




So, you’re a Zendesk user, right? It’s always a pleasure talking to someone who gives utmost priority to the customer experience. Being focused on providing top-notch support to your customers is what makes you a great player.
Zendesk has consolidated dashboards based on multiple reports of customer support data. But, there would be times when this support data needs to be integrated with that of other functional teams. That’s where you come in. You take the responsibility of replicating data from Zendesk to a centralized repository so that analysts and key stakeholders can make super-fast business-critical decisions.
So, to make your work easier, we’ve prepared a simple and straightforward guide to help you replicate data from Zendesk to Databricks. Leap forward and read the 2 simple methods.
Table of Contents
How to Replicate Data From Zendesk to Databricks?
To replicate data from Zendesk to Databricks, you can either use CSV files or a no-code automated solution. We’ll cover replication via CSV files next.
Replicate Data from Zendesk to Databricks Using CSV Files
Zendesk, being a cloud-based customer service platform, stores data about tickets, organizations, and users. You have to run multiple exports for different types of data.
Follow along to replicate data from Zendesk to Databricks in CSV format:
Step 1: Export CSV Files from Zendesk
- Log in to your Zendesk account.
- Click on the Gear icon in the sidebar and select Reports under the Manage section.
- Under the Reporting section, input the time period over which you want to export the data and the type of data you wish to export in the Type field.
- Click on the request file option next to CSV export.
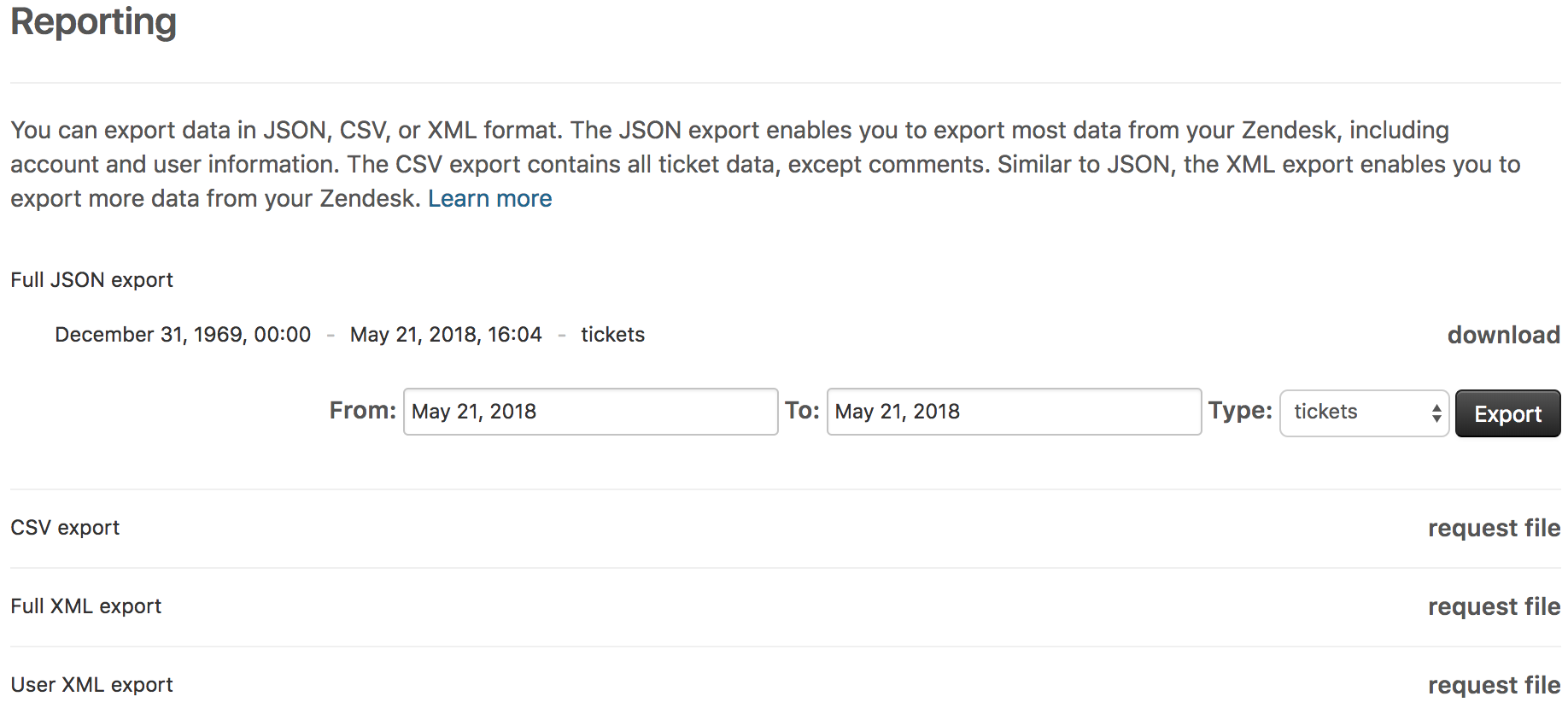
- A background job will now start preparing your file, and you will receive a download link via email once it’s complete.
- Click the link in the email you receive to download the CSV file containing the required data.
Note: Data Export feature is not enabled in all Zendesk accounts. If yours is among them, you can contact Zendesk Customer Support to activate the feature.
Step 2: Import CSV Files into Databricks
- In the Databricks UI, go to the side navigation bar. Click on the “Data” option.
- Now, you need to click on the “Create Table” option.
- Then drag the required CSV files to the drop zone. Otherwise, you can browse the files in your local system and then upload them.
Once the CSV files are uploaded, your file path will look like: /FileStore/tables/<fileName>-<integer>.<fileType>
Step 3: Modify & Access the Data
- Click on the “Create Table with UI” button.
- Now, the data is uploaded to Databricks. You can access the data via the Import & Explore Data section on the landing page.
- To modify the data, select a cluster and click on the “Preview Table” option.
- Then change the attributes accordingly and select the “Create Table” option.
This 3-step process using CSV files is a great way to replicate data from Zendesk to Databricks effectively. It is optimal for the following scenarios:
- Less Amount of Data: This method is appropriate for you when the number of reports is less. Even the number of rows in each row is not huge.
- One-Time Data Replication: This method suits your requirements if your business teams need the data only once in a while.
- No Data Transformation Required: This approach has limited options in terms of data transformation. Hence, it is ideal if the data in your spreadsheets is clean, standardized, and present in an analysis-ready form.
- Dedicated Personnel: If your organization has dedicated people who have to perform the manual downloading and uploading of CSV files, then accomplishing this task is not much of a headache.
This task would feel mundane if you would need to replicate fresh data from Zendesk regularly. It adds to your misery when you have to transform the raw data every single time. With the increase in data sources, you would have to spend a significant portion of your engineering bandwidth creating new data connectors. Just imagine — building custom connectors for each source, transforming & processing the data, tracking the data flow individually, and fixing issues. Doesn’t it sound exhausting?
How about you focus on more productive tasks than repeatedly writing custom ETL scripts, downloading, cleaning, and uploading CSV files? This sounds good, right?
In that case, you can..
Looking for a quick way to integrate Zendesk with Databricks? Look no further! Hevo is a no-code data pipeline platform that simplifies the process, allowing you to replicate your data in two easy steps.
Check out why Hevo should be your go-to choice:
- Minimal Learning: Hevo’s simple and interactive UI makes it extremely simple for new customers to work on and perform operations.
- Schema Management: Hevo eliminates the tedious task of schema management. It automatically detects the schema of incoming data and maps it to the destination schema.
- Live Support: The Hevo team is available 24/7 to extend exceptional customer support through chat, E-Mail, and support calls.
- Secure: Hevo’s fault-tolerant architecture ensures that data is handled securely, consistently, and with zero data loss.
- Transparent Pricing: Hevo offers transparent pricing with no hidden fees, allowing you to budget effectively while scaling your data integration needs.
Thousands of customers trust Hevo for their data integration needs. Join them and experience seamless data integration.
Get Started with Hevo for FreeReplicate Data from Zendesk to Databricks Using an Automated ETL Tool
An automated tool is an efficient and economical choice that takes away a massive chunk of repetitive work. It has the following benefits:
- Allows you to focus on core engineering objectives while your business teams can jump on to reporting without any delays or data dependency on you.
- Your support team can effortlessly enrich, filter, aggregate, and segment raw Zendesk data with just a few clicks.
- Without technical knowledge, your analysts can seamlessly standardize timezones, convert currencies, or simply aggregate campaign data for faster analysis.
- An automated solution provides you with a list of native in-built connectors. No need to build custom ETL connectors for every source you require data from.
For instance, here’s how Hevo, a cloud-based ETL solution makes the data replication from Zendesk to Databricks ridiculously easy:
Step 1: Configure Zendesk as your Source
- Fill in the required attributes required for configuring Zendesk as your source.
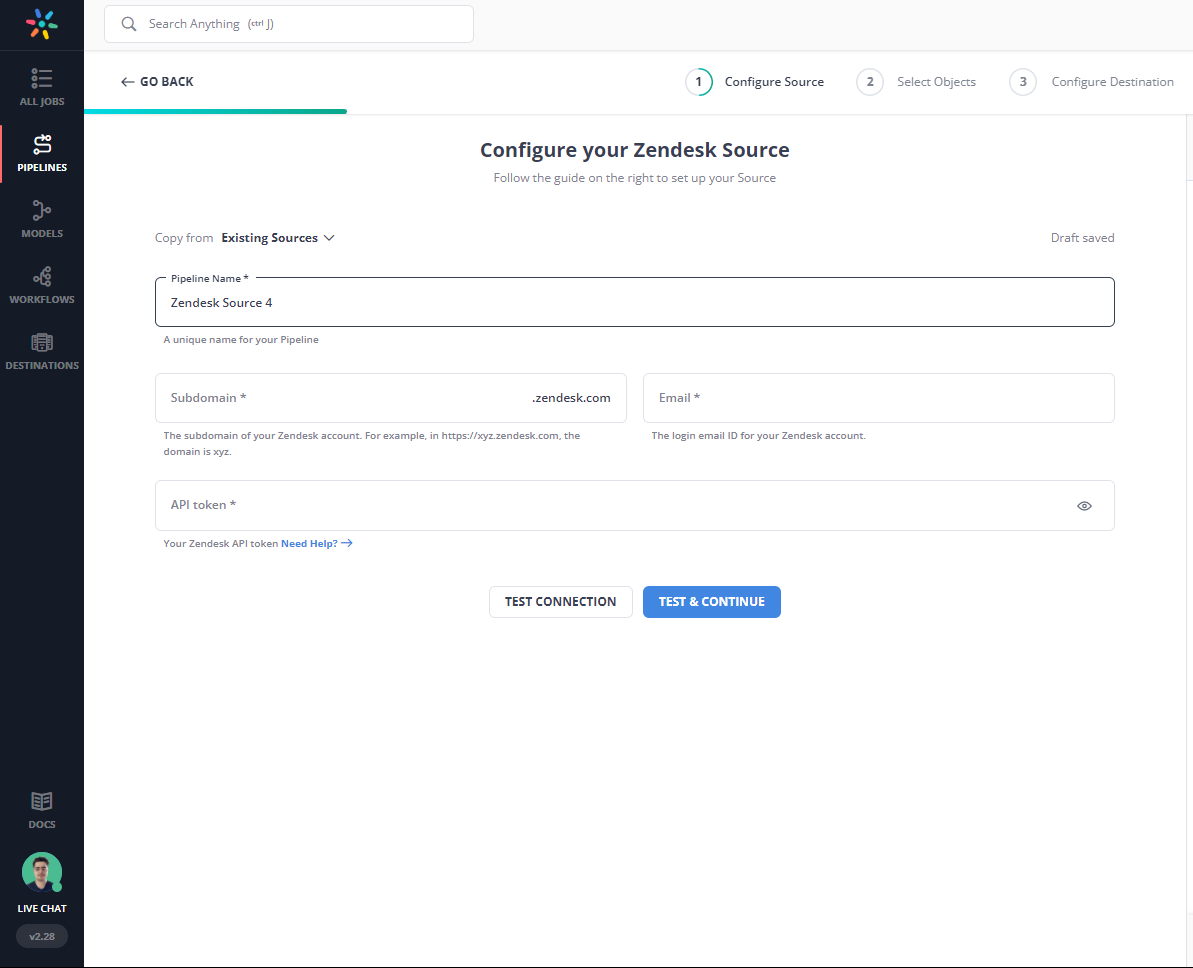
Note: You need to login to Zendesk Admin Center to generate a new API token.
Step 2: Configure Databricks as your Destination
Now, you need to configure Databricks as the destination.

All Done to Setup Your ETL Pipeline
After implementing the 2 simple steps, Hevo will take care of building the pipeline for replicating data from Zendesk to Databricks based on the inputs given by you while configuring the source and the destination.
Hevo will replicate data for all the Support and Voice objects in your Zendesk account using the Incremental Export API.
The pipeline will automatically replicate new and updated data from Google Analytics to Databricks every 5 mins (by default). However, you can also adjust the data replication frequency as per your requirements.
Data Pipeline Frequency
| Default Pipeline Frequency | Minimum Pipeline Frequency | Maximum Pipeline Frequency | Custom Frequency Range (Hrs) |
| 5 Mins | 5 Mins | 3 Hrs | 1-3 |
For in-depth knowledge of how a pipeline is built & managed in Hevo, you can also visit the official documentation for Zendesk as a source and Databricks as a destination.
You don’t need to worry about security and data loss. Hevo’s fault-tolerant architecture will stand as a solution to numerous problems. It will enrich your data and transform it into an analysis-ready form without having to write a single line of code.

What Can You Achieve by Migrating Your Data from Zendesk to Databricks?
Here’s a little something for the data analyst on your team. We’ve mentioned a few core insights you could get by replicating data from Zendesk to Databricks. Does your use case make the list?
- What percentage of customers’ queries from a region are through email?
- How does customer SCR (Sales Close Ratio) vary by Marketing campaign?
- How does the number of calls to the user affect the activity duration with a Product?
- How does Agent performance vary by Product Issue Severity?
You can also read more about:
Summing It Up
Exporting & uploading CSV files is the go-to solution for you when your data analysts require fresh data from Zendesk only once in a while. But with an increase in frequency, redundancy will also increase. To channel your time into productive tasks, you can opt-in for an automated solution that will help accommodate regular data replication needs. This would be genuinely helpful to support & product teams as they would need regular updates about customer queries, experiences, and satisfaction levels with the product.
And here, we’re ready to help you with this journey of building an automated no-code data pipeline with Hevo. Hevo’s 150+ plug-and-play native integrations will help you replicate data smoothly from multiple tools to a destination of your choice. Its intuitive UI will help you smoothly navigate through its interface. And with its pre-load transformation capabilities, you don’t even need to worry about manually finding errors and cleaning & standardizing them. Connect with us today to improve your data management experience and achieve more with your data.
FAQs
1. How to connect database with Databricks?
You can connect Databricks to a database using JDBC or ODBC drivers. Set up the connection in a notebook or via cluster configuration using the appropriate connection strings and credentials.
2. How do I upload a CSV file to Databricks workspace?
In the Databricks workspace, navigate to the “Data” tab, select “Add Data,” and upload your CSV file. You can also use code to load CSV files directly.
3. How do I connect to Databricks workspace?
You can connect to Databricks Workspace using a web browser, Databricks CLI, or Databricks APIs.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



