




Apache Kafka is a distributed Publish-Subscribe Messaging platform explicitly designed to handle Real-time Streaming data. It helps in Distributed Streaming, Pipelining, and replay of data feeds for quick, scalable workflows. In today’s disruptive tech era, raw data needs to be processed, reprocessed, evaluated and managed in real-time.
Apache Kafka has proved itself as a great asset when it comes to performing message streaming operations. The main architectural ideas of Kafka were created in response to the rising demand for Scalable high-throughput infrastructures that can store, analyze, and reprocess streaming data.
In this article, you will learn about GCP Kafka. You will also gain a holistic understanding of Apache Kafka, Google Cloud Platform, their key features, the need for installing GCP Kafka, and the steps for installing GCP Kafka. Read along to find out more about GCP Kafka.
Table of Contents
What is Apache Kafka?

Apache Kafka was originally developed at LinkedIn to address the need to monitor activity stream data and operational metrics such as CPU, I/O usage, and request timings. Subsequently, in early 2011, it was Open-Sourced through the Apache Software Foundation. Apache Kafka is a Distributed Event Streaming Platform written in Java and Scala. It is a Publish-Subscribe (pub-sub) Messaging Solution used to create Real-Time Streaming Data Pipelines and applications that adapt to the Data Streams.
Kafka deals with Real-Time volumes of data and swiftly routes it to various consumers. It provides seamless integration between the information of producers and consumers without obstructing the producers and without revealing the identities of consumers to the producers. Read about Kafka Cluster Architecture to get a detailed idea.
Key Features of Apache Kafka
Apache Kafka provides the following features such as communicating through messaging and stream processing to enable real-time data storage and analysis.
- Persistent messaging: Any type of information loss cannot be tolerated in order to gain real value from big data. Apache Kafka is built with O(1) Disc Structures that deliver constant-time performance even with very high volumes of stored messages (in the TBs).
- High Throughput: Kafka was designed to work with large amounts of data and support Millions of Messages per Second.
- Distributed event streaming platform: Apache Kafka facilitates message partitioning across Kafka servers and distribution of consumption over a cluster of consumer systems while ensuring per-partition ordering semantics.
- Real-time solutions: Messages created by producer threads should be instantly available to consumer threads. This characteristic is essential in event-based systems like Complex Event Processing (CEP).
Hevo Data is a No-code Data Pipeline that offers a fully managed solution to set up Data Integration for 150+ Data Sources (including 60+ Free sources) and will let you directly load data from sources like Apache Kafka to a Data Warehouse or the Destination of your choice. Let’s look at some of the salient features of Hevo:
- Risk management and security framework for cloud-based systems with SOC2 Compliance.
- Always up-to-date data with real-time data sync.
- Transform your data with custom Python scripts or using the drag-and-drop feature.
Don’t just take our word for it—try Hevo and experience why industry leaders like Whatfix say,” We’re extremely happy to have Hevo on our side.”
Get Started with Hevo for FreeWhat is Google Cloud Platform?

Google Cloud Platform (GCP) provides computing resources necessary for developing and deploying applications on the web. By creating an application using the platform, Google automatically keeps track of all its resources, including Storage, Processing Power, and Network Connectivity. Instead of leasing a server or a DNS address, as is the case with normal websites with GCP, you pay for the resources used by your application.
Key Features of Google Cloud Platform
Some of the key features of Google Cloud Platform are as follows:
- Big Data: GCP offers a dedicated Big Data solution for clients with such needs. Some of the features include BigQuery, which allows users to run SQL-like commands on large chunks of data.
- Hosting: GCP offers two hosting solutions for customers: the AppEngine, the Platform-as-a-Service, and Compute Engine that acts as Infrastructure-as-a-Service.
- Containers: These come in handy for PaaS applications since they help boost app deployment.
Installation of GCP Kafka
It is assumed that you already have access to Google Cloud Account.
You can follow these steps to install a single node GCP Kafka VM.
- Step 1: Log in to your GCP account.
- Step 2: Go to the “GCP products and services” menu, i.e., the hamburger icon at the top left corner is present at the top left corner of the window.
- Step 3: Click on the “Cloud Launcher” option.
- Step 4: In the search bar that appears, search for Kafka.
- Step 5: Select the Kafka VM Image.

- Step 6: Click the “Launch on Compute Engine” button.
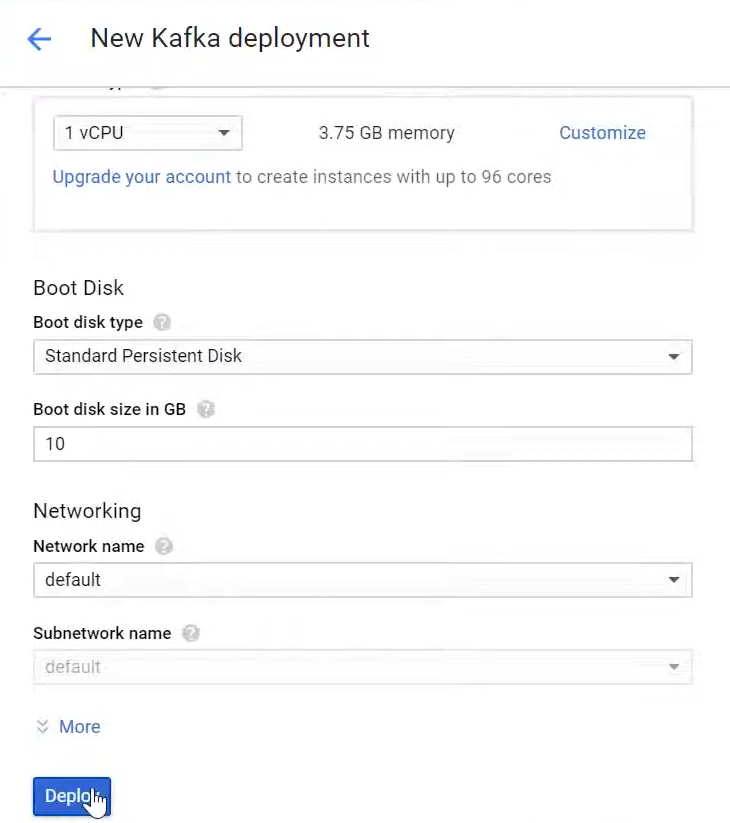
- Step 7: In the next window, you can review and change some settings, but the default settings are adequate.
- Step 8: Scroll down to the bottom of the page and click the “Deploy” button.
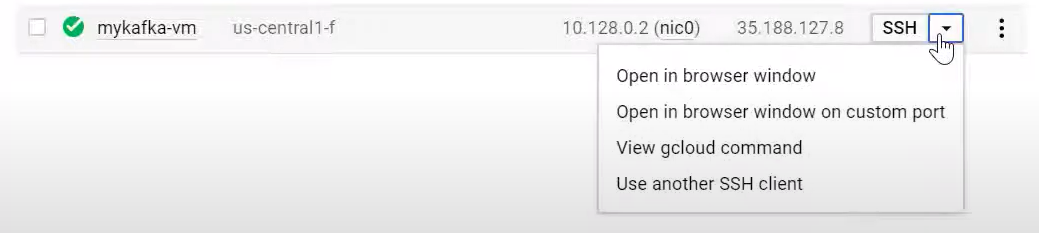
- Step 9: From your deployment page, you can SSH to the GCP Kafka VM, or you can go to your homepage by clicking on the hamburger icon in the top left corner, then to the compute engine page, and SSH to your GCP Kafka VM.



What is the need to Install GCP Kafka?
- Despite its many benefits, Apache Kafka is a difficult technology to implement. In production, on-premises Kafka clusters are difficult to set up, scale, and manage.
- You must provision machines and configure Kafka when establishing an on-premises infrastructure to run Kafka.
- You must also design the distributed machine cluster to ensure availability, ensure data storage and security, set up monitoring, and carefully scale data to accommodate load changes.
- The infrastructure must then be maintained by replacing machines as they fail and performing routine patching and upgrading.
- The Kafka infrastructure is provisioned, built, and maintained by a third-party vendor such as Google.
- You are in charge of developing and running the applications. This makes it simple to deploy Kafka without the need for specialized Kafka infrastructure management knowledge.
- You devote less time to infrastructure management and more time to creating value for your company. As a result, GCP can be used as a third-party vendor, leading to GCP Kafka Installation.
Conclusion
In this article, you have learned about GCP Kafka Installation. This article also provided detailed information on Apache Kafka and Google Cloud Platform, their key features, the need for installing GCP Kafka, and the steps for installing GCP Kafka. Visit Kafka Debezium Event Sourcing, Azure Kafka Integration, and Apache Kafka Queue for more information.Hevo Data with its strong integration with 150+ data sources (including 40+ Free Sources) such as Apache Kafka allows you to not only export data from your desired data sources & load it to the destination of your choice but also transform & enrich your data to make it analysis-ready.
Want to give Hevo a try? Sign Up for a 14-day free trial and experience the feature-rich Hevo suite first hand. You may also have a look at the amazing price, which will assist you in selecting the best plan for your requirements.
Share your experience of understanding GCP Kafka Installation in the comment section below!
FAQs
1. What is the difference between Apache Kafka and ETL?
Apache Kafka is a real-time streaming platform that supports high-throughput data pipelines. ETL, though, stands for extracting, transforming, and loading, and it is mostly associated with batch jobs. Kafka can be a part of the ETL pipeline but is not an ETL tool.
2. What is the disadvantage of Kafka?
A disadvantage of Kafka is its complexity in setup and configuration, which can make initial deployment and integration with existing systems challenging. Additionally, while Kafka excels in real-time data streaming, it lacks built-in support for advanced data transformation, requiring additional tools for complex processing tasks.
3. What type of database is GCP?
Google Cloud Platform (GCP) offers various types of databases, including relational databases like Cloud SQL and BigQuery, a data warehouse, as well as NoSQL options such as Firestore, Cloud Bigtable, and Cloud Datastore.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



