

Databricks is a platform that helps you extract value out of massive amounts of data and make use of it to help data teams in solving the world’s toughest problems, like the life sciences industry to find cures faster, the entertainment industry to deliver more personalized content, etc.
This article commences with an easy introduction to ETL (Extract, Transform and Load) and focuses on building ETL pipelines using Databricks. It provides a step-by-step guide for two different methods to perform ETL operations. The first method involves using Hevo Data’s No-Code Data Pipeline Solution. The second method uses Azure Databricks ETL, which is a completely manual process.
Table of Contents
Introduction to ETL

ETL, in simple terms, refers to the 3 phases (Extract, Transform, and Load) of Data Integration that are used to combine data from various sources. It is most frequently used to construct a Data Warehouse. Data is first extracted from a source system, transformed into an analyzable format, and then loaded into a specific location (majorly a Data Warehouse).
Introduction to Databricks

Databricks is a cloud-based platform that aims to accomplish the Data Lakehouse tasks in a single unified platform. Databricks sits on top of your existing data lake and can connect to AWS S3 and Google Cloud Storage, among other cloud storage options.
Databricks is built for Data Scientists, Data Engineers, and Data Analysts to assist them in combining the concepts of Data Science and Data Engineering across various cloud platforms. This connection makes the process of preparing data, experimenting, and deploying Machine Learning applications much easier.
The DataBricks technology is quicker than Apache Spark and claims to speed up development and innovation. It also increases security by standardizing the pipeline for producing Machine Learning tools. With just a few clicks, data processing clusters may be created and deployed. Moreover, it has several built-in Data Visualization options like Graphs, Bar Charts, etc.
Layers in Databricks Architecture
There are several built-in tools for Data Science, BI Reporting, and MLOps. However, the 2 important layers in Databricks are:
- Delta Lake: Delta Lake is a Storage Layer that helps Data Lakes be more reliable. Delta Lake integrates streaming and batch data processing while providing ACID (Atomicity, Consistency, Isolation, and Durability) transactions and scalable metadata handling. Furthermore, it is fully compatible with Apache Spark APIs and runs on top of your existing data lake.
- Delta Engine: The Delta Engine is a query engine that is optimized for efficiently processing data stored in Delta Lake.
Method 1: Setting Up Databricks ETL using Hevo Data
Use Hevo for a simple two-step method to migrate your data seamlessly to Databricks and create a strong data backup solution for the upcoming analytical workload.
Method 2: Extract, Transform, and Load using Azure Databricks
The first method is an entirely manual process and demands high-end programming expertise. Generally, you need to integrate Databricks with a Cloud Platform such as Azure, Google Cloud Platform, etc., for extracting, transforming, and loading data to a specific location.
What are the Methods to Set Up Databricks ETL?
Now, that you have a basic understanding of ETL, let’s have a look at the methods that are available to set up ETL Databricks. There are majorly 2 methods to set up Databricks ETL:
- Method 1: Extract, Transform, and Load using Azure Databricks
- Method 2: Setting Up Databricks ETL using Hevo Data
Let’s walk through these methods in detail, one by one.
Method 1: Setting Up Databricks ETL using Hevo Data
You can set up your data migration in 2 Steps with Hevo.
After logging into your Hevo account, click on “Create Pipeline” and configure your Source.
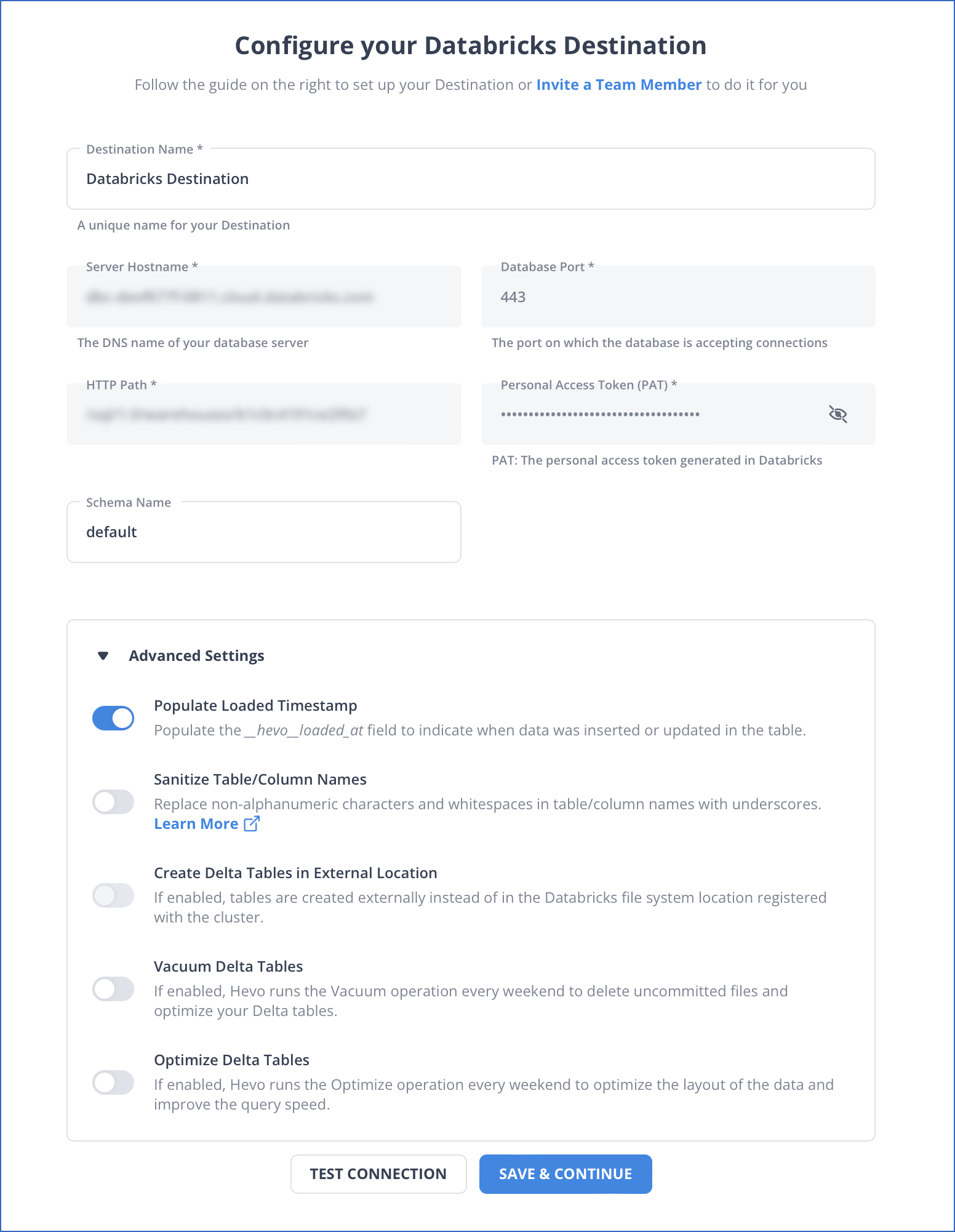
Then, after connecting with your source and selecting the objects you want to transfer, you need to select Databricks and configure the details as shown in the image. Finally, click on “Save & Continue.”
Advantages of using the Hevo Method
- Exceptional Security: It’s fault-tolerant ETL architecture guarantees that no information or data will be lost, so you need not worry.
- Scalability: Hevo Data for scale is developed to be scaled out at a fraction of the cost with almost zero delay, making it suitable for contemporary extensive ETL requirements.
- Built-in Connectors: Hevo Data has more than 150 connectors, including MongoDB as a source and Google BigQuery as a destination, databases, and SaaS platforms; it even has a built-in webhook and RESTful API connector designed specifically for custom sources.
- Incremental Data Load: It utilizes bandwidth efficiently by only transferring modified data in real time.
- Auto Schema Mapping: Hevo Data manages schema automatically by detecting the incoming data format and copying it to the destination schema. You can select between full and incremental data mappings according to your data replication needs.
- Easy to use: Hevo Data offers a no-code ETL or ELT load pipeline platform.
Method 2: Extract, Transform, and Load using Azure Databricks
In this method, you will use Azure Synapse Connector for Azure Databricks ETL to load data to Azure Databricks. Before starting with the process, you have a few prerequisites to go through.
- An Azure account.
- Create an Azure Synapse with admin privileges. Also, create a server-level firewall rule, and a master key. You can refer to this link for more information.
- Create an Azure Blob Storage account and make sure to retrieve the access key for the same. You can refer to this link for more information.
- Create an Azure Data Lake Storage Gen2 Storage account with administrative privileges. You can refer to this link for more information.
- Create a service principal that can access Azure AD Application resources. You can refer to this link for more information.
- Basic understanding of Scala language.
Now, follow the steps below to set up Azure Databricks:
- Step 1: Create an Azure Service
- Step 2: Create a Spark Cluster in Azure
- Step 3: Create Notebooks in Azure Workspace
- Step 4: Extract Data from the Storage Account
- Step 5: Transform the Extracted Data
- Step 6: Load Transformed Data into Azure Synapse
Step 1: Create an Azure Service
Follow the steps below to create an Azure Service:
- Log in to your Azure portal and select Create a resource > Analytics > Azure Databricks as shown in the image below.

- This will lead you to a new window, where you will be asked for a couple of parameters like Workspace Name, Subscription, Resource Group, Location, and Pricing Tier. Fill up the details and select Pin to dashboard > Create.
Step 2: Create a Spark Cluster in Azure
Follow the steps below to create a Spark Cluster in Azure:
- Go to the Azure Databricks ETL Service that you created in your last step, then select Launch Workshop > New Cluster.
- This will redirect you to a new window where you will be asked for a couple of information like Cluster Name, Cluster-Mode, etc. as shown in the image below.
NOTE: Ensure to select the “Terminate after specific minutes of inactivity” checkbox.

- Once you have filled up all the necessary details, click on the “Create Cluster” button.
Step 3: Create a Notebooks in Azure Workspace
In this step, you will simply create a file system in the Azure Data Lake Storage Gen2 account. Furthermore, you will run a couple of ETL code snippets to configure the storage account. Follow the steps given below for the same:
- Go to the Azure Service that you create before, and select Launch Workspace > Workspace > Create > Notebook.
- This will open up a Create Notebook dialog box where you will have to fill up a couple of parameters like Name, Language, and Cluster. For name, you can give an appropriate name as per your choice. However, select “Scala” for the language and the Spark Cluster that you created in Step 2 for the cluster parameter. Once done, click on the “Create” button.
- Following is the Session Configuration code snippet. Copy-paste it into your Azure Notebook.
val appID = "<appID>"
val secret = "<secret>"
val tenantID = "<tenant-id>"
spark.conf.set("fs.azure.account.auth.type", "OAuth")
spark.conf.set("fs.azure.account.oauth.provider.type", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
spark.conf.set("fs.azure.account.oauth2.client.id", "<appID>")
spark.conf.set("fs.azure.account.oauth2.client.secret", "<secret>")
spark.conf.set("fs.azure.account.oauth2.client.endpoint", "https://login.microsoftonline.com/<tenant-id>/oauth2/token")
spark.conf.set("fs.azure.createRemoteFileSystemDuringInitialization", "true")- Following is the Account Configuration code snippet. Similar to the last code snippet, copy-paste it into your Azure Notebook.
NOTE: Replace the placeholder values for app-id, secret, tenant-id, and storage-account-name with the values you acquired while completing the prerequisites. Also, replace the placeholder value for file-system-name with the name of your choice.
val storageAccountName = "<storage-account-name>"
val appID = "<app-id>"
val secret = "<secret>"
val fileSystemName = "<file-system-name>"
val tenantID = "<tenant-id>"
spark.conf.set("fs.azure.account.auth.type." + storageAccountName + ".dfs.core.windows.net", "OAuth")
spark.conf.set("fs.azure.account.oauth.provider.type." + storageAccountName + ".dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
spark.conf.set("fs.azure.account.oauth2.client.id." + storageAccountName + ".dfs.core.windows.net", "" + appID + "")
spark.conf.set("fs.azure.account.oauth2.client.secret." + storageAccountName + ".dfs.core.windows.net", "" + secret + "")
spark.conf.set("fs.azure.account.oauth2.client.endpoint." + storageAccountName + ".dfs.core.windows.net", "https://login.microsoftonline.com/" + tenantID + "/oauth2/token")
spark.conf.set("fs.azure.createRemoteFileSystemDuringInitialization", "true")
dbutils.fs.ls("abfss://" + fileSystemName + "@" + storageAccountName + ".dfs.core.windows.net/")
spark.conf.set("fs.azure.createRemoteFileSystemDuringInitialization", "false")- Once done, press the SHIFT + ENTER combination keys to execute the code.
- Ingest data into your storage account for initiating the Azure Databricks ETL process. You can refer to this link for the same.


Step 4: Extract Data from the Storage Account
In this step, you will be extracting data from the Azure Data Lake Storage Gen2 account that you created in your previous steps. Copy-paste the code given below into your Azure Notebook that you created earlier.
val df = spark.read.json("abfss://" + fileSystemName + "@" + storageAccountName + ".dfs.core.windows.net/small_radio_json.json")NOTE: Make sure to replace the parameters given inside the parenthesis with your values. Press the SHIFT + ENTER combination keys to execute the code.
Step 5: Transform the Extracted Data
In this step, you will be transforming the data (i.e. retrieving specific columns that are necessary and dumping all the irrelevant data) that you extracted in the last step. Copy-paste the code snippet given below in your Azure Notebook.
val specificColumnsDf = df.select("col_x", "col_y", "col_z", "col_n", "col_m")
specificColumnsDf.show()NOTE: Make sure to change the parameters given inside the parenthesis with the column names that you want to retrieve. Also, you can add more columns, if need be. Press the SHIFT + ENTER combination keys to execute the code.
Step 6: Load Transformed Data into Azure Synapse
Follow the steps below to load the data that you transformed in the last step into Azure Synapse:
- Execute the code given below to configure the access from Azure Databricks ETL to Azure Storage account.
val blobStorage = "<blob-storage-account-name>.blob.core.windows.net"
val blobContainer = "<blob-container-name>"
val blobAccessKey = "<access-key>"- Now, specify a temporary folder. This is necessary to transfer data between Azure Databricks ETL and Azure Synapse because the Azure Synapse connector uses Azure Blob Storage that requires temporary storage to upload data. Execute the code given below for the same.
NOTE: Use the credentials you must have acquired while completing the prerequisites for this method.
val tempDir = "wasbs://" + blobContainer + "@" + blobStorage +"/tempDirs"- Execute the code below to store the Azure Blog Storage access keys (that you must have acquired while going through the prerequisites of this method) in the configuration.
val acntInfo = "fs.azure.account.key."+ blobStorage
sc.hadoopConfiguration.set(acntInfo, blobAccessKey)- Now, to connect to the Azure Synapse instance, you need to provide the values that you must have acquired while creating an Azure Synapse Analytics service as a prerequisite. Execute the code given below after replacing the necessary parameters’ values:
//Azure Synapse related settings
val dwDatabase = "<database-name>"
val dwServer = "<database-server-name>"
val dwUser = "<user-name>"
val dwPass = "<password>"
val dwJdbcPort = "1433"
val dwJdbcExtraOptions = "encrypt=true;trustServerCertificate=true;hostNameInCertificate=*.database.windows.net;loginTimeout=30;"
val sqlDwUrl = "jdbc:sqlserver://" + dwServer + ":" + dwJdbcPort + ";database=" + dwDatabase + ";user=" + dwUser+";password=" + dwPass + ";$dwJdbcExtraOptions"
val sqlDwUrlSmall = "jdbc:sqlserver://" + dwServer + ":" + dwJdbcPort + ";database=" + dwDatabase + ";user=" + dwUser+";password=" + dwPass- Execute the code snippet given below to transfer the transformed data as a table in Azure Synapse>
NOTE: You can replace the name of the table with a name of your choice.
spark.conf.set(
"spark.sql.parquet.writeLegacyFormat",
"true")
renamedColumnsDF.write.format("com.databricks.spark.sqldw").option("url", sqlDwUrlSmall).option("dbtable", "SampleTable") .option( "forward_spark_azure_storage_credentials","True").option("tempdir", tempDir).mode("overwrite").save()That’s it! You have now successfully performed ETL operations using Azure Databricks.
Learn how Databricks Lakehouse Monitoring can enhance your ETL setup with real-time insights and performance tracking.
Limitations of using Azure Databricks
Although the above-mentioned method works perfectly for any data that you want to transfer, it has some drawbacks. The following are the limitations of using this:
- It is a manual process that requires high-end technical and programming proficiency. A simple mistake during this process could lead to major setbacks.
- It requires you to integrate Azure and Databricks. This is a time-consuming process in itself, making the whole thing an extremely tedious and technical task.
- You can only move data between Azure Databricks and Azure Synapse. If you need to transfer data to some other Cloud platform, then you need to integrate Databricks with that particular platform.
With that being said, there is a better solution to all these problems of yours. The solution comes as Hevo Data and its Databricks connector. For more information, keep reading!
You can also read more about:
- Amazon S3 to Databricks
- BigQuery to Databricks
- Databricks Connect to SQL Server
- Power BI to Databricks Integration
Conclusion
The article introduced you to ETL (Extract, Transform and Load) in general and further elaborated on Databricks ETL. It also provided a comprehensive guide on how to perform ETL operations using Azure Databricks and Hevo Data. Furthermore, it displayed how Hevo Data is a better choice for any individual/company over any other platform. Try a personalized demo with us for free to learn more about Hevo.
FAQ
What is the difference between Snowflake and Databricks for ETL?
Snowflake is primarily a cloud data warehouse optimized for storage and querying. At the same time, Databricks is a data processing platform built on Apache Spark designed for large-scale data engineering, machine learning, and analytics.
What kind of tool is Databricks?
Databricks is a unified data analytics platform that combines data engineering, data science, and machine learning. It is designed for big data processing and analysis, enabling users to build scalable data pipelines, perform advanced analytics, and collaborate in a cloud-based environment.
Is Databricks Python or PySpark?
Databricks supports both Python and PySpark. PySpark is a Python API for Apache Spark, and it is commonly used within Databricks for writing data processing and ETL jobs. Databricks also supports other languages like Scala, SQL, and R, but Python and PySpark are the most popular for data engineering tasks.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link



