to OracleDB.
begin;
delete from employee where *condition* (depends on what data is available in the temp table)
insert into employee select * from emp_temp_table;
end; 
Data Loads – SCD Type 1 and Type 2
Generally, while comparing the existing table data with the new stream of data (S3 bucket data, in this case) one or both of the following methods is used to complete the data load:
Type 1 or Upsert: A new record is either inserted or updated. The update happens only when the primary key of the incoming record matches with the primary key of an existing record. Here is an example:
Existing Record:
| Employeename | Employeenum | Job |
| John | 123 | Sales |
Incoming Record:
| Employeename | Employeenum | Job |
| John | 123 | Operations |
Final Table (After Upsert):
| Employeename | Employeenum | Job |
| John | 123 | Operations |
Type 2 or Maintain History: In this scenario, if the primary key of the incoming record matches with the primary key of an existing record, the existing record is end dated or flagged to reflect that it is a past record. Here is the Type 2 for the above example –
Existing Record:
| Employeename | Employeenum | Job |
| John | 123 | Sales |
Incoming Record:
| Employeename | Employeenum | Job |
| John | 123 | Operations |
Final Table (After Type 2):
| Employeename | Employeenum | Job | Activeflag |
| John | 123 | Operations | 1 |
| John | 123 | Sales | 0 |
Limitations of Using Custom ETL Scripts to Load Data from Oracle to Redshift
Although a Custom Script (or more likely a combination of Custom Scripts) written to execute the above steps will work, it will be tedious to ensure the smooth functioning of such a system due to the following reasons:
- There are many different steps that need to be executed in a dependent fashion without failure.
- The incremental load is especially difficult to code and execute in such a way as to ensure there is no data loss and/or data inconsistencies. Doing a full load every time puts a lot of load on the Oracle database.
- As mentioned, this is typically done once every day. Lately, however, people want to look at more real-time data. Hence, this will have to be executed a lot more frequently than once in 24 hours. That is going to test the robustness and thoroughness of your solution a lot more.
Method 2: Setting Up Oracle to Redshift Integration using Hevo Data
Using Hevo Data, you can easily integrate your data from Oracle to Redshift in just two easy steps. I have shown you step-by-step how you can integrate your data successfully.
Step 1: Configure Oracle as your Source
You can select Oracle as your source and give hevo access to your database credentials.
Step 1.1: Select Oracle as the Source.
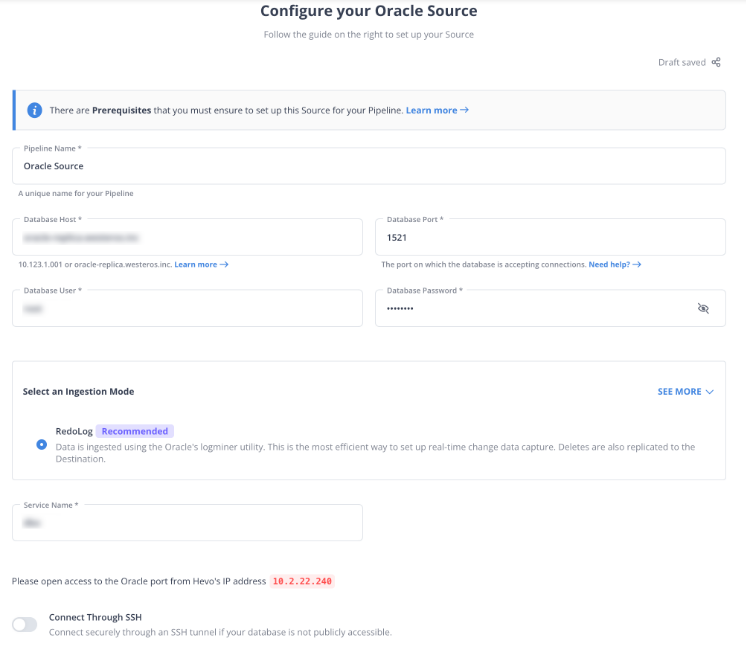
Step 1.2: Provide credentials to your Oracle database, such as database username and password.
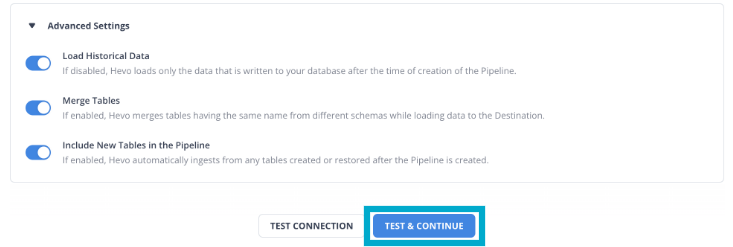
Step 1.3: Choose the Advanced settings and Click on Test & Continue.
Step 2: Configure Amazon Redshift as your Destination
You can select Redshift as your destination and provide Hevo access to your Redshift account.
Step 2.1: Select Redshift as your Destination.
Step 2.2: Provide access to your Redshift account and fill in the required details such as username, password, and database name where you want to store the data.

Step 2.3: Click on Save & Continue.
That’s it. You have successfully integrated your data from Oracle into Redshift.
You can also read about:
- How to migrate your data from Oracle to Snowflake
- How to migrate your data from Oracle to Kafka
- How to migrate your data from Databricks to Oracle Database
Conclusion
Furthermore, Hevo has an intuitive user interface that lets, even the not-so-technical people, easily tweak the parameters of your data load settings. This would come in super handy once you have everything up and running.
With Hevo, you can achieve seamless and accurate data replication from Oracle to Redshift. With its fault-tolerant architecture, Hevo ensures that no data is lost while loading. This empowers you to focus on the right projects instead of worrying about data availability.
Want to take Hevo for a spin? Sign up for a 14-day free trial and experience the feature-rich Hevo suite first hand.
Share your experience of loading data from Oracle to Redshift in the comments section below!
FAQs to integrate Oracle to Redshift
1. How do you connect Oracle to Redshift?
To connect Oracle to Redshift, use an ETL tool like AWS Glue or a data integration service like Fivetran to extract data from Oracle and load it into Redshift. Alternatively, use a data migration tool to create a direct connection and perform data transfer operations.
2. How do I create ODBC connection to Redshift?
To create an ODBC connection to Redshift, install the Amazon Redshift ODBC driver, then configure the ODBC Data Source Administrator with the Redshift cluster endpoint, port, and database credentials. Test the connection to ensure successful integration.
3. How to migrate an Oracle Database?
To migrate an Oracle database, use Oracle Data Pump to export the database schema and data, then import it into the target database.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




