

 Key Takeaway
Key TakeawayConnecting MongoDB to SQL Server for replicating data can be done in any of the following ways:
Method #1: Using Hevo Data
Hevo Data is an ELT platform offering end-to-end, no-code data transfer. This is the easiest and fastest way to transfer data for businesses looking for a no-code and efficient method.
Method #2: Using Custom Scripts
Here you need to write code to extract data, transform the data, and load it into SQL Server. This is complex, as you need to build your code for the replication. However, if you need full control over the transfer, this is the best option.
Method #3: Using SQL Server Integration Services (SSIS)
Using this method, you have more flexibility to transfer data using the SSIS platform than using a no-code tool like Hevo. If you need flexibility and don’t mind writing some code and setting up SSIS, this option is worth the effort.
Moving MongoDB data to a destination like SQL Server can be challenging because MongoDB is a non-relational database. Converting data from MongoDB to SQL Server involves exporting and importing data from MongoDB into SQL Server tables. Any such data movement must first define a target relational data model in SQL Server, then develop a transformation that can take the data in MongoDB and transform it into the target data model.
This blog will discuss the basics of MongoDB SQL Server integration and three ways to migrate data. All the methods have been presented in a detailed form with relevant examples so that you can evaluate the three and select the best-suited method for your organization’s needs.
Table of Contents
What Are the Methods To Perform MongoDB MS SQL Server Integration?
You may employ custom scripts or ETL (Extract, Transform, Load) processes to efficiently export MongoDB data into SQL Server. Here are the different methods to connect the two databases:
Method #1: Use Hevo Data to Ingest Data from MongoDB to SQL Server
Step #1: Configure MongoDB as your Source Connector
Before you start the process, ensure you meet the following prerequisites:
- MongoDB version is between 3.4 and 8.0
- The replication is set up for MongoDB OpLog and Change Streams.
- Give Hevo permission to read the Generic MongoDB databases.
- Whitelist the IP addresses of Hevo.
- You have either the Team Administrator, the Team Collaborator, or the Pipeline Administrator role in Hevo to create the Pipeline.
Once you have met these pre-requisites, perform the following steps.
Step #1.1: Set up MongoDB Replication for OpLog and Change Streams
1. Modify the MongoDB server configuration
MongoDB configuration file, mongod.conf, is generally found in /etc/ directory in a Linux system.
The options to configure are as follows:
- replication.replSetName: This is the replica set that MongoDB is part of.
- replication.oplogSizeMB: The maximum size of the log that MongoDB will retain.
- net.bindIp: The IP this MongoDB server should listen to.
2: Configure replication through the MongoDB shell
Open the Mongo shell on the replication server and run the following commands:
- rs.initiate(): To initialize the replica set.
- rs.conf(): To show the replication configuration already set
- rs.status(): To show the replication status.
Step #1.2: Set up Permissions to Read Generic MongoDB Databases
After setting up replication for OpLog and Change Streams, you need to assign read privilege to the database user now to read from the local database and the databases to be replicated.
To do this:
- Open the MongoDB shell.
- Connect to your replica set or sharded cluster as an admin user.
- Run the following commands to create a user and assign it permissions:
<em>use admindb.createUser({user: "<username>",pwd: "<password>",roles: [ "readAnyDatabase", {role: "read", db: "local"} ]})</em>Step #1.3: Whitelist Hevo’s IP Addresses
Add the IP addresses to the list of authenticated IP Addresses/CIDR of your MongoDB instance
Step #1.4: Configure Generic MongoDB Connection Settings
Configure Generic MongoDB as a Source in Hevo by following the steps below:
- Go to the Navigation Bar and click PIPELINES
- From the Pipelines List View, click + CREATE PIPELINE
- Choose MongoDB on the Select Source Type page
- On the Configure your MongoDB Source page, specify the following:

- Pipeline Name: A unique name for the Pipeline under 255 characters.
- General Connection Settings:
- Paste Connection String:
- Connection URI: This is the unique identifier for connecting to a MongoDB replica set or a sharded cluster.
- Enter Connection Fields Manually:
- Database Host: IP address or hostname of the database you want to access.
- Database User: The user with permission to read collections in your database.
- Database Password: The password for the database user.
- Database Port: The port on which your MongoDB server listens for connections. Default value: 27017.
- Paste Connection String:
- Authentication Database Name: The database that stores the user’s information. Default: admin.
- Connect through SSH: This lets you connect to Hevo using an SSH tunnel, instead of connecting your MongoDB database host to Hevo.
- Use SSL: Update this if you have SSL enabled at the MongoDB server.
- Select an Ingestion Mode: The desired mode by which you want to ingest data from the Source.

- OpLog: Data is ingested using MongoDB’s OpLog.
- Change Streams: MongoDB’s Change Streams enable apps to stream real-time data changes without the complexity and risk of tailing the OpLog.
- Click TEST CONNECTION.
- Click TEST & CONTINUE to proceed to set up the Destination.
Step #2: Configure your SQL Server Connection Settings
Perform the following steps to configure SQL Server as a Destination in Hevo:
- Click DESTINATIONS in the Navigation Bar.
- Click + CREATE DESTINATION in the Destinations List View.
- On the Add Destination page, select SQL Server.
- On the Configure your SQL Server Destination page, specify:

- Destination Name: A unique name for your Destination, under 255 characters.
- Database Host: This is the IP address or DNS of your SQL Server instance.
- Database Port: This is the port on which your SQL Server listens for connections. Default value: 1433
- Database User: A login user with a non-administrative role in the SQL Server database.
- Database Password: This is the password for the login user.
- Database Name: This is the name of the Destination database to which the data is loaded.
- Schema Name (Optional): The name of the Destination database schema. Default value: dbo
Click SAVE & CONTINUE. This button is enabled once all the mandatory fields are specified.vo documentation to configure MongoDB as your source and SQL Server as your Destination.
Click TEST CONNECTION. This button is enabled once all the mandatory fields are specified.

Method 2: Manually Building ETL Scripts
Follow the steps below to move data manually:
Step 1: Extract your Data from MongoDB
- Use the
<a href="https://hevodata.com/learn/mongodump/">mongodump</a>A command to create a copy/backup of your MongoDB data to a specified directory. Themongodumpcommand can take the following syntax:
mongodump -- dbpath/data/db/ -- out/data/backup/- Use the
bsondumpcommand to convert the dump files from BSON to JSON format to prepare the file for a direct load into SQL Server.
You can also use a converter tool, which users can transform MongoDB collections into equivalent SQL tables, preserving the structure and integrity of the data.
Do you want to export data into JSON format? Find more information on MongoDB to JSON export here.
Step 2.2: Transform the Data
You have to be very careful to ensure that the data types in MongoDB are accurately transformed into their respective MS SQL Server equivalent. This is especially important as MongoDB is non-relational and may pose a challenge to developers unfamiliar with non-traditional databases.
You may also have to flatten out or un-nest your MongoDB data, as there is a high probability that some of the data will be nested
Step 2.3: Load your Data
You can use the OPENJSON function to parse the JSON into a SQL Server table with the JSON properties as columns.
Example code:
SELECT book.*
FROM OPENROWSET (BULK 'C:JSONBooksooks.json', SINGLE_CLOB) as j
CROSS APPLY OPENJSON(BulkColumn)
WITH( id nvarchar(100), name nvarchar(100), price float,
pages_i int, author nvarchar(100)) AS bookThis will return a result of a table with Id, Name, price, pages_i, and Author as columns.
Limitations of Manually Building ETL Scripts
- Time-Consuming: You must write a lot of code to complete this process. This may not be particularly favorable for fast-paced organizations meeting tight deadlines.
- Real-time Data Load Limitations: The above method would work best if you want to load data occasionally. To stream data in real-time, you must perform the above steps repetitively by setting up a cron job. This would need additional code to be written.
- Resource Intensive: This method requires a lot of engineering bandwidth and may not be particularly well-suited to small organizations that may not have expert data developers
- Difficulty with Data Transformations: Data transformations must be performed manually, which is tedious. Furthermore, there is no way to perform quick data transformations like time and data changes, currency conversions, etc.
Method 3: Using SSIS
There are three ways to import data using SSIS. These are as follows:
1) Using Third-party Connectors
Various commercial source components are available from providers such as CDATA and ZappySYS.
2) Using a Script Component
Users without coding experience may not prefer this solution since it involves a lot of coding for creating a script.
3) Using the ODBC Connection
There are several processes to be followed to create a MongoDB ODBC data source and then connect the databases:
A) Install Microsoft Visual C++ 2015 Redistributable
First, you must install the Microsoft Visual C++ 2015 redistributable since it is a prerequisite for the MongoDB BI Connector.
B) Install MongoDB BI Connector
Next, download and install the MongoDB ODBC BI Connector for Windows to import data using SSIS.
Connecting to MongoDB via ODBC is not established on the database engine service. It requires a service called MongoSQL which is installed within the BI connector.
C) Install the MongoDB ODBC Driver
The third step in importing data using SSIS is to install the MongoDB BI connector ODBC Driver.
Because you are using SSIS and Visual Studio only reads connections for the 32-bit platform, you must also install the 32-bit drivers if you are using a 64-bit installation.
D) Generating DRDL Schema File
Because MongoDB is a NoSQL database, you must first define a relational schema file that allows the ODBC driver to read document data relationally and import data using SSIS.
Within the BI connector, there is a tool called mongodrdl.exe.
You can generate a .drdl file from an existing connection within your database using the following command:
mongodrdl -d <databasename> -c <collection name> -o <output name>
In the following example, the host address is not specified since this tool takes by default “localhost:27017”. In this case, drdl schema is generated from DemoCollection1.
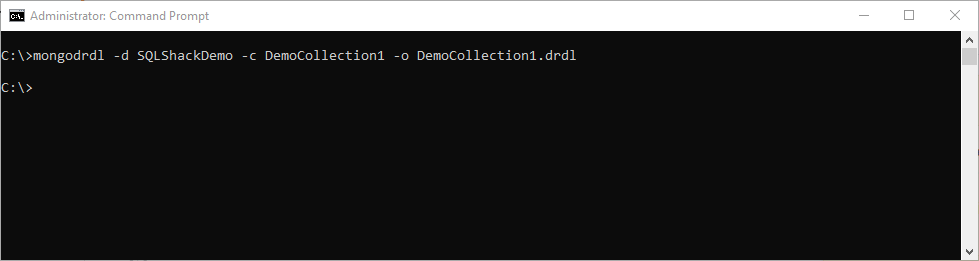
If you open the generated file using a text editor, then it will look like the following:

The image above displays the Generated drdl schema content.
E) Starting the BI Connector Service
After installing the BI connector, navigate to the installation directory and create a new file named “mongosqld.config.” You must use a text editor to access this file and copy the following lines:
<code>net:
bindIp: “127.0.0.1”
port: 3307
systemLog:
path: ‘C:Program FilesMongoDBConnector for BI2.14logsmongosqld.log’
quiet: false
verbosity: 1
logRotate: “rename”
processManagement:
service:
name: “mongosql”
displayName: “MongoSQL Service”
description: “MongoSQL accesses MongoDB data with SQL”
schema:
path: ‘C:DemoCollection1.drdl’Note: Specified directories must exist.
Now, it’s time to install and activate this service. After moving the current directory to the BI connector binaries folder, open a command prompt as an administrator and run the following commands:
<code>mongosqld install –config “<BI connector installation directory>mongosqld.config”
net start mongosql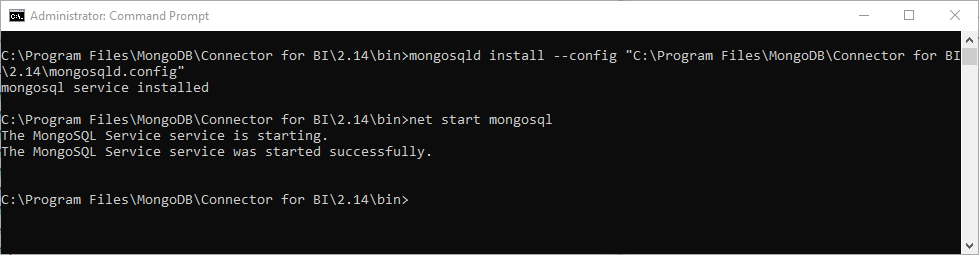
The above image showcases the code for creating the mongosql service.
F) Defining an ODBC Data Source
After installing the ODBC driver, the next step to import data using SSIS is to define a system DSN within Windows.
To do that, the following steps need to be followed:
- Navigate to “Control Panel”.
- Select the “Administrative Tasks” option. Then click on the “ODBC data sources administration” option.
- The “ODBC Data Source Administrator” dialog box appears. Now, in the System DSN tab, click on the “Add” button.

- Select the MongoDB Unicode driver in the “Create New Data Source” dialog box.
- Click on the “Finish” button.

- In the MongoDB ODBC Data Source Configuration dialog box that appears, specify a data source name, enter the mongosql service address (the port specified in the configuration file, not the database engine address), and the database name as shown in the image below:

- You will receive a “Connection successful” message after clicking the “Test” button.
- Click on the “OK” button in the Test Result dialog box. Now, click “OK” in the MongoDB ODBC Data Source Configuration window.

Because Visual Studio only reads 32-bit ODBC data sources, if you use a 64-bit installation, the same steps must be repeated within the 32-bit ODBC data sources.
G) Reading Data using ODBC Source
The steps for reading data using the ODBC Source are as follows:
- Open Visual Studio and create a new Integration Services project.
- Add a new connection to the Connection Managers tab, then select the ODBC connection from the Connection Managers list.


- To provide the destination database name, add an OLE DB connection manager for the SQL Server destination.
- Further, within the Control flow, add a Data Flow Task.
- You also need to include an ODBC Source to read from MongoDB and an OLE DB destination to select (or create) the destination table in the Data Flow Task.
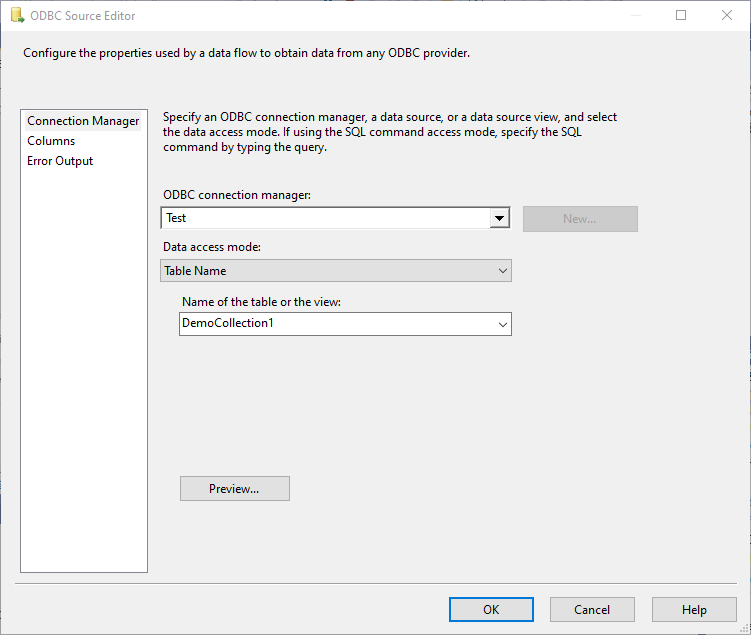
The above image illustrates the process of selecting the MongoDB collection within the ODBC Source.
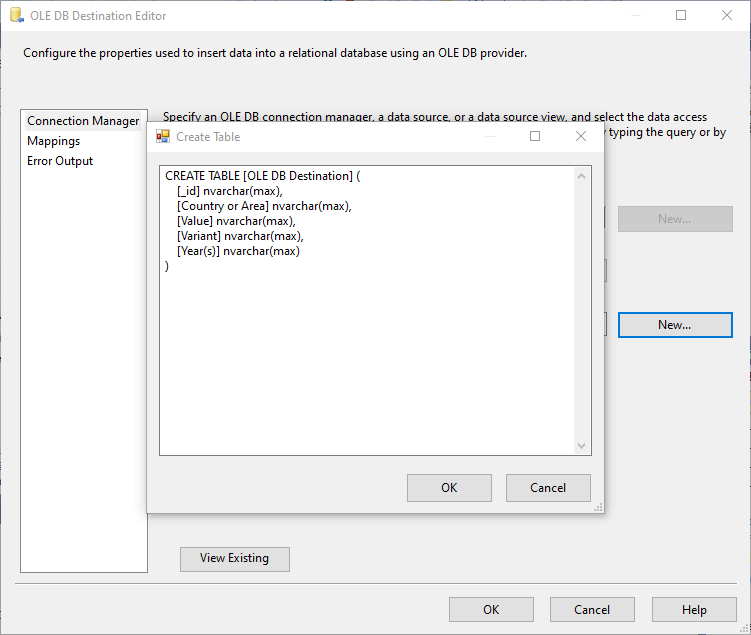
The above image illustrates the process of creating a destination table from the OLE DB destination component.

Limitations of Using SSIS for Data Migration
- SSIS is better suited for batch data transfers, but not ideal for constantly syncing live data streams. You’d need to schedule frequent package executions or develop additional logic for real-time updates.
- Depending on data volume and complexity, SSIS data transfers might not be the most efficient method. Large datasets or intricate transformations could lead to slow processing times.
- Setting up SSIS packages for data migration involves configuration and potentially scripting knowledge. This can require additional development effort compared to some specialized tools.
What is MongoDB?

MongoDB is a popular open-source, document-oriented NoSQL database that stores data in flexible, JSON-like documents. Since its release in 2009, MongoDB has become one of the most widely used databases for modern applications that require scalability, flexibility, and high availability.
MongoDB leverages a binary form of JSON known as BSON to store and transmit document data. BSON extends JSON with additional data types like dates and binaries while retaining the flexible structure. Documents in MongoDB can embed arrays, other documents, and data in a nested format. This hierarchical representation allows complex relationships and varied data schemas within the same database.
A key advantage of the document storage approach in MongoDB is that it does not enforce strict schemas or require predefined record layouts. Developers can store different shaped documents in a single collection dynamically as needs change. This schema-less design makes it simpler to model data and make iterative changes compared to rigid SQL table designs, which depend on predefined columns.
Hevo is a no-code data pipeline platform that supports MongoDB SQL Server Integration. Try Hevo’s no-code platform and see how Hevo has helped customers across 45+ countries by offering:
- Real-time data replication with ease.
- CDC Query Mode for capturing both inserts and updates.
- 150+ connectors(including 60+ free sources)
Don’t just take our word for it—listen to customers, such as Thoughtspot, Postman, and many more, to see why we’re rated 4.3/5 on G2.
Get Started with Hevo for FreeWhat is SQL Server?

Microsoft SQL Server is a trusted relational database management system (RDBMS) that has existed since the late 1980s. At its core, SQL Server provides a robust database engine optimized for processing transactional workloads and executing complex analytical and data transformation tasks.
The database engine consists of several key components working together – a relational engine that handles query parsing and optimization, a storage engine responsible for all data storage/retrieval, and a buffer manager enabling fast data access. These build on advanced features for in-memory tables, column store indexing, and partitioning to deliver performance.
Beyond the database itself, SQL Server includes a rich set of tightly integrated additional services. SQL Server Integration Services (SSIS) offers a graphical workflow tool for building ETL data pipelines. SQL Server Analysis Services (SSAS) enables developers to create multidimensional cubes and data models for fast analytics. Finally, SQL Server Reporting Services (SSRS) provides enterprise reporting and dashboard capabilities.
Why Migrate Data from MongoDB to SQL Server: Benefits and Importance
Moving data from MongoDB to SQL Server opens diverse possibilities for analytics, reporting, insight generation, and decision-making for businesses that want data-driven visualizations and decisions.
SQL Server excels at sharing data across a wide range of databases and services. As such, for many businesses, it is a natural choice for integrating with NoSQL systems like MongoDB. At the same time, MongoDB offers unstructured, large-scale capabilities that complement SQL Server’s structured data handling perfectly.
And this results in a range of benefits for businesses that want to use their data efficiently for decision-making:
- Gain comprehensive insights by blending unstructured data from MongoDB with structured data in SQL Server.
- Enable seamless data sharing between NoSQL and relational systems for smoother operations.
- Leverage advanced analytics using SQL features such as filters, joins, merges, and aggregations.
- Enhance decision-making with a unified, centralized view of diverse data sources.
- Scale effectively by using MongoDB for flexible data storage and SQL Server for complex queries.
- Automate workflows through the integration of operational and analytical systems.
This combination of MongoDB to SQL Server ensures scalability and analytical depth and allows businesses to get more value from their data.
Common Challenges Faced During Migration
- Schema and Data Type Mismatches
- Challenge: MongoDB is a NoSQL database using a flexible, schema-less data model, whereas SQL Server uses a rigid, predefined schema. This mismatch makes it hard to map MongoDB’s dynamic schema and diverse data types—like arrays or nested documents—into structured tables and columns in SQL Server.
- Impact: Inaccurate/incomplete data mapping can result in data integrity problems, data loss, and further querying and analytical issues.
- Data Transformation Complexity
- Challenge: Most of the data in MongoDB requires a huge amount of transformation to fit into the relational structure in SQL Server. For example, nested documents and arrays in MongoDB have to be flattened or divided into several tables with relationships in SQL Server.
- Impact: More complex transformations offer more possibilities for failure and add new challenges to the ETL process, which may relate to delays or additional development.
- Performance and Scalability Issues
- Challenge: Migrating vast volumes of data from MongoDB can severely stress performance and scalability in any case, either because your data is not efficiently indexed or the migration process itself is unoptimized with regard to performance.
- Impact: Poor performance during migration can cause disruptions that last longer than expected, slow data loads, or even affect business operations as a whole.
You can also read more about:
Conclusion
Moving data from MongoDB to SQL Server gives more structure to the data, ensuring data quality and consistency owing to SQL Server’s relational data model.
This article provided an in-depth understanding of the three methods that you can use to migrate data, including an automated tool like Hevo, manually building ETL scripts, and using SSIS.
MongoDB or SQL Server may be used by enterprises and organizations of all sizes that need to scale out large amounts of data and traffic. If you want to use data quickly and with a lot of flexibility, a no-code platform like Hevo is the way to go. Sign up for a 14-day free trial and experience the feature-rich Hevo suite firsthand.
Frequently Asked Questions
1. Can I use SQL with MongoDB?
Yes, you can use SQL with MongoDB through tools like MongoDB Atlas, which offers SQL-like query capabilities, or connectors like MongoDB Connector for BI that translate SQL queries into MongoDB queries.
2. How is NoSQL faster than SQL?
NoSQL databases are often faster for certain operations because they use flexible, schema-less data models and can handle unstructured data efficiently. They are optimized for horizontal scaling, making them suitable for high-performance, distributed applications.
3. Why is NoSQL cheaper than SQL?
NoSQL databases can be cheaper due to their ability to scale horizontally on commodity hardware. They often require less management and offer more flexible data models, reducing the complexity and cost associated with schema migrations and scaling.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link




