




Amazon Redshift is a renowned Cloud-based repository that offers Data Warehousing services and supports fast query processing on huge datasets. Businesses of all verticals leverage this scalable tool to accumulate their petabytes of data. It is the go-to platform for Big Data professionals because of its easy-to-use interface and vast collaboration options. However, companies often need to collaborate their structured and unstructured data for analysis. Since Amazon Redshift can only operate on well-structured data, organizations seek to transfer their data to a platform that can support all forms of information. One such destination is Databricks.
Databricks is a robust open-source storage layer that provides you with a lakehouse architecture that operates at the cost of a Data Lake but provides high-level Data Warehousing performance. Moreover, companies can seamlessly run Databricks on top of their existing Data Lake.
This article will introduce you to Databricks and Amazon Redshift along with their unique features. It will also discuss 2 simple methods using which you can transfer your data from Redshift to Databricks. Read along to learn the process of setting up the Redshift Databricks integration and its advantages!
Table of Contents
What is Databricks?

Databricks is one of the most popular Data Engineering platforms that rely on Cloud-based technology to perform analysis on vast datasets. It also facilitates data management at a granular level with its Machine Learning features. Moreover, after collaboration with Azure, Databricks is now acting as the latest Big Data tool in the vast Microsoft cloud environment.
Databricks finds applications in businesses from all verticals as this tool allows companies to perform high-level Data Analytics by leveraging Machine Learning technology with ELT (Extract Load Transform) processes. The popularity of Databricks platforms is because of their ability to process data in a distributed manner. This implies, that Databricks can segment the workload into multiple subtasks and run them on different processors. This way, you can scale up your work seamlessly to match your changing data needs. Furthermore, Databricks also works well in simplifying high-end Data Processing and at the same time automates Machine Learning models intending to reduce your work complexity.
Key Features of Databricks
Databricks contains the following features that facilitate seamless data processing data:
- High Data Compression: Databricks work with the Spark Engine to manage large-scale Data Compression. It also supports a high-speed Data Streaming & Query Processing environment that can simplify your data management and generates a programmer-friendly environment.
- Vast Collaborations: Databricks provide a common platform for stakeholders for collaborating especially when they are relying on different programming languages for software development. For instance, programmers using programming languages such as Python, R, & Scala can merge their work using Databricks’s interactive features and user interface.
- Robust Security: When it comes to its data’s safety, Databricks has multiple layers of security for regulating access to its information. For example, identity management and public key encryption are some security measures adopted by Databricks.
To learn more about Databricks, visit here.
What is Amazon Redshift?

Amazon Redshift is a high-level storage facility offered by Amazon’s Cloud technology. It is a Data Repository that lets you solve your Big Data Storage problems. This Amazon Data Warehouse provides you with a scalable storage system that is capable of storing petabytes of data in easily accessible Clusters which you can query simultaneously.
Amazon Redshift’s design allows it to integrate readily with a rich collection of data sources and tools. Moreover, you can launch existing SQL environments directly on this Data Warehouse. Since Redshift deploys a Massively Parallel Processing (MPP) based architecture, it can process millions of rows in one go and even provide high levels of scalability. Furthermore, Redhsift’s layered structure caters to multiple data requests at the same time and reduces latency.
Key Features of Amazon Redshift
- High Performance: Amazon Redshift’s architecture allows it to support high-speed query processing even on vast datasets ranging in the order of petabytes. This high data support is because of the column storage & data compression features of this Data Warehouse which reduces the I/ O required for processing a query.
- Machine Learning: Amazon Redshift’s complex machine learning models ensure a high throughput even if you are working with variable workloads & user activity. Since it uses well-developed algorithms for predicting the ranks of incoming requests, this Data Warehouse can allocate resources dynamically to various clusters.
- Scalable: Amazon Redshift’s convenient scalability allows you to meet the increasing data needs of the current market. A few dashboard clicks or a simple API call is enough to scale the number of nodes.
- Secure: Using simple options, you can manually configure Amazon Redshift to comply with SSL for providing security to your data in transit. Moreover, you can rely on hardware-accelerated AES256 encryption for securing your data at rest.
To learn more about the capabilities of Amazon Redshift, visit here.
Amazon Redshift has proven abilities to manage high data volumes, fault tolerance, and durability. Moreover, Databricks is a storage repository that offers a Data Warehousing facility and performs a real-time analysis. When integrated, moving data from Redshift to Databricks could solve some of the biggest data problems for businesses. In this article, we have described two methods to achieve this:
Method 1: Databricks Redshift Integration Using Hevo Data
Hevo Data, an Automated Data Pipeline, provides you a hassle-free solution to connect Redshift to Databricks within minutes with an easy-to-use no-code interface. Hevo is fully managed and completely automates the process of not only loading data from Redshift but also enriching the data and transforming it into an analysis-ready form without having to write a single line of code.
GET STARTED WITH HEVO FOR FREEMethod 2: Databricks Redshift Integration Using CData
This method would be time-consuming and somewhat tedious to implement. Users must write custom codes to manually set up the data transfer process via CData. Furthermore, this method is suitable only for users with a technical background.
Both the methods are explained below.
Method 1: Databricks Redshift Integration Using Hevo Data
Hevo Data is a No-code Data Pipeline solution that can help you seamlessly replicate data in real-time from 100+ Data Sources (Including 40+ free sources) such as Redshift to your desired destination like Databricks, other Data Warehouses, or Databases in a completely hassle-free & automated manner. Hevo’s fault-tolerant architecture automates the whole ETL process and its scheme mapper dynamically maps your data from Redshift to Databricks without requiring any human intervention. Therefore, you can focus on other key business activities and rely on Hevo to manage the data transfer process.
Connecting Databricks to Redshift using Hevo is a simple two-step process.
- Authenticate Source: Using your Hevo account, set up a pipeline and authenticate your Amazon Redshift account as the data source as shown in the below image:

- Configure Destination: Next, set up your Databricks account as the destination for Hevo’s No-code Data Pipeline as shown in the below image:

That’s it! Your Databricks Redshift integration is ready and you can now easily analyze the Redshift data in Databricks.
Check out what makes Hevo amazing:
- Fully Managed: Hevo requires no management and maintenance as it is a fully automated platform.
- Data Transformation: Hevo provides a simple interface to perfect, modify, and enrich the data you want to transfer.
- Faster Insight Generation: Hevo offers near real-time data replication so you have access to real-time insight generation and faster decision making.
- Schema Management: Hevo can automatically detect the schema of the incoming data and map it to the destination schema.
- Scalable Infrastructure: Hevo has in-built integrations for 100+ sources (with 40+ free sources) that can help you scale your data infrastructure as required.
- Live Support: Hevo team is available round the clock to extend exceptional support to its customers through chat, email, and support calls.
Method 2: Databricks Redshift Integration Using CData
You can set up the Databricks Redshift integration using CData by following the below steps:
Step 1: Install JDBC Driver on Azure Cluster
To transfer real-time Redshift data to Databricks, you need to install the JDBC driver on the Azure cluster using the following steps:
- Go to to the Databricks administration screen in your account and click on the target cluster.
- Now, navigate to the Libraries tab and select “Install New.”
- Next, choose “Upload” as the source and “Jar” as the type of Library.
- Finally, upload the JDBC JAR file (cdata.jdbc.redshift.jar) from your local system as shown in the below image.

Step 2: Establish the Databricks Redshift Connection
Once you have installed the JAR file, create a notebook in the workspace and name it. Next, select Python as the choice of language and then click on the cluster where JDBC Driver is installed. After launching the notebook you can configure the connection and query Amazon Redshift data to create a simple report.
Step 3: Configure the Databricks Redshift Connection
You can establish the Redshift Databricks connection by referencing the JDBC Driver class and using it to construct a connection string fr JDBC URL. Moreover, you must set the RTK property in JDBC URL as follows:
driver = "cdata.jdbc.redshift.RedshiftDriver"
url = "jdbc:redshift:RTK=5246...;User=admin;Password=admin;Database=dev;Server=examplecluster.my.us-west-2.redshift.amazonaws.com;Port=5439;
Fill in the required details and configure it completely.
Step 4: Load & Display Redshift Data
Once the Databricks Redshift connection is configured, you can directly load Redshift data in the form of a data frame via the CData JDBC Driver by using the following code:
remote_table = spark.read.format ( "jdbc" )
.option ( "driver" , driver)
.option ( "url" , url)
.option ( "dbtable" , "Orders")
.load ()
Next, monitor the loaded Redshift data by using the display function as follows:
display (remote_table.select ("ShipName"))The output of this code is shown in the below image:
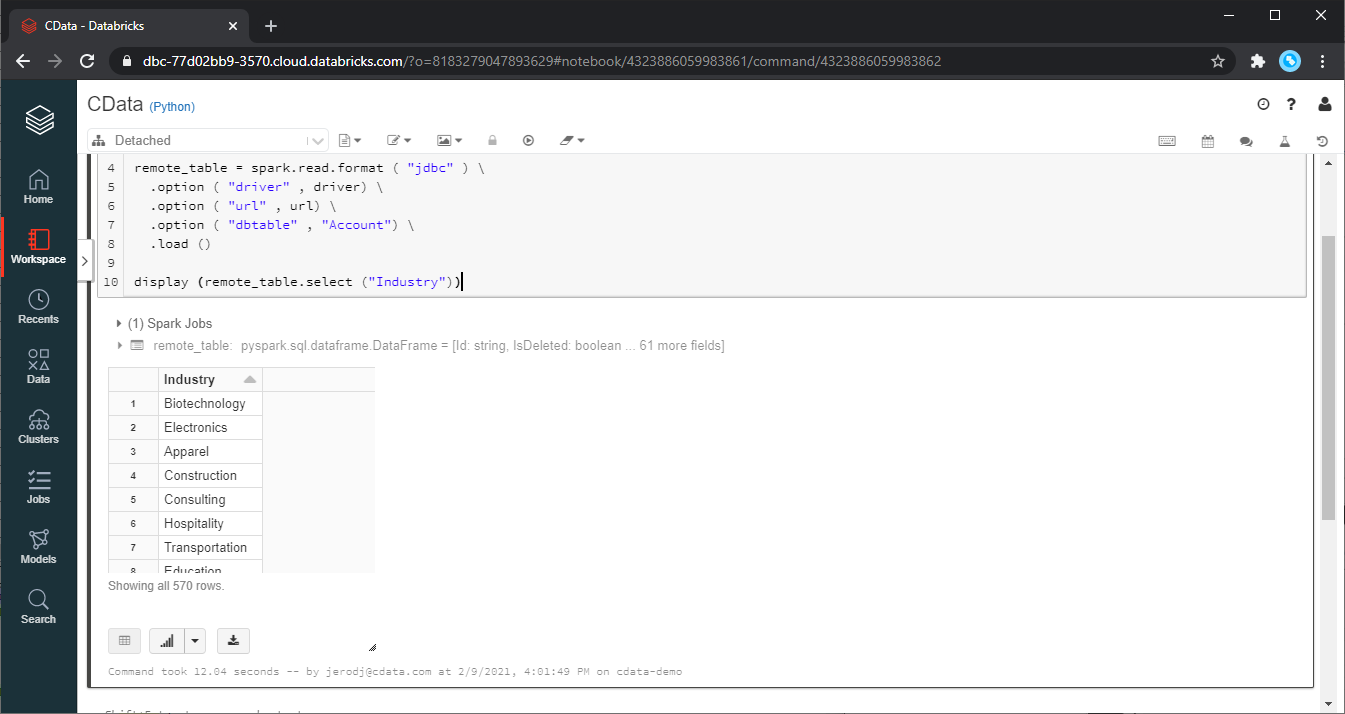
Step 5: Perform Data Analysis in Databricks
If you wish to leverage the Databricks Redshift connection for data analysis, register the loaded information as Temp View via Databricks SparkSQL as follows:
remote_table.createOrReplaceTempView ( "SAMPLE_VIEW" )Moreover, you can use the following SparkSQL code to retrieve the Redshift data for analysis.
SELECT ShipName, ShipCity FROM OrdersKeep in mind that the data from Redshift is available only in the target notebook. This implies you need to first save it as a table as shown below:
remote_table.write.format ( "parquet" ) .saveAsTable ( "SAMPLE_TABLE" )
The following output is generated by the above code:
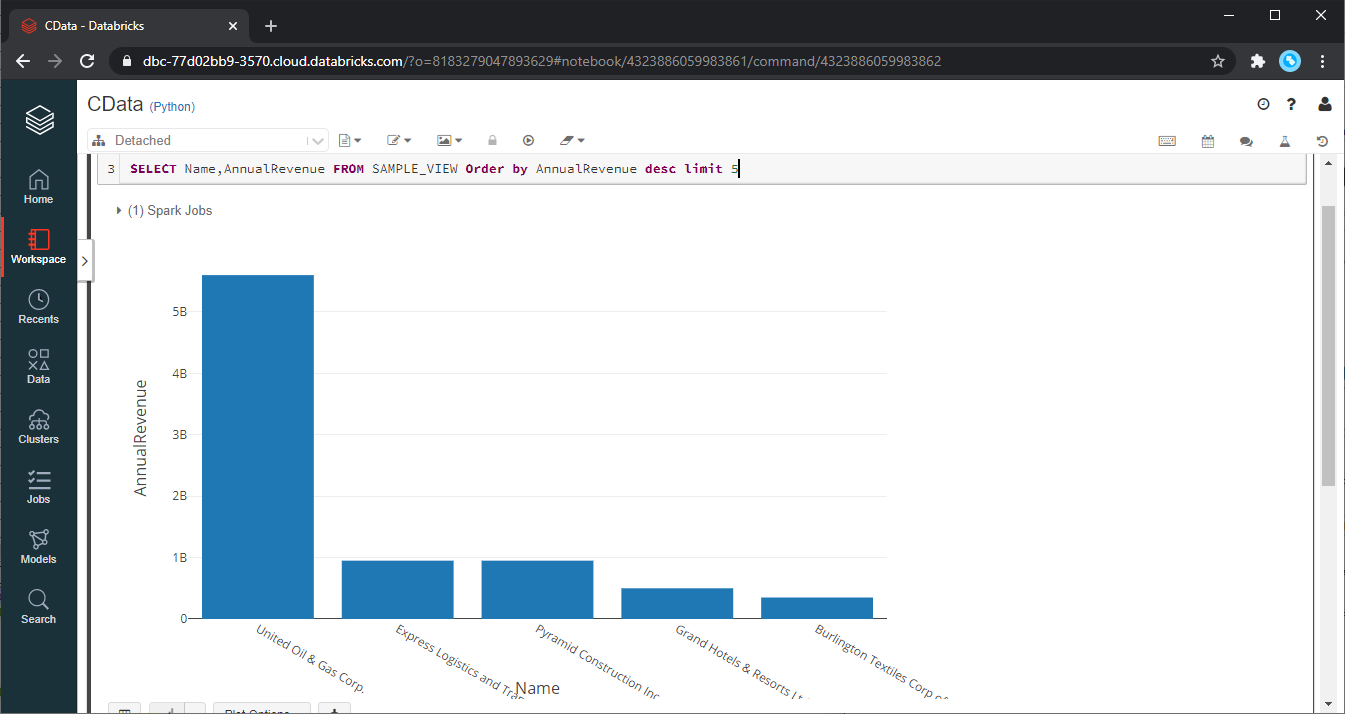
You can now use the Databricks Redshift integration to analyze your business data and extract actionable insights.
Advantages of Databricks Redshift Integration
You can experience the following advantages by setting up the Databricks Redshift integration:
- Your Data Engineers will be able to utilize Redshift data to create and edit complex clusters of unstructured data in Databricks. This allows your Data Professionals to utilize such clusters and send them to Data Scientists & Data Analysts for review.
- Using the Databricks Redshift integration, your Data scientists can expand their search horizons and offer better insights. Moreover, you can run various advanced analyses on a common data cluster in a single interface. During this time Databricks performs auto-scaling to minimize the total resources used.
- Insights derived from your Redshift data can be easily stored in Azure Databricks once the Databrocks Redshift integration is in place. This is a preferable way of processing raw information as the architecture of Databricks allows you to manage data at a petabyte-scale, and also lets you operate on data of any type and scale. The Databricks platform utilizes Power BI, which is capable of visualizing your findings into an interactive dashboard.

Conclusion
The article introduced you to Databricks and Amazon Redshift along with their key features. It also provided you with a step-by-step guide to set up the Databricks Redshift integration using 2 easy methods. Furthermore, the blog discussed the multiple advantages of connecting these 2 tools. The CData-based manual method requires you to write the script for Databricks Redshift integration and provide regular maintenance to the established connection. All such limitations of the manual method can be overcome by using an Automated Data Pipeline like Hevo.
Visit our Website to Explore HevoNow, to run queries or perform Data Analytics on your raw data, you first need to export this data to a Data Warehouse. This will require you to custom code complex scripts to develop the ETL processes. Hevo Data can automate your data transfer process, hence allowing you to focus on other aspects of your business like Analytics, Customer Management, etc. This platform allows you to transfer data from 100+ sources such as Redshift to Databricks, or to any other destination of your choice. It will provide you with a hassle-free experience and make your work life much easier.
Want to take Hevo for a spin? Sign Up for a 14-day free trial and experience the feature-rich Hevo suite first hand.
Share your understanding of Databricks Redshift Integration in the comments below!

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link


