

Databricks is a popular and powerful unified analytics platform. It helps organizations streamline their data engineering, machine learning, and analytics tasks. As data grows and organizations understand the importance of data-driven decision-making, it becomes important to analyze and optimize the costs of data platforms being used carefully. Without careful management, organizations may end up having huge bills.
Thus, in this blog, we discuss databricks cost optimization strategies and best practices that can help businesses fetch maximum value against the money they are paying.
Are you having trouble migrating your data into Databricks? With our no-code platform and competitive pricing, Hevo makes the process seamless and cost-effective.
- Easy Integration: Connect and migrate data into Redshift without any coding.
- Auto-Schema Mapping: Automatically map schemas to ensure smooth data transfer.
- In-Built Transformations: Transform your data on the fly with Hevo’s powerful transformation capabilities.
- 150+ Data Sources: Access data from over 150 sources, including 60+ free sources.
You can see it for yourselves by looking at our 2000+ happy customers, such as Airmeet, Cure.Fit and Pelago.
Get Started with Hevo for FreeTable of Contents
What is Databricks?

Databricks is a cloud-native advanced analytics platform. It was designed to solve complexities faced by data engineering teams as the data grows. Different teams might have different requirements. This platform allows the monitoring and managing of batch and streaming pipelines in parallel. The platform supports a range of languages, including Python, Scala, and SQL, enabling data scientists and engineers to collaborate effortlessly.
Databricks can be used for
- Scheduling and managing ETLs.
- Visualize your data and create dashboards.
- Enable governance and maintain security, high availability
- Catalog data and facilitate easy data discovery, reducing exploration time
- Machine Learning Modeling, monitoring, and running pipelines both in streaming and batch fashion.
- Generative AI solutions
Teams can interact with Databricks using workspace UI or programmatically with REST API, CLI, or Terraform. Databricks also supports integration with open-source tools like Delta Lake, MLflow, Apache Spark, and Redash.
Databricks Architecture
Databricks architecture consists of the following main components.
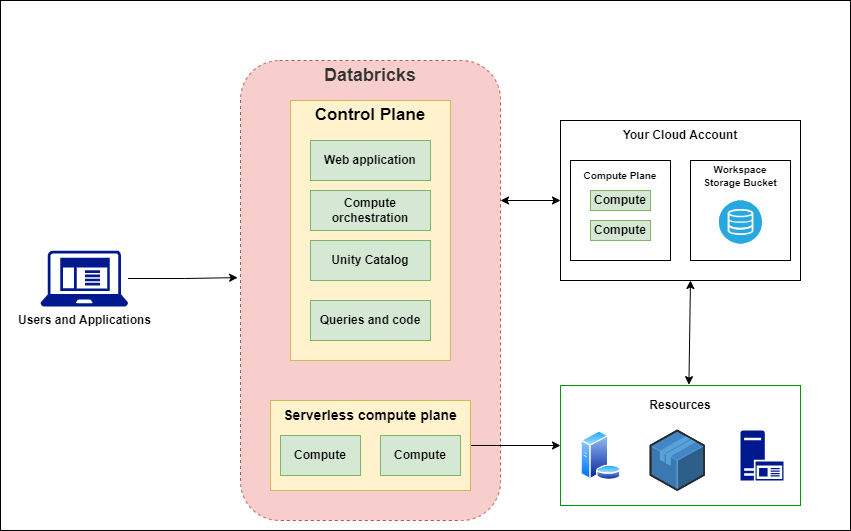
Control Plane
The control plane consists of backend services. The web application for Databricks also resides in this plane. It is responsible for managing user interactions and job scheduling.
Compute Plane
The compute plane is responsible for executing workloads. This is the place where data is processed. Compute planes are of two types, depending on the compute that you want to use.
- Serverless Compute: This compute resource runs in a serverless compute plane.
- Databricks Compute: These compute resources reside in your cloud account.
Workspace
Workspaces are used for version control and collaboration. Each workspace is associated with a storage bucket, known as a workspace storage bucket. It consists of
- Workspace System Data: Data and Metadata generated as part of using various Databricks features.
- DBFS: Distributed file system for Databrics environment.
- Unity Catalog: If enabled, stores catalog information for the entire workspace data.
Explore how Databricks Architecture can influence cost-saving strategies in our guide on Understanding Databricks Architecture.


Databricks Pricing
Databricks offers a flexible pricing model based on compute resources used, typically measured in Databricks Units (DBUs). Its pricing works with the pay-as-you-go model. Different products may have different pricing, namely
- Workflows and Streaming: Starts from $0.15 per DBU
- Data Warehousing: Starts at $0.22 per DBU
- Data science and Machine Learning: Starts at $0.40 per DBU
- Generative AI: Starts at $0.07 per DBU
In addition to the above, Databricks pricing varies by cloud provider:
- Azure Databricks: Starting at approximately $0.07/DBU.
- AWS Databricks: Ranges from $0.40 to $0.75/DBU, depending on instance type. Organizations can expect to pay around $1.20 to $2.00 per hour for cluster usage, depending on configuration and workload requirements.
Discover how Databricks Medallion Architecture can play a key role in optimizing your data management strategy, ultimately contributing to cost efficiency in Databricks environments.
Best Practices for Databricks Cost Optimization
Below, we discuss some of the best practices for Databricks cost optimization:
1. Auto Scaling
Enable autoscaling in clusters to adjust resources based on workload demands and reduce idle costs. While this is beneficial, it needs to be carefully planned, as it can sometimes be less efficient when scaling events occur frequently. You might want to use a fixed number of instances in this case.
2. Cluster Sizing
It is very important to carefully select the right-sized clusters for job execution. Start with smaller clusters and then gradually increase them. It is also important to educate platform users on choosing the right clusters.
3. Auto Termination
Databrics provides this feature of auto termination to stop instances if there is no activity. You can set up instances to stop after 30 minutes(choose time according to your use case) of inactivity.
4. Spot Instances
Using spot instances for no-critical workloads can help save up to 80% of costs on computing.
5. Adaptive Query Execution
Enabling Adaptive Query Execution (AQE) can help reduce overall compute costs. When this setting is enabled, AQE automatically adjusts shuffle partitions and optimizes query performance.
6. Delta Lake
Use Delta Lake for efficient storage and data management. It uses snappy compression and parquet format to help reduce costs associated with data storage, retrieval, and processing. Users can also optimize and set delta.targetFileSize to help balance size and performance. You can also improve Delta Lake operations by understanding how to leverage Databricks’ Overwrite functionalities.
7. Vacuum
Using the vacuum command on Delta Lake deletes old data. File compaction and vacuum can be automated at regular off-peak intervals, helping reduce storage costs and improve query performance.
8. Serverless SQL for BI Reports
For reporting use cases, you can use Databrick’s serverless SQL warehouses. They are quick to start and can help significantly reduce costs and help in Databricks cost optimization.
9. Job Scheduling
Optimized job clusters should be used for scheduled jobs. These are more cost-efficient than all-purpose clusters. All-purpose clusters are more suited for ad-hoc analysis,
10. Data Storage Optimization
Use Delta Lake for efficient storage and data management, reducing data retrieval and processing costs.
11. Monitoring and Alerts
Teams can set alerts on cost thresholds and track usage for proactive cost management. Tags can further be leveraged to filter and sum up costs for specific use cases. You can also strengthen monitoring and alerts by utilizing Databricks Secret Scopes for secure configurations.
Looking for alternatives to Databricks? Explore our list of the top 10 competitors to help optimize your data strategy for 2025.
Conclusion
Databricks provide great capabilities for data processing and analytics needs. By implementing the above-discussed best practices, organizations can reduce expenses and benefit fully from the powerful analytics capabilities provided by the platform. Databricks cost optimization requires strategic resource management, effective data management, and scheduling. With new features being released by Databricks, it is important to stay updated on pricing and architectural changes. This can help teams to implement updated optimization techniques to maximize return on investment.
FAQs on Databricks Cost Optimization
How much does Azure Databricks cost vs AWS?
Azure Databricks starts at around $0.07 per DBU and may range up to $0.7 DBU, while AWS pricing ranges from $0.40 to $0.75 per DBU. These figures may vary based on instance type, usage patterns, and resource configurations.
Why is Databricks so valuable?
Databricks provides a single platform for data processing and machine learning needs. It is designed to enable faster development and deployment of optimized data workflows. Its easy-to-use features help derive faster insights, making it a valuable business tool.
When should you not use Databricks?
Small-scale businesses having light data processing tasks and minimal data analytics requirements should not use databricks. Companies with low or tight budgets can also explore alternatives for their data platform requirements.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





