

Communication and data management are essentials for running a business. Most corporations run their businesses over the cloud, with employees working worldwide. Cloud-based messaging and data storage have become essential to an organization’s day-to-day tasks.
This article will show you different ways to integrate Slack SQL Server, which will help you store your communication data and run queries efficiently.
Table of Contents
An Overview of Slack

Slack is a cloud-based messaging platform that allows different teams to collaborate and communicate seamlessly. It offers instant messaging and file-sharing services by organizing chats into channels, groups, and DMs, which can easily be created in Slack workspace.
Some of the most essential features provided by Slack include automating redundant tasks. The Slack AI feature helps summarize conversations and allows you to streamline work by integrating it with Google Drive, Google Calendar, and many more applications.
Hevo is a no-code data pipeline platform that supports Slack to SQL Server Integration. Its intuitive User interface ensures that data integration is simple and that the pipeline is set up in minutes.
- With its robust transformation capabilities, Hevo ensures that your data is always ready for analysis.
- Hevo’s cost-efficient pricing makes sure you only pay for what you use.
- Its fault-tolerant architecture ensures your data is always secure and there is no data loss
Try Hevo for free today to experience seamless migration of your data!
Get Started with Hevo for FreeAn Overview of SQL Server

SQL Server is a well-known and powerful Relational Database Management System (RDBMS) crafted by Microsoft Corporation. It provides data management abilities, such as storing, organizing, and retrieving large amounts of data.
The use of Transact Structured Query Language (TSQL) can help you manipulate and extract data with high precision. By leveraging the powers of SQL Server, you can generate useful reports that can help you decide your next best move in managing your business.
Also, take a look at the SQL Server Business Intelligence Stack and Components to get a detailed understanding of how you can work with SQL Server.
Methods to Integrate Slack SQL Server
Here are two of the most widely used methods to extract data from Slack to SQL Server.
Methods 1: Automatically Using Hevo Data for Slack SQL Server Integration in Just 2 Steps
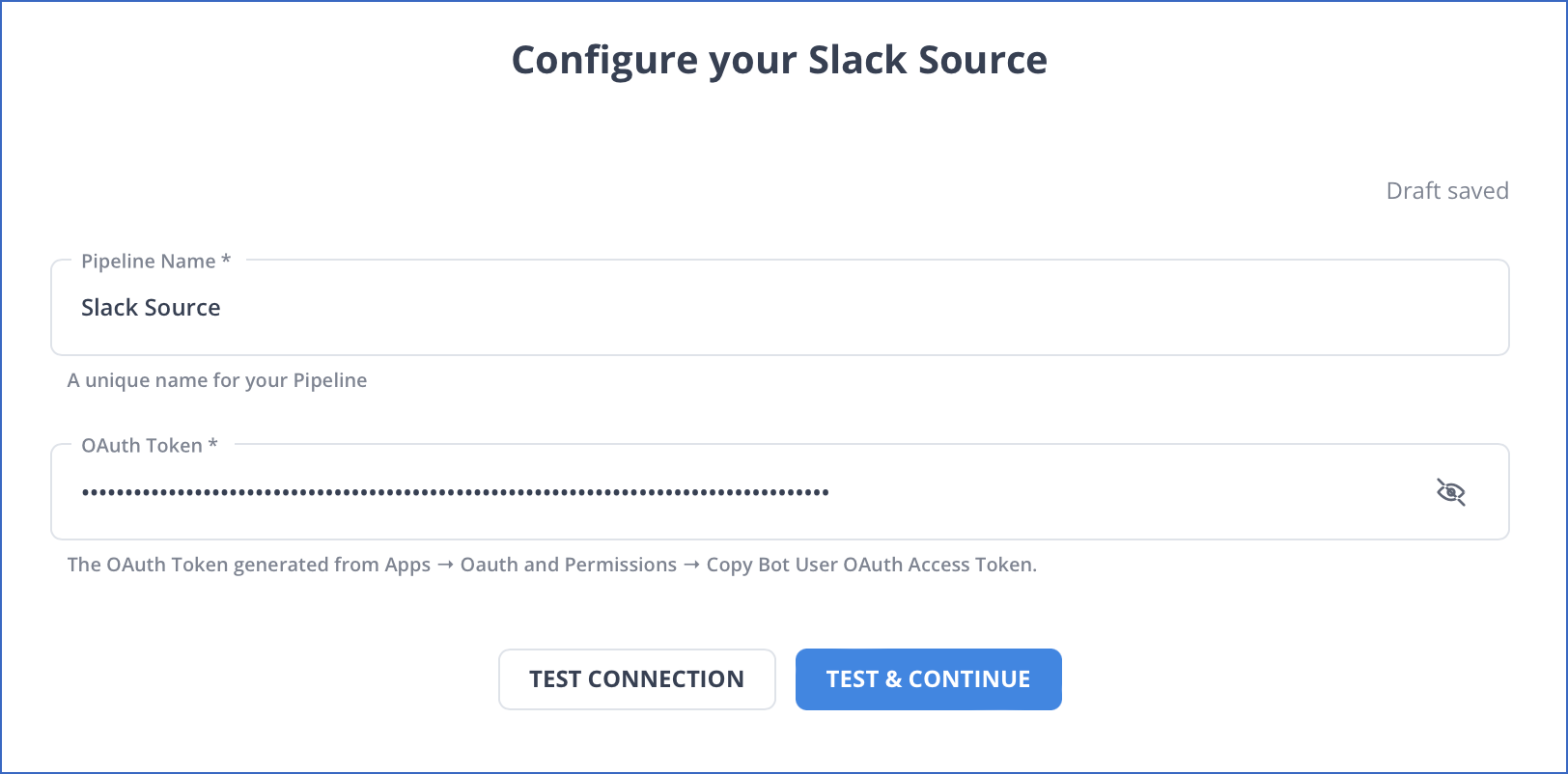
Step 1.1: Setting up Slack as a Source
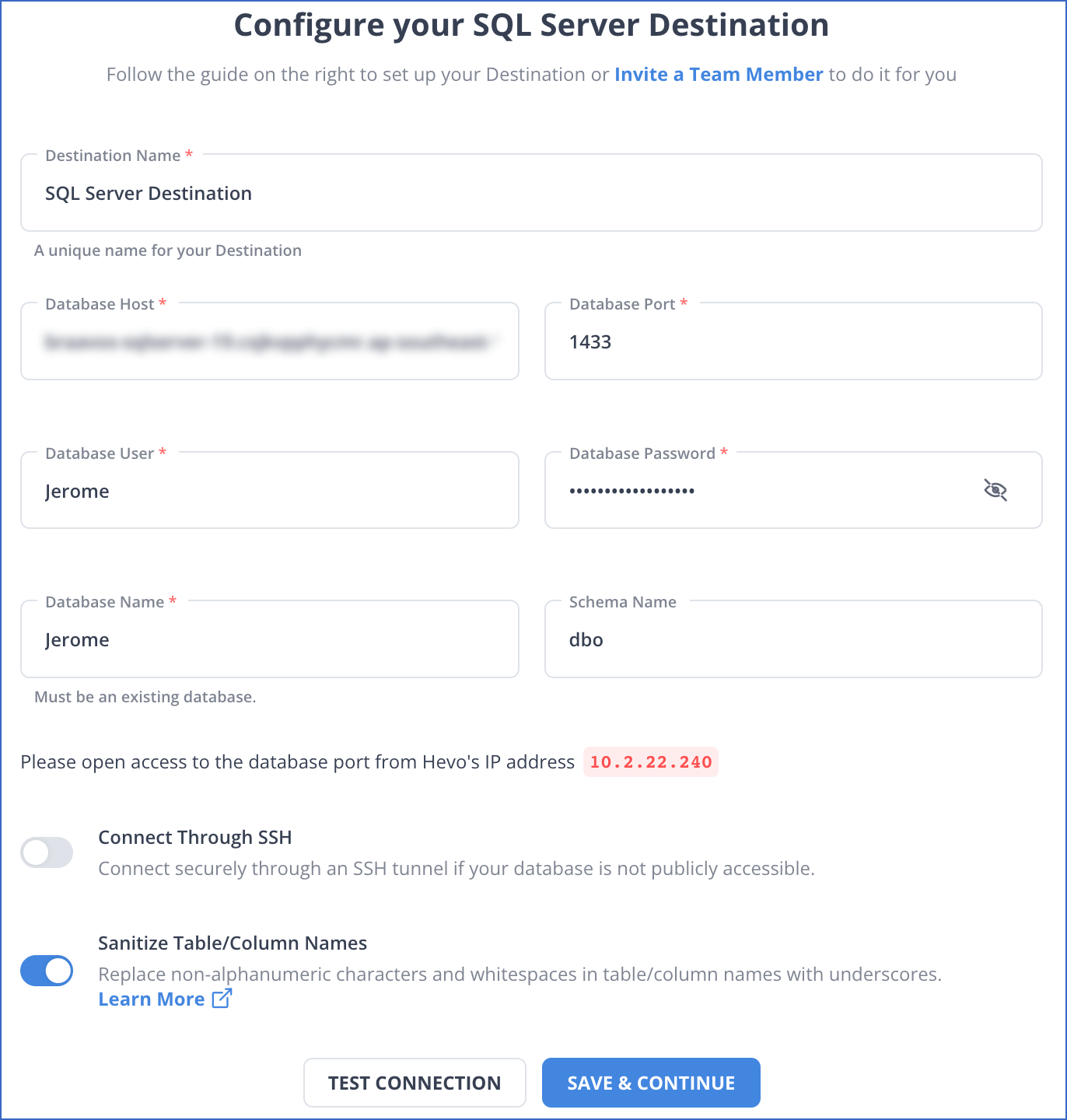
Step 1.2: Configuring SQL Server as a Destination
Key Features of Hevo Data
- Data Transformation: Hevo Data provides you with simple Python-based drag-and-drop data transformation techniques. It enables users to prepare the data for further analysis.
- Incremental Data Load: Hevo Data not only allows you to modify your data but also performs real-time data transfer on the modified data. This ensures proper bandwidth utilization at both source and destination.
- Automated Schema Mapping: Hevo Data arranges the destination schema to be compatible with the incoming data.
- Data Sync from One or Multiple Databases: You can configure your data pipeline in Hevo Data to extract your data from one or more database sources.

Method 2: Manually Using Slack Python SDK to Connect Slack with SQL Server
You can use Slack Python SDK to connect Slack with SQL Server. But before getting started, check out the prerequisite conditions.
Prerequisites
- You must have an active Slack account.
- You need to install the Slack Python SDK. Refer to the installation documentation to learn more.
- An application must be set up in order to extract data from Slack.
- You must have your SQL Server instance up and running.
Step 2.1: Extracting Data from Slack
Slack provides an API for extracting data. Combining conversation history and conversation list can be beneficial for acquiring all the channels and messages in each channel.
You can use the following Python code to extract the message data from Slack by entering your Slack API Token in the placeholder:
from slack_sdk import WebClient
import os
import time
SLACK_API_TOKEN = os.environ.get("SLACK_API_TOKEN")
slack_client = WebClient(token=SLACK_API_TOKEN)
def get_public_channels():
cursor = None
channels = []
while True:
response = slack_client.conversations_list(cursor=cursor)
for channel in response["channels"]:
channels.append(channel["id"])
cursor = response["response_metadata"]["next_cursor"]
if len(cursor) == 0:
break
else:
print("Pagination found, getting next entries")
time.sleep(3)
return channels
def get_channel_messages(slack_channels):
messages = []
for slack_channel in slack_channels:
cursor = None
while True:
channel_history = slack_client.conversations_history(channel=slack_channel, cursor=cursor)
for message in channel_history["messages"]:
if (message["type"] == "message"):
messages.append((slack_channel, message["text"]))
if bool(channel_history["has_more"]):
cursor = channel_history["response_metadata"]["next_cursor"]
else:
cursor = None
if cursor is None:
break
else:
print("Pagination found, getting next entries")
time.sleep(1.2)
return messages
slack_channels = get_public_channels()
messages = get_channel_messages(slack_channels)
print(messages)This code will help you retrieve message data from Slack messages except for the thread’s data. You can use the conversation replies method to extract messages from threads. Use this code to pull data from threads:
def get_thread_messages(slack_channel, ts):
messages = []
cursor = None
while True:
thread_replies = slack_client.conversations_replies(channel=slack_channel, ts=ts, cursor=cursor)
for message in thread_replies["messages"]:
if (message["type"] == "message"):
messages.append(message["text"])
if bool(thread_replies["has_more"]):
cursor = thread_replies["response_metadata"]["next_cursor"]
else:
cursor = None
if cursor is None:
break
else:
print("Pagination found, getting next entries")
time.sleep(1.2)
return messages
def get_channel_messages(slack_channels):
messages = []
for slack_channel in slack_channels:
cursor = None
while True:
channel_history = slack_client.conversations_history(channel=slack_channel, cursor=cursor)
for message in channel_history["messages"]:
if (message["type"] == "message"):
if ("thread_ts" in message):
for text in get_thread_messages(slack_channel, message["ts"]):
messages.append((slack_channel, text))
else:
messages.append((slack_channel, message["text"]))
if bool(channel_history["has_more"]):
cursor = channel_history["response_metadata"]["next_cursor"]
else:
cursor = None
if cursor is None:
break
else:
print("Pagination found, getting next entries")
time.sleep(1.2)
return messagesAfter retrieving the data from Slack, you need to transform it so that it matches the schema of the table to which you are going to move it. The code above will produce a list of tuples, which you can convert into any format you want.
Step 2.2: Loading Data to SQL Server
There are multiple ways of importing data into SQL Server, but the simplest method is using the BULK INSERT command in Transact-SQL. You can follow the syntax given here to import data to SQL Server by removing all the placeholder values:
BULK INSERT
{ database_name.schema_name.table_or_view_name | schema_name.table_or_view_name | table_or_view_name }
FROM 'data_file'
[ WITH
(
[ [ , ] BATCHSIZE = batch_size ]
[ [ , ] CHECK_CONSTRAINTS ]
[ [ , ] CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' } ]
[ [ , ] DATAFILETYPE =
{ 'char' | 'native' | 'widechar' | 'widenative' } ]
[ [ , ] DATA_SOURCE = 'data_source_name' ]
[ [ , ] ERRORFILE = 'file_name' ]
[ [ , ] ERRORFILE_DATA_SOURCE = 'errorfile_data_source_name' ]
[ [ , ] FIRSTROW = first_row ]
[ [ , ] FIRE_TRIGGERS ]
[ [ , ] FORMATFILE_DATA_SOURCE = 'data_source_name' ]
[ [ , ] KEEPIDENTITY ]
[ [ , ] KEEPNULLS ]
[ [ , ] KILOBYTES_PER_BATCH = kilobytes_per_batch ]
[ [ , ] LASTROW = last_row ]
[ [ , ] MAXERRORS = max_errors ]
[ [ , ] ORDER ( { column [ ASC | DESC ] } [ ,...n ] ) ]
[ [ , ] ROWS_PER_BATCH = rows_per_batch ]
[ [ , ] ROWTERMINATOR = 'row_terminator' ]
[ [ , ] TABLOCK ]
-- input file format options
[ [ , ] FORMAT = 'CSV' ]
[ [ , ] FIELDQUOTE = 'quote_characters']
[ [ , ] FORMATFILE = 'format_file_path' ]
[ [ , ] FIELDTERMINATOR = 'field_terminator' ]
[ [ , ] ROWTERMINATOR = 'row_terminator' ]
)]Besides this method, you can import data using SQL Server Slack API. In order to post to Slack from SQL Server, you have to use SSMS to upload data from SQL Server to Slack.
Get Started with Hevo for FreeLimitations of Using Slack Python SDK method
There are certain limitations associated with using Slack’s Python SDK that you must consider before following this method.
- Lack of Automation: This method lacks automation as you are required to export data from Slack and import it into SQL Server manually.
- Technical Knowledge Requirement: This method assumes that you have prior technical knowledge, as you are required to transform the data to suit the SQL Server table schema.
Benefits of Slack SQL Server Integration
- Real-Time Notifications: Get instant alerts in Slack for changes or updates in your SQL Server database.
- Improved Collaboration: Share SQL query results and reports with your team directly in Slack.
- Enhanced Productivity: Reduce context-switching by managing database notifications and discussions in one platform.
- Streamlined Monitoring: Keep track of database performance and issues through Slack channels.
- Automation: Use Slack bots to automate routine database tasks like query execution and reporting.
Also, take a look at how you can perform SQL Server Replication and Data Modeling in SQL Server Management Studio.
Use Cases of SQL Server Slack Integration
- Transferring data from Slack to SQL Server allows you to conduct data analysis on the Slack data and generate reports according to the patterns in communication.
- Integrating Slack SQL Server enables corporations to create a data backup. Slack has a limit for saving old data, so transferring data to SQL Server can be beneficial.
- When Slack SQL Server integration is automated, it reduces your efforts, saves you time, and allows you to focus on other essential tasks.
You can also check out how you perform Slack BigQuery Integration and also set up Slack Webhook URL to explore more ways you can migrate your Slack data.
You can also learn more about:
- Airflow SQL Server
- AWS RDS SQL Server Replication
- AWS RDS SQL Server Configuration and Setup
- Azure SQL to SQL Server
Conclusion
In this article, you have seen two useful methods of integrating Slack SQL Server. One of the methods uses Slack’s SDK to export data from Slack and then manually transfer it to SQL Server. However, this method lacks automation that most of the users strive for.
You can overcome technical and automation limitations by using Hevo Data. It provides an easy-to-use user interface that can automate the data transfer process with just a few clicks.
Sign up for a free 14-day trial to streamline your data integration process. You may examine Hevo’s pricing plans and decide on the best plan for your business needs.
Frequently Asked Questions (FAQs)
1. How do you download Slack content as a user?
You can use multiple ways to export Slack data. Here are two of the most widely used methods:
– Using Slack SDKs to import data.
– Using SaaS-based applications, such as Hevo Data,
2. Does Slack use SQL?
Yes, Slack uses MySQL for its database management, supporting its large-scale messaging and data operations.
3. How do I send a Slack message in SQL Server?
You can send a Slack message from SQL Server by using a webhook URL and setting up a SQL Server agent job or script to send HTTP POST requests to Slack.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link





