

Amazon S3 is a popular storage solution from the stable of Amazon. It is a reliable and stable solution when it comes to storing enterprise data. Microsoft SQL Server is a leading RDBMS platform in the market. It is efficient in querying data and performing operations through an end-to-end process.
By migrating data from Amazon S3 to SQL Server, a proper ETL process can be performed to gain the most from the data. It also enables a proper insight generation from the data.
This article details two comprehensive methods that can be used to migrate data from Amazon S3 to SQL Server.
Table of Contents
What is Amazon S3?

Amazon S3 is a popular storage service from the house of Amazon Web Services. It is object-based storage that enables the users to store large amounts of data present in various formats like application files, blogs, codes, and many more with ease. S# stands for Simple Storage Service.
Amazon S3 is believed to be 99.9999% durable and ensures the high availability of data. It is a robust platform with the availability of various integrations, that enable it to be integrated with numerous sources to perform ETL. It also supports the integration of various programming languages like Python, Java, Scala, and more. Amazon S3 further has a provision for command-line interfacing that allows performing operations like adding, modifying, viewing, and manipulating data present in S3.
Amazon S3 provides industry-leading scalability, security, accessibility, and performance. The data is stored in form of Buckets. It supports a single object size of 5 TB. It also has Data Management features built-in so that it is easy to handle data.
You can also take a look at the key differences explained between Amazon S3 vs Redshift to get a clear idea of how the 2 platforms work.
Hevo Data is a No-code Data Pipeline solution that can help you move data from 150+ data sources like S3 to your desired destination like MS SQL Server.
- No-Code Solution: Easily connect your Amazon S3 data without writing a single line of code.
- Flexible Transformations: Use drag-and-drop tools or custom scripts for data transformation.
- Real-Time Sync: Keep your destination database updated in real time.
- Auto-Schema Mapping: Automatically handle schema mapping for a smooth data transfer.
Hevo also supports MS SQL Server as a source and Amazon S3 as a destination for loading data to a destination of your choice. Using Hevo, you no longer have to worry about how to integrate S3 with SQL Server.
Get Started with Hevo for FreeWhat is Microsoft SQL Server?

SQL Server is a popular Relational Database Management System. It was developed by Microsoft and launched on April 24, 1989. It was written in programming languages C and C++. It follows a relational model architecture that was invented by E.F.Codd.
The Relational Model stores the data in a structured format and generates relations between each table. The data is organized in the form of rows and columns where the column represents an attribute or feature and the row represents the value or record.
SQL Server comes in many versions, each with a slightly different feature set and query limits. The versions are Express, Enterprise, Standard, Web, and Developer. In case you want to install SQL Server, you may visit the official website and download a version as per your system requirements.
You can check out the different SQL Server Replication types as well to get a better idea of how SQL Server functions.
Methods to Migrate Data from Amazon S3 to SQL Server
Data can be migrated from Amazon S3 to SQL Server via two different methods.
- Method 1: Migrate Data from S3 to SQL Server via AWS Services
- Method 2: Automated S3 to SQL Server Migration using Hevo Data
Method 1: Migrate Data from S3 to SQL Server via AWS Services
- Step 1.1: Create an AWS S3 Bucket
- Step 1.2: Add Sample Data as CSV Files in S3 Buckets
- Step 1.3: Configure SQL Server Database Tables & Objects
- Step 1.4: Create the IAM Policy for accessing S3
- Step 1.5: Push Data from S3 to SQL Server Instance
Step 1.1: Create an AWS S3 Bucket
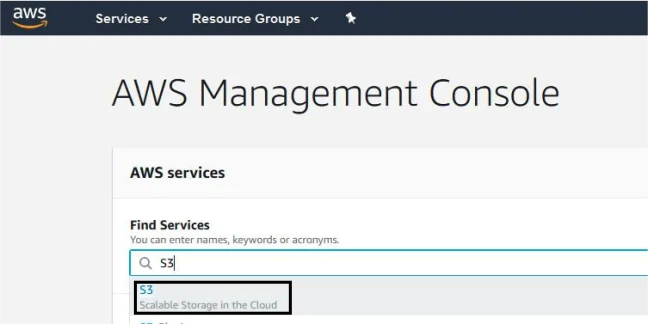
- Log in to your Amazon Console.
- Click on Find Services and search for S3.
- Now, click on the Create Bucket button.
- Enter the bucket name and select the region.
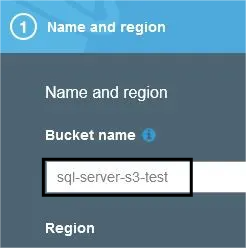
- Click on the Create Button.
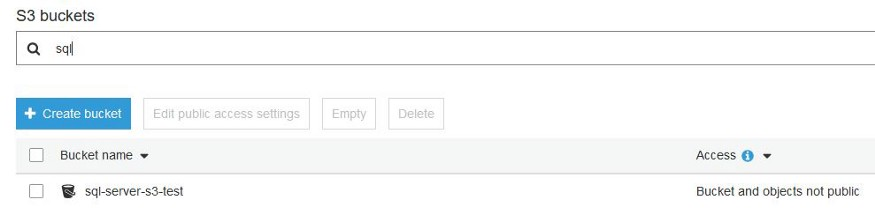
- Search for the Bucket, and check for access. It should not be public.
Step 1.2: Add Sample Data as CSV Files in S3 Buckets
- Create a file “employee_Hevo.csv.”
- Add the following components:
Employee_Id,Employee_First,Employee_Last,Employee_Title
1,Jane,Doe,Software Developer
2,Vikas,Sharma,Marketing
3,Rajesh,Kumar,Project Manager
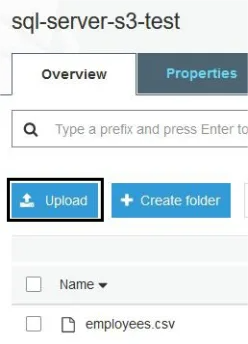
4,Akshay,Ram,Customer Support- In the S3 console, select the bucket name you just created.
- Click on the upload option and follow the onscreen instructions.
Step 1.3: Configure SQL Server Database Tables & Objects
- Open SQL Server Management Studio and run the script below or create a similar table.
CREATE TABLE [dbo].[Employees](
[Employee_Id] [int] IDENTITY(1,1) NOT NULL,
[Employee_First] [varchar](25) NULL,
[Employee_Last] [varchar](25) NULL,
[Employee_Title] [varchar](50) NULL,
CONSTRAINT [PK_Employees] PRIMARY KEY CLUSTERED
(
[Employee_Id] ASC
)
WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF,
IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON,
ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]Step 1.4: Create the IAM Policy for Accessing S3
- Before the data is migrated from S3 to SQL Server, you need to set up IAM policies so that the bucket you created earlier is accessible.
- Click on AWS search and search IAM.

- In the policies section, click on create policy
- Click on the choose a service button to search for S3.
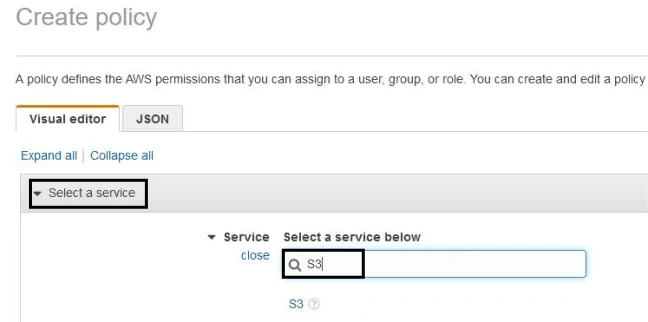
- Complete and fill all the access levels and parameters.

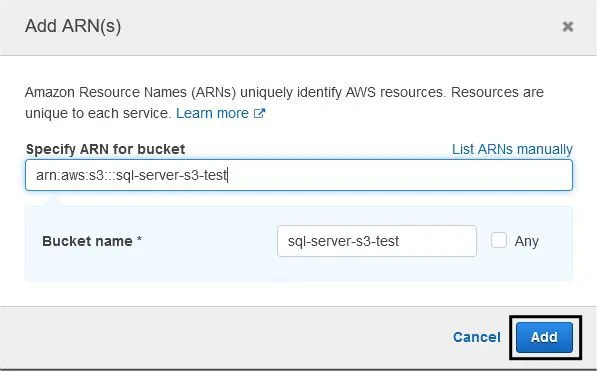
- In the resources tab, select the bucket name and click on the Add ARN button. Enter the bucket name.
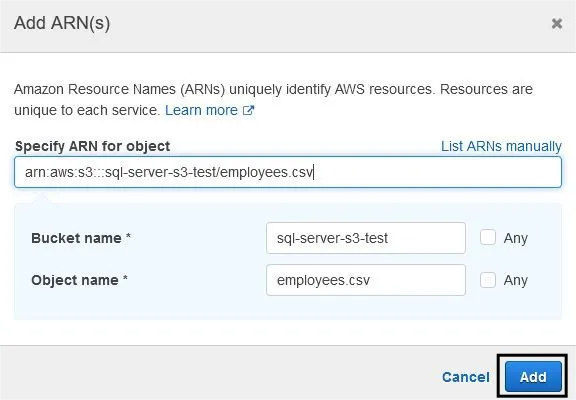
- Add the CSV file by specifying the ARN.
- Go to the review policy section and click on Create Policy.

- Create the IAM role to use the policy. Open the AWS Console, and go to IAM. Select the Roles tab.
- Click on create the role. Follow the below mentioned order:
- AWS service (at the top.)
- RDS (in the middle list, “select a service to view use cases”.)
- RDS — Add Role to Database (towards the bottom in the “Select your use case” section.)
- Click on the next: permission button. Attach the permission policies by entering the name of the policy.
- Follow the instructions on the screen. Click on review role, enter the values and then click on create the role.

Step 1.5: Push Data from S3 to SQL Server Instance
- Open the AWS Console and click on RDS.
- Choose the SQL server instance name to load data from S3 to SQL Server.
- In the security and connectivity tab, select the IAM roles and click on Add IAM Roles.
- Choose S3_integration in the feature section.
- Click on Add Role button.

Limitations of a Manual Approach
- The manual method for loading data from S3 to SQL Server requires a lot more technical expertise.
- There are many steps involved in the manual method for S3 to SQL Server and in case a step gets mixed up, all the steps need to run from the start.
- Creating IAM roles and access control is difficult.
Method 2: Automated S3 to SQL Server Migration using Hevo Data
Step 2.1: Configure S3 Source in Hevo
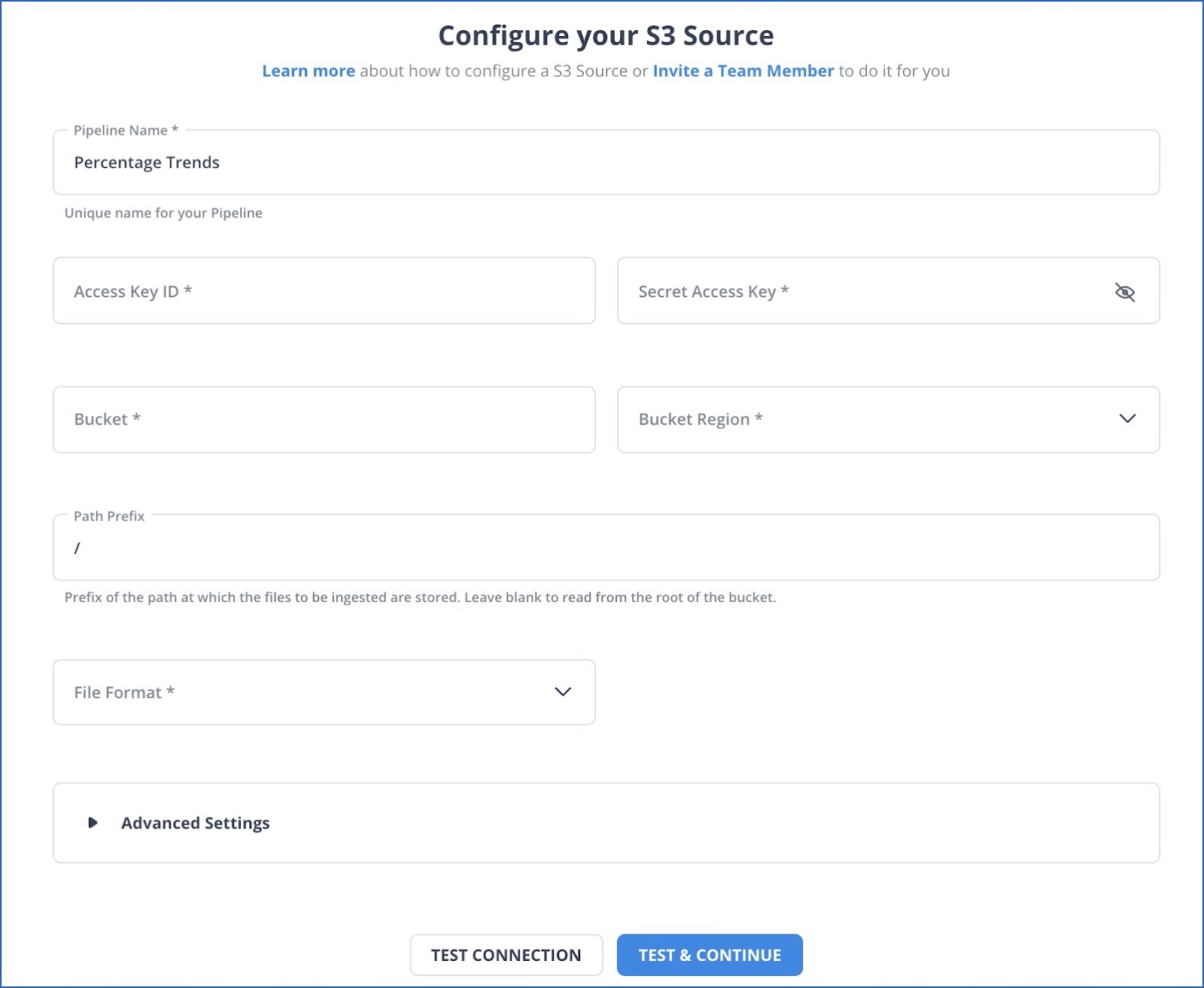
How to Obtain your Access Key ID and Secret Access Key
You require a secret key to set S3 as a source. Perform the following steps to obtain your AWS Access Key ID and Secret Access Key:
- Log in to the AWS Console.
- In the drop-down menu in the profile section, click on security credentials.

- On the Security Credential page, click on Access Keys.
- Click Create New Access Key.
- Click Show Access Key to display the generated Access Key ID and Secret Access Key. Copy the details or download the key file for later use.
For more information, refer the Hevo’s documentation for AWS S3.
Step 2.2: Configure SQL Server Destination in Hevo

For more information, refer the Hevo’s documentation for SQL Server.
Organize data into ranges with SQL bucketing to simplify analysis, such as age groups or income brackets. Learn more about Bucket Data in SQL in detail to work seamlessly with your SQL Server destination.

Benefits of S3 to SQL Server Integration
- Centralized Data Access: Combines unstructured data from S3 and structured data in SQL Server for comprehensive insights.
- Enhanced Analytics: Enables advanced querying and analysis on S3 data using SQL Server’s powerful capabilities.
- Improved Data Management: Streamlines data storage, transformation, and retrieval between S3 and SQL Server.
- Data Backup and Recovery: Acts as a reliable backup solution by syncing S3 data with SQL Server.
- Seamless Workflows: Automates data pipelines, reducing manual intervention and improving efficiency.
Use Cases of S3 to SQL Server Integration
- Data Warehousing: Load raw data from S3 into SQL Server for building a centralized data warehouse.
- Business Reporting: Use SQL Server to generate reports and dashboards using data stored in S3.
- Data Transformation: Process and clean S3 data in SQL Server before further analysis or visualization.
- Backup and Archiving: Store processed SQL Server data in S3 for long-term backup and compliance.
- IoT Data Management: Stream IoT data from S3 to SQL Server for real-time monitoring and analytics.
Also, take a look at how you can seamlessly connect SQL Server to S3 and similarly, how you can load and stream data from Amazon S3 to Snowflake.
You can also read more about:
- Salesforce to SQL Server
- SQL Server to S3
- PostgreSQL on Google Cloud to SQL Server
- BigQuery to SQL Server
Conclusion
Amazon S3 is one of the best data storage solutions that support various different formats. It stores the data efficiently but getting insight from it is slightly difficult. Migrating data into a more traditional RDBMS allows us to gain insights better. This article provides two different methods that can be used to migrate data from S3 to SQL Server.
There are various trusted sources that companies use as it provides many benefits, but, transferring data from it into a data warehouse is a hectic task. The Automated data pipeline helps in solving this issue and this is where Hevo comes into the picture. Hevo Data is a No-code Data Pipeline and has awesome 100+ pre-built Integrations such as AWS S3 & SQL Server that you can choose from.
Sign up for Hevo’s 14-day free trial and experience seamless data migration. Check out the pricing details to understand which plan fulfills all your business needs.
FAQ on Migrate Data from S3 to SQL Server
1. How to connect SQL Server to S3 Bucket?
– Install the necessary PolyBase components.
– Configure PolyBase to use the S3 connector.
– Create an external data source pointing to your S3 bucket.
– Create an external file format to describe the format of the data files.
– Create an external table that references the data in your S3 bucket.
2. Can you query S3 with SQL?
– Store your data in S3.
– Set up AWS Athena.
– Define a schema for your data in Athena.
– Use SQL queries to analyze your data in S3
3. How to transfer data from SAP to SQL Server?
– Create a data flow in SAP Data Services.
– Use the SAP extractor to extract data from SAP.
– Use a data loader to load the extracted data into SQL Server.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





