As businesses continue to generate massive amounts of data, finding a scalable and cost-efficient way to store, manage, and analyze it is essential. Enter AWS Redshift, Amazon’s fully managed cloud data warehouse designed to easily handle petabytes of data. Whether you want to improve your data analytics capabilities, reduce operational overhead, or simply streamline your data storage, Redshift offers a robust, flexible solution tailored to modern business needs. In this guide, we’ll walk you through everything from the architecture and setup of Redshift clusters to pricing models and best practices for optimizing performance. Let’s dive in and unlock the full potential of your data with AWS Redshift!
Table of Contents
What Is Amazon Redshift Data Warehouse?
AWS Redshift is a fully managed cloud data warehouse service from AWS, designed to store and analyze large amounts of data efficiently. It uses massively parallel processing (MPP) to quickly execute complex queries across petabytes of data, making it ideal for big data analytics. Redshift offers seamless integration with other AWS services like S3, Glue, and EC2, enabling streamlined data management and ETL processes. With flexible pricing models and scalable architecture, businesses can optimize costs and performance based on their data needs.
Key Features of Amazon Redshift
- Fully Managed: It is a fully managed cloud data warehouse service, handling infrastructure setup, maintenance, and scaling automatically. This allows businesses to focus on data analytics and decision-making rather than managing the underlying architecture.
- Scalable and Petabyte-Scale: It supports petabyte-scale datasets, accommodating data volumes ranging from gigabytes to petabytes. It scales easily to meet the growing data demands of businesses, ensuring fast and reliable data processing.
- Cost-Effective: With flexible pricing models, including a “pay-as-you-go” structure, Redshift offers businesses cost optimization. Companies pay only for the storage and compute resources they use, ensuring an efficient and budget-friendly data warehousing solution.
- Optimized for OLAP: Designed for Online Analytical Processing (OLAP), Redshift enables quick and efficient query execution, making it ideal for analytics workloads that require complex queries and large data sets.
- Seamless AWS Integration: Redshift integrates smoothly with other AWS services like S3, Glue, EC2, and AWS Data Exchange, simplifying data management, ETL processes, and enhancing collaboration across platforms.
- Supports SQL: Redshift is SQL-compatible, based on PostgreSQL, and integrates well with various BI tools, making it familiar to users and simplifying data querying and reporting.
- Serverless and Data Sharing: Redshift offers serverless options, allowing users to run queries and analyze data without managing infrastructure. Additionally, it provides secure data sharing, enabling collaboration with external datasets and stakeholders.
- Advanced Features: Redshift includes built-in features like automatic data compression, encryption for enhanced security, and high availability, ensuring your data is protected, optimized, and accessible when needed.

Are you having trouble migrating your data into Redshift? With our no-code platform and competitive pricing, Hevo makes the process seamless and cost-effective.
- Easy Integration: Connect and migrate data into Redshift without any coding.
- Auto-Schema Mapping: Automatically map schemas to ensure smooth data transfer.
- In-Built Transformations: Transform your data on the fly with Hevo’s powerful transformation capabilities.
- 150+ Data Sources: Access data from over 150 sources, including 60+ free sources.
You can see it for yourselves by looking at our 2000+ happy customers, such as Airmeet, Cure.Fit, and Pelago.
Get Started with Hevo for FreeComparing Amazon Redshift to Traditional Data Warehouses
Traditional data warehouses become inefficient as the data keeps growing, and it is inevitable. It requires regular hardware updates, maintenance, separate staff to handle its software updates. In case of any minor failure, these on-premise data warehouses can remain shut down for long hours, making most business workflow stop. Redshift is a perfect alternative to tackle all the imperfections of traditional data warehouses. Unlike on-premise data warehouse solutions, Redshift data warehouse offers greater flexibility to users at a low cost than the former one.
Companies don’t need to own hardware or manage any software updates in Redshift. Also, one can scale up or down the computation power according to the needs. Many factors show why it is a better choice than a traditional data warehouse.
Amazon Redshift Architecture
This section highlights the components of Redshift’s architecture, thereby giving you enough pointers to decide if this is favorable for your use case. The Redshift architecture diagram is as below:
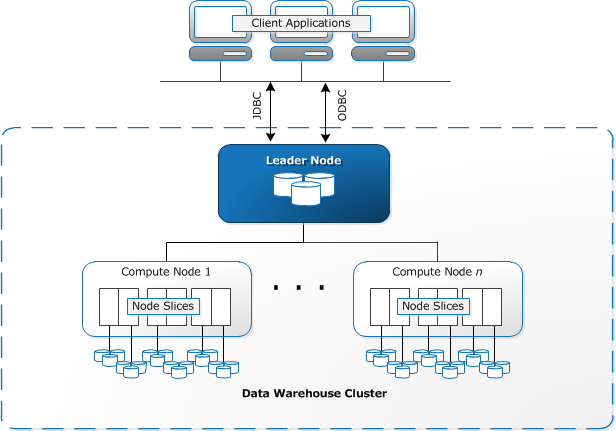
- Redshift Cluster: Redshift uses a cluster of nodes as its core infrastructure component. A cluster usually has one leader node and a number of compute nodes. In cases where there is only one compute node, there is no additional leader node.
- Compute Nodes: Each compute node has its own CPU, memory, and storage disk. Client applications are oblivious to the existence of compute nodes and never have to deal directly with compute nodes.
- Leader Node: The leader node is responsible for all communications with client applications. The leader node also manages the coordination of compute nodes. Query parsing and execution plan development is also the responsibility of the leader node. On receiving a query the leader node creates the execution plan and assigns the compiled code to compute nodes. A portion of the data is assigned to each compute node. The final aggregation of the results is performed by the leader node.
Redshift allows the users to select from two types of nodes – dense storage nodes and dense compute nodes. Customers can select them based on the nature of their requirements – whether it is storage heavy or compute-heavy. Redshift’s cluster can be upgraded by increasing the number of nodes or upgrading individual node capacity or both.
Internally the compute nodes are partitioned into slices with each slice having a portion of CPU and memory allocated to it. The node slices will work in parallel to complete the work that is allocated by the leader node.
Here you can read more on Redshift architecture.
Now that we have an idea about how Redshift architecture works, let’s see how this architecture translates to performance.
Amazon Redshift Performance
- Redshift’s architecture supports massively parallel processing (MPP), enabling it to execute complex queries quickly.
- A large portion of query execution time is spent on creating execution plans and optimizing queries.
- Subsequent query executions are often faster due to pre-optimized execution plans.
- Performance can be further improved by using proper distribution keys and sort styles.
- Redshift allows parallel data loading from flat files across multiple nodes, reducing load times.
- It can run the TPC-DS benchmark on a 3TB dataset in just 25 minutes using a 4-node cluster.
Amazon Redshift ETL and Data Transfer

A significant part of jobs running in an ETL platform will be the load jobs and transfer jobs. Data load to Redshift is performed using the COPY command of Redshift. For executing a copy command, the data needs to be in EC2. If there is already existing data in Redshift, using this command can be problematic since it results in duplicate rows. In such cases, a temporary table may need to be used. The best method to overcome such complexity is to use a proven data integration platform like Hevo, which can abstract most of these details and allow you to focus on the real business logic.
Additionally, Amazon offers two services that can make things easier for running an ETL platform on AWS. AWS Glue and AWS Data Pipeline. AWS Glue can generate Python or Scala code to run transformations considering the metadata that is residing in the Glue data catalog.
AWS data pipeline, on the other hand, helps schedule various jobs including data transfer using different AWS services as source and target.
Both the above services support Redshift, but there is a caveat. These services are tailor-made for AWS services and do not really do a great job in integrating with non-AWS services. So if part of your data resides in on-premise setup or a non-AWS location, you can not use the ETL tools by AWS.
In those cases, it is better to use a reliable ETL tool like Hevo which has the ability to integrate with multitudes of databases, managed services, and cloud applications. Hevo will help you move your data through simple configurations and supports all the widely used data warehouses and managed services out of the box.
Redshift uses Postgres as its query standard with its own set of data types. Since the data types are Redshift proprietary ones, there needs to be a strategy to map the source data types to Redshift data types. It can manage this automatically using its own logic but can surprise the user with unexpected results if the mapping logic is not carefully considered during the data transfers.
Modern ETL systems these days also have to handle near real-time data loads. Even though Redshift is a data warehouse and designed for batch loads, combined with a good ETL tool like Hevo, it can also be used for near real-time data loads.
Amazon Redshift Scalability
One of the most critical factors which makes a completely managed data warehouse service valuable is its ability to scale. Redshift can scale quickly and customers can choose the extent of capability according to their peak workload times.
It supports two types of scaling operations:
- Classic Resizing: First is the classic resizing which allows customers to add nodes in a matter of a few hours. Classic resizing is available for all types of nodes.
- Elastic Resizing: Elastic resizing makes even faster-scaling operations possible but is available only in case of nodes except the DC1 type of nodes. That said, there is a short window of time during even the elastic resize operation where the database will be unavailable for querying.
Redshift also allows you to spin up a cluster by quickly restoring data from a snapshot. This is very helpful when customers need to add compute resources to support high concurrency.
Amazon Redshift Pricing
Redshift prices are including compute and storage pricing. Cost is calculated based on the hours of usage. With the ability to quickly restore data warehouses from EC2 snapshots, it is possible to spin up clusters only when required allowing the users to closely manage their budgets.
Redshift offers two types of nodes – dense compute and dense storage nodes. These nodes can be selected based on the nature of data and the queries that are going to be executed. dense compute nodes starts from .25$ per hour and comes with 16TB of SSD. Dense storage nodes have 2 TB HDD and start at .85 $ per hour. It is to be noted that even though dense storage comes with higher storage, they are HDDs and hence the speed of I/O operations will be compromised.
Details on Redshift pricing will not be complete without mentioning Amazon’s reserved instance pricing which is applicable for almost all of AWS services. By committing to using Redshift for a period of 1 year to 3 years, customers can save up to 75% of the cost they would be incurring in case they were to use the on-demand pricing policy.
Amazon Redshift Maintenance
As mentioned in the beginning, Redshift is a completely managed service and as such does not require any kind of maintenance activity from the end-users except for small periodic activity.
Redshift internally uses delete markers instead of actual deletions during the update and delete queries. This means there is to be a housekeeping activity for archiving these rows and performing actual deletions. For Redshift, this process is called vacuuming and can only be executed by a cluster administrator. Read more on Redshift vacuum.
Amazon Redshift Data Security
Redshift provides complete security to the data stored throughout its lifecycle – irrespective of whether the data is at rest or in transit. The security is tested regularly by third-party auditors. It also enables complete security in all the auxiliary activities involved in Redshift usage including cluster management, cluster connectivity, database management, and credential management.
By default, all network communication is SSL-enabled. It is possible to encrypt all the data. You can also start your cluster in a virtual private cloud for enterprise-level security.
It also complies with all the well-known data protection and security compliance programs like SOC, PCI, HIPAA BAA, etc.
Redshift Security Best Practices
Amazon takes care of the security of the cloud and the organization takes care of the security in the cloud. It basically follows a shared responsibility security model.
- Security of the Cloud: Amazon protects the infrastructure where AWS runs its services in the cloud. Amazon makes sure that AWS features and services can be used securely by the users. AWS Compliance ensures that security levels are regularly tested and verified.
- Security in the Cloud: The organizations using Redshift are responsible for security related to the AWS service they use. Organizations also take care of other factors like data sensitivity, security compliance with laws and regulations.
On top of that, you are always secured with identity and access management (IAM), data encryption, and virtual private cloud (VPC).
Amazon Redshift Pros and Cons
| Pros | Cons |
| Fully managed service with minimal intervention required by users. | Requires manual vacuuming for data cleanup. |
| Scales up to petabytes of data, with minimal effort required for scaling. | Pricing includes both computing and storage; they cannot be separated like in Snowflake. |
| Excellent performance, especially for executing repeated complex queries. | Complex data transfer when integrating with non-AWS services. |
| Flexible on-demand pricing and ability to restore clusters from snapshots to control costs. | Not designed for real-time operations, more suited for batch processing. |
| Provides strong security features with minimal user input required. | Scaling isn’t seamless and may result in short downtime during cluster resizing. |
| Continuous improvements, with performance enhancements in every update. | Downtime during scaling can range from minutes (elastic scaling) to hours (older node types). |
| Integrates seamlessly with other AWS services like AWS Glue and Data Pipeline. |
How to Set Up Amazon Redshift?
Before getting started:
- You’ll need an AWS Account.
- You need to have an Open Firewall Port for Redshift to use. Redshift uses port number 5439 by default.
- You’ll further need permissions to access other AWS services like Amazon S3, from your Redshift Cluster. You can do so by creating a dedicated IAM Role attached to the Redshift Cluster.
Launching a Redshift Cluster
You’re now all set to launch a Redshift Cluster.
- Step 1: Open the Redshift console and select the region in which you want your cluster.
- Step 2: Choose Quick Launch Cluster and enter the details as shown below.

- Step 3: Click on the “Launch Cluster” button to launch the cluster. You can check the Cluster Status under the list of clusters.
- Step 4: You can further modify the launched cluster by clicking the “Modify Cluster” button.
- Step 5: The Redshift cluster is now launched. Now, you will need to configure a security group to authorize access to the Redshift Cluster.
Connecting to the Redshift Cluster
You can now connect to your Redshift Cluster to run queries. To do this, you can:
- Use the AWS Query Editor to connect to the Redshift Cluster from the AWS Management Console.
- Use a SQL Client Tool of your choice (like SQL Workbench/J) to connect to your Redshift Cluster.


Amazon Redshift Alternatives
Redshift is not the only cloud data warehouse service available in the market. A list of the most popular cloud data warehouse services which directly competes with Redshift can be found below.
- Azure SQL data warehouse – Microsoft’s own cloud data warehouse service provides a completely managed service with the ability to analyze petabytes of data. Even though this is considered slower in case of complex queries, it makes complete sense for a customer already using the Microsoft stack.
- Google Big Query – Big Query offers a cheap alternative to Redshift with better pricing. Generally benchmarked as slower than Redshift, BigQuery is considered far more usable and easier to learn because of Google’s emphasis on usability. You can read a comparison – Redshift vs BigQuery here.
- Oracle Autonomous data warehouse – Oracle claims ADW to be faster than Redshift, but at the moment standard benchmark tests are not available. Oracle allows customers to use their on-premise Oracle licenses to decrease the costs. For customers already spending money on Oracle infrastructure, this is a big benefit.
- Snowflake – Snowflake offers a unique pricing model with separate compute and storage pricing. The performance is comparable to Redshift or even higher in specific cases. For customers with light workloads, Snowflake’s pure on-demand pricing only for compute can turn out cheaper than Redshift. You can read a comparison – Snowflake Vs Redshift here.
| Feature | AWS Redshift | Azure SQL | Google BigQuery | Oracle | Snowflake |
| Provider | Amazon Web Services (AWS) | Microsoft Azure | Google Cloud | Oracle Cloud | Independent (Runs on AWS, Azure, and GCP) |
| Performance | Fast, especially for complex queries | Slower on complex queries | Slower than Redshift | Claimed to be faster (no standard benchmarks) | Comparable to Redshift, faster in some cases |
| Query Optimization | Massively Parallel Processing (MPP) | MPP, slower for complex queries | Auto-scaling, but slower | Oracle optimizes for performance | Performance scales with separated compute/storage |
| Pricing Model | On-demand pricing (compute + storage) | On-demand pricing | Cheaper than Redshift, with better pricing | Leverages on-premise licenses for cost savings | On-demand pricing (compute & storage separately) |
| Usability | Intermediate to advanced, tight AWS integration | Suited for customers in Microsoft ecosystem | Very easy to learn, Google’s focus on usability | Easier for Oracle customers | Intuitive, popular for data analytics |
| Integration | Deep integration with AWS services like Glue | Best for users already in Microsoft stack | Integrated with Google Cloud services | Supports existing Oracle infrastructure | Works on AWS, Azure, GCP |
| Real-time Processing | Suited for batch, not real-time | Suited for batch processing | Supports real-time analytics | Better for real-time workloads than Redshift | Can handle real-time processing |
| Unique Selling Point (USP) | Great performance with AWS integration | Seamless Microsoft integration | Usability and pricing | Leverages Oracle infrastructure, cost efficiency | Separate compute/storage pricing, cost-efficient |
Learn more about Redshift Architecture and its Components
When to Use Amazon Redshift?
Redshift advertises itself as a know it all data warehouse service, but it comes with its own set of quirks. But, there are some specific scenarios where using Redshift may be better than some of its counterparts.
- Your ETL design involves many Amazon services and plans to use many more Amazon services in the future. Redshift with its tight integration to other Amazon services is the clear winner here.
- Your cluster will be always running near-maximum capacity and query workloads are spread across time with very little idle time. This particular use case voids the pricing advantage of most competitors in the market.
- You are completely confident in your product and anticipate a cluster running at full capacity for at least a year. This allows you to use AWS Reserved pricing and can help cut costs to a big extent.
- The data design is completely structured with no requirement or future plans for storing semi-structured on unstructured data in the warehouse.
- Complete security and compliance are needed from the very start itself and there is no scope to skip on security and save costs.
Conclusion
Amazon Redshift offers a strong value proposition as a data warehouse service and delivers on all counts. Amazon continuously updates it and performance improvements are clearly visible with each iteration. Tight integration with AWS Services makes it the defacto choice for someone already deep into AWS Stack.
Most of the limitations addressed on the data loading front can be overcome using a data pipeline platform like Hevo Data in combination with Redshift, creating a very reliable, always available data warehouse service.
Sign up for a 14-day free trial and streamline your data workflows effortlessly!
FAQ on AWS Redshift
1. What is AWS Redshift used for?
Redshift is used for large-scale data warehousing, enabling fast querying and analysis of structured and semi-structured data. It supports analytics and business intelligence, especially for complex queries over large datasets.
2. Is AWS Redshift an ETL tool?
No, Redshift is not an ETL tool; it is a data warehouse. However, it can be used in conjunction with ETL tools like AWS Glue, Talend, or Matillion to load and transform data for analysis.
3. Is Redshift SQL or NoSQL?
Redshift is a SQL-based data warehouse. It uses SQL queries for data retrieval and supports structured and semi-structured data.
4. What is the difference between S3 and Redshift?
Amazon S3 is an object storage service designed for large-scale, unstructured data storage, while Redshift is a data warehouse optimized for complex querying and analysis of structured data. S3 is used for data storage, while Redshift is used for data analysis.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link