




Managing data across multiple tools can feel like juggling too many balls. Google Drive helps you store files, while Databricks takes care of analytics. But moving data between them manually? That’s a lot of extra work! Thankfully, integrating these platforms can change the game, letting you focus on what really matters—your insights.
In this post, we’ll explore how to seamlessly connect Google Drive to Databricks using an easy no-code method and a more hands-on approach. Stick around to see how this integration can save you time and effort.
Table of Contents
What is Google Drive?

Google Drive is a cloud-based storage service that enables users to store and access files online. The service syncs stored documents, photos and more across all the user’s devices, including mobile devices, tablets and PCs. Read about connecting Google Drive to SFTP for file management.
What is Databricks?

Databricks is a unified, open analytics platform for building, deploying, sharing, and maintaining enterprise-grade data, analytics, and AI solutions at scale. The Databricks data intelligence platform integrates with cloud storage and security in your cloud account and manages and deploys cloud infrastructure on your behalf. Scale your GCS data vertically and horizontally by connecting GCS to Databricks.
Why Connect Google Drive to Databricks?
- 360-degree Analysis: Access advanced reports and insights from your Google Drive data.
- Data Unification: Combine data from Google Drive with other sources for customized information and organization-wide tracking.
- Scalable Storage: Use Google Drive for both unprocessed and processed data storage.
- ACID Transactions: Databricks’ Delta Lake format supports concurrent data reads and writes with ACID guarantees
- No More CSVs or Scripts: Eliminate custom code and focus on improving your data stack.
Read about connecting Google Sheets to Databricks for efficient data reporting and analysis.
Hevo simplifies setting up Google Drive to Databricks Integration, enabling real-time data updates and seamless connectivity. This automation continuously moves your data without requiring any manual labor. Check out the cool features of Hevo:
- Transformations: A simple python-based drag-and-drop data transformation technique that allows you to transform your data for analysis.
- Schema Management: It automatically detects the schema of incoming data and maps it to the destination schema.
- 24/7 Live Support: Round-the-clock support via chat, email, and calls.
Thousands of customers trust Hevo with their ETL process. Join them today and experience seamless data integration.
Get Started with Hevo for FreeMethods To Setup Google Drive To Databricks Connection
Method 1: How to connect Google Drive to Databricks Using Hevo?
Step 1: Configure Google Drive as a Source
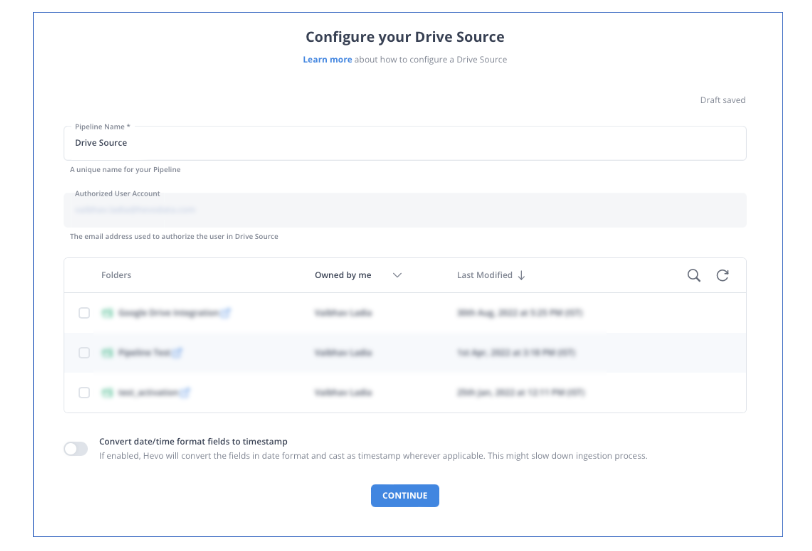
Step 2: Configure Databricks as a Destination
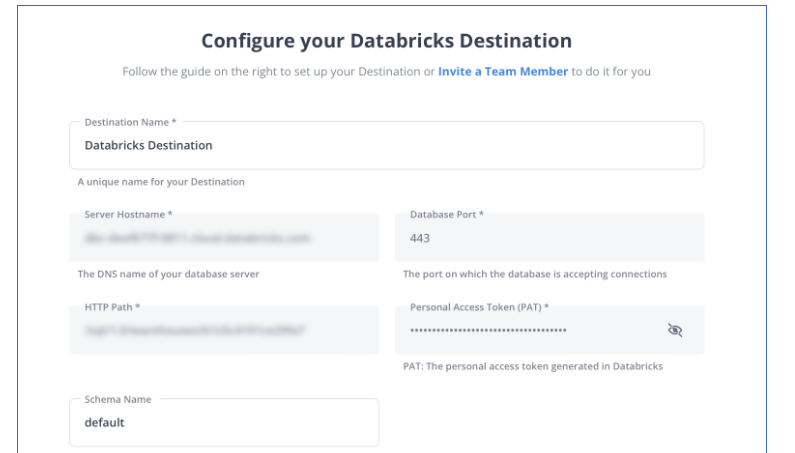
Now, your source is connected to the destination, and the pipeline will start ingesting the data. Hevo automatically maps schema, and you will receive alerts in case of any error.
Method 2: How To Connect Google Drive To Databricks Manually?
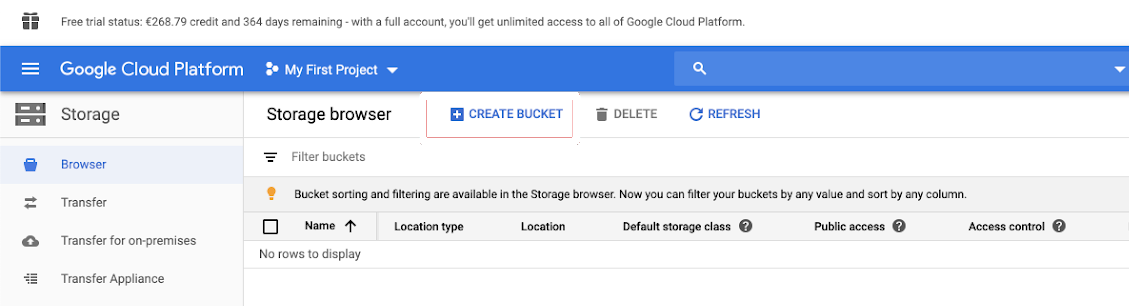
Step 1: Create a Google Cloud Storage bucket
- If you don’t have one, create a bucket in Google Cloud Storage.
Step 2: Enable Google Cloud APIs
- Enable the “Google Cloud Storage” API for your project from the Google Cloud Console.
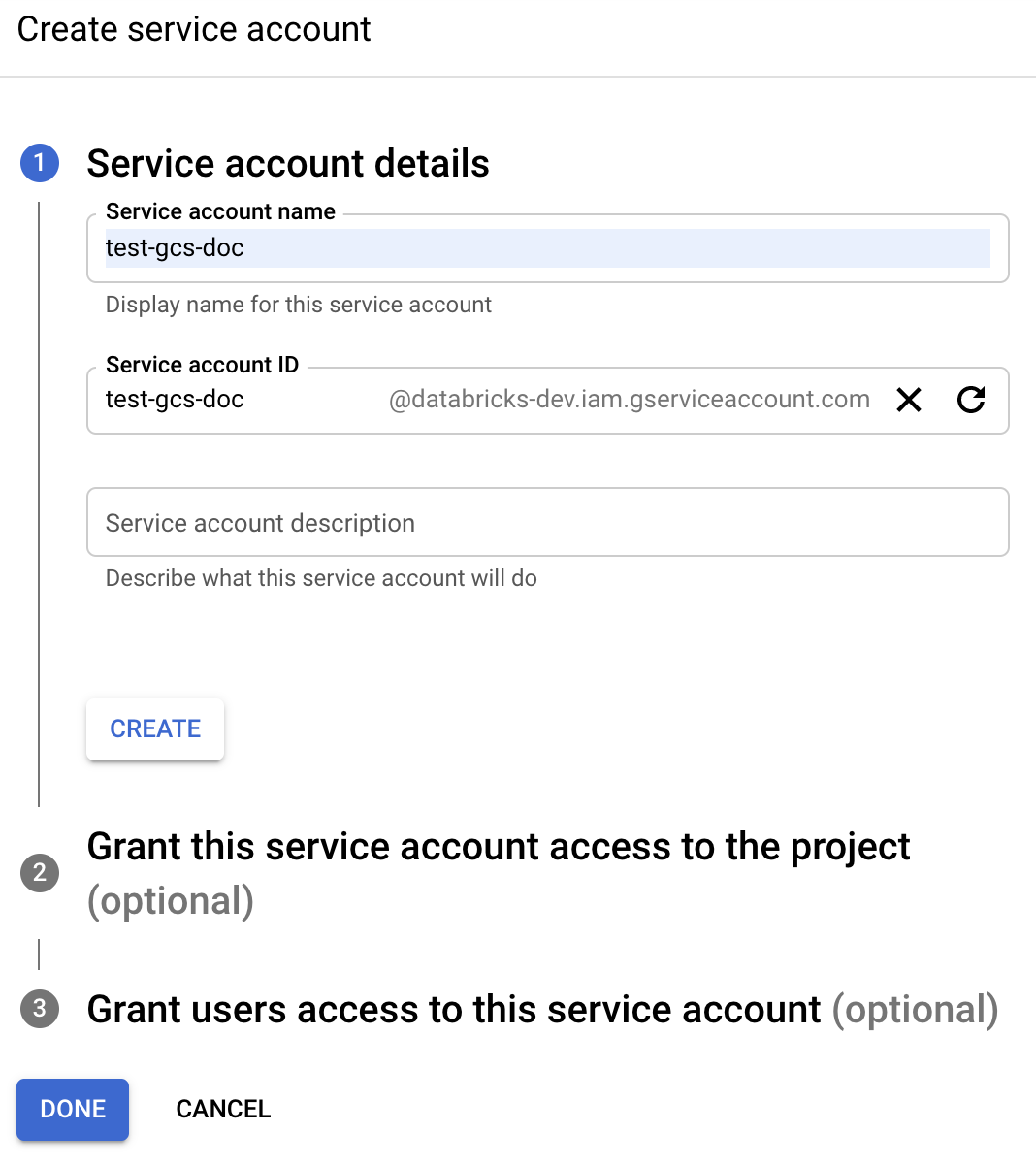
Step 3: Create a Service Account and Key
- Go to the Google Cloud Console → IAM & Admin → Service Accounts.
- Create a service account with permissions (e.g., Storage Object Admin).
- Download the JSON key file.
Step 4: Upload JSON Key to Databricks
- In Databricks, go to the workspace and upload the JSON service account key file to a location (e.g., DBFS).
Step 5: Set Up Google Cloud Storage Mount in Databricks
- You’ll use the Databricks CLI or notebooks to configure the mount. In a Databricks notebook:
# Set environment variables to authenticate using the service account key
dbutils.fs.mount(
source = "gs://<your-bucket-name>/",
mount_point = "/mnt/google_drive",
extra_configs = {"google.cloud.auth.service.account.json.keyfile": "/dbfs/path/to/your/service_account_key.json"}
)Step 6: Access the Mounted Google Drive
- Once mounted, you can access the data stored in Google Cloud Storage (which is backed by Google Drive if configured) through Databricks as follows:
display(dbutils.fs.ls("/mnt/google_drive"))Limitations of Manual Method
- Indirect Integration: Databricks does not natively support Google Drive; instead, you would need to use Google Cloud Storage (GCS) or APIs, which adds complexity.
- Authentication Complexity: Service account setup and credential management are complex and prone to errors.
- Limited Performance: API or gcsfuse mounting GCS may incur slower file transfer compared to native cloud storage integrations.
- Manual Data Sync: This process of manual data sync with Google Drive is not like any other cloud platform. It may require additional codes or steps in order to update regularly in Databricks.
- Minimal Accessibility of Google Drive Features: You are unlikely to get complete accessibility to the collaborative features provided by Google Drive, such as real-time editing or version control.

You can also read more about:
- Google Cloud Storage to Databricks
- Google Analytics 360 to Databricks
- Google Analytics 4 to Databricks
Conclusion
Integrating Google Drive with Databricks will give powerful data management capabilities and improve data accessibility and analysis. In this article, you learned the methods for this integration, such as using Hevo, a no-code approach, and manual connections using Google Cloud Storage. Regardless of the method, this integration enhances data operations and scalability.
Experience fully automated, hassle-free data replication for Google Drive by immediately starting your journey with Hevo and Databricks. Try Hevo today for free and save your engineering resources. Explore a 14-day free trial and experience its rich features.
Share your experience understanding the Google Drive to Databricks Integration in the comments below! We would love to hear your thoughts.
Frequently Asked Questions
1. How do I connect Google Drive to Databricks?
a) Obtain Google Drive API Credentials
b) Install Necessary Libraries in Databricks
c) Authenticate and Access Google Drive
2. How to extract data from Google Drive?
To extract data from Google Drive, you can use Google Drive’s API or Google Cloud SDK to download files. Alternatively, sync files locally using the Google Drive desktop app and upload them manually.
3. How do I push data to Databricks?
To push data to Databricks, use the Databricks CLI or APIs to upload files. Alternatively, you can mount cloud storage (like AWS S3 or GCS) in Databricks and transfer data directly using dbutils.fs.put or dbutils.fs.cp.

Share it with your connections.
-
 Share To X
Share To X
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Copy Link
Copy Link



