



JavaScript and NodeJs Open Source ETL Tools have gained popularity. Because these tools help keep business costs low and offer flexibility in building applications simultaneously. They also offer a simple UI (User Interface) and help users easily set up the ETL process.
Out of all the methods available to perform the NodeJs ETL and JavaScript ETL, you must choose the one that suits your use case. That depends on your data volume, number of sources, budget, etc. This blog is a comprehensive deep dive into all of that.
In this blog on Automating ETL Processes with NodeJS Open Source ETL Tools, we will cover the best JavaScript and NodeJs Open Source ETL Tools and describe their features briefly, along with a few limitations of leveraging these tools.
Table of Contents
What is the ETL Process?
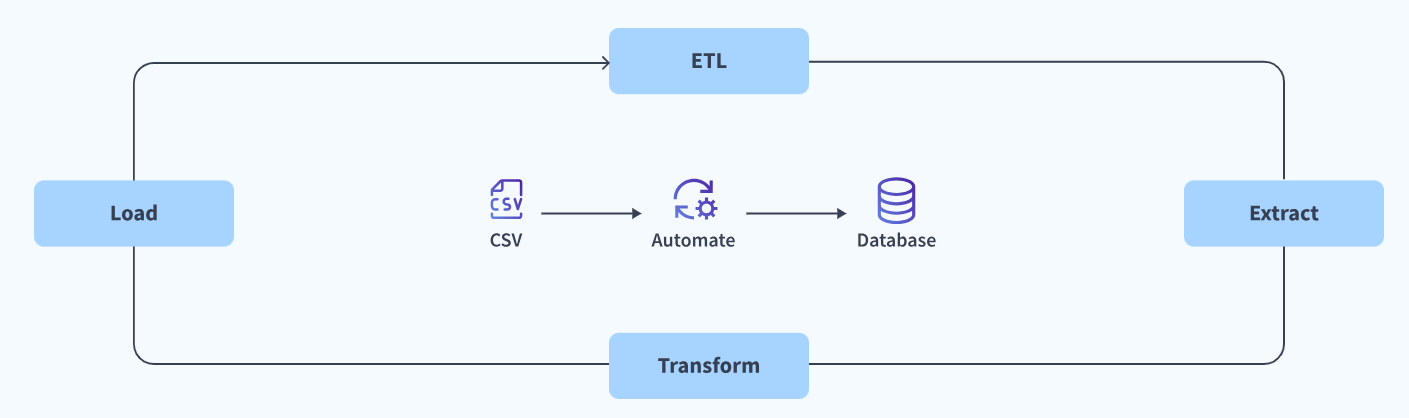
The ETL process consists of 3 steps:
- Extraction: Extraction is an essential part of the ETL process as it helps unify Structured and Unstructured data from diverse sources such as Databases, SaaS applications, files, CRMs, etc. Extraction Tools simplify this process by allowing users to extract valuable information with just a few clicks, all without having to write any complex ETL code.
- Transformation: Transformation is converting the extracted data into a common format so that it can be better understood by a Data Warehouse or a BI (Business Intelligence) tool. Some transformation techniques include sorting, cleaning, Removing Redundant Information, and Verifying Data from data sources.
- Loading: Loading is the process of storing the transformed data into a destination, normally a Data Warehouse. It also supports the analysis of the data using various BI tools to gain valuable insights and build reports and dashboards. The Loading stage is crucial as the customer data is visualized using different BI tools after this stage.
The given figure highlights the stages of the ETL process:

What is Node.js?

Node.js is a cross-platform, Open-Source, and back-end JavaScript runtime environment that uses a V8 engine to execute JavaScript code outside a web browser. It is mostly used to build scalable applications and web pages. Node.js is an asynchronous technology, meaning data is transmitted through networks without any time constraints.
The event-driven runtime of Node.js handles all types of HTTP requests and sleeps when it’s not required. This enables developers to use JavaScript and write server-side scripts to produce dynamic web content before the content is sent to the user’s web browser.
Node.js consists of the “.js” standard filename extension for JavaScript code and represents a “JavaScript everywhere” paradigm, thereby unifying web application development around a single programming language, rather than different languages for server-side and client-side scripts.
JavaScript and NodeJs Open Source ETL Tools can be slightly complicated for non-technical users but are the best tools when it comes to handling critical Big Data jobs that demand enterprise-level performance.
Building an ETL Node js involves utilizing various libraries and frameworks to handle data extraction, transformation, and loading tasks.
Hevo offers powerful ETL capabilities for seamless data integration. It provides scalable, hassle-free solutions with built-in connectors and real-time data processing.
Streamline your ETL workflows with Hevo’s robust platform today! We will take care of your data while you focus on better insights.
Elevate your ETL processes with HevoWhy Choose Nodejs for ETL?
Node.js is a popular choice for ETL (Extract, Transform, Load) processes due to several key advantages:
- Non-blocking I/O and Event-Driven Architecture: Node.js applies an event-driven, non-blocking I/O model, which makes it efficient and appropriate for I/O-intensive tasks. Most of the time, the ETL process involves enormous volumes of data to be processed, so Node.js will be very useful in managing multiple data streams concurrently.
- JavaScript as a Universal Language: Many organizations already use JavaScript across their tech stack (front-end, back-end, etc.). Using Node.js for ETL allows teams to maintain a consistent language across the board, reducing the learning curve.
- Cross-Platform Compatibility: Node.js is cross-platform, which allows ETL applications to run on various operating systems without modification, enhancing portability and flexibility.
Building a simple ETL pipeline in Nodejs
Prerequisites
Step 1: Initialize the Nodejs application
Open your terminal and run the following command to initialize your nodejs application.
npm init --yStep 2: Install the Required Dependencies
Run the following command to install the required dependencies:
npm install csv-parser mongodb dotenvStep 3: Extraction Phase
Step 3. a) Set up an FS module with all file-related operations. To set up an FS module, run the command:
const fs = require('fs');Step 3. b) We need to create an extract data function that will extract your data from the .csv files. To create this function, run the following command:
const extractData = (csvDataPath) => {
return new Promise((resolve, reject) => {
const data = [];
fs.createReadStream(csvDataPath)
.pipe(csvParser())
.on('data', (item) => {
data.push(item);
})
.on('end', () => {
resolve(data);
})
.on('error', (error) => {
reject(error);
});
});
};Step 4: Transformation Phase
We will perform this phase to redefine and structure our data properly.
const transformData = (csvData) => {
return csvData.map((items) => ({
name: items.NAME.trim(), // Trim whitespace from the Name valu
career: items.CAREER.trim(), // Trim whitespace from the career value
}));
};Step 5: Load the Data
Set up your mongoDB connection string and run this code snippet to load your data into your database efficiently.
const loadData = async (transformedData, databaseName, collectionName, connectionString) => {
const client = new MongoClient(connectionString, {
useNewUrlParser: true,
useUnifiedTopology: true,
});
try {
await client.connect();
console.log('Connected to MongoDB successfully.');
const db = client.db(databaseName);
const collection = db.collection(collectionName);
const response = await collection.insertMany(transformedData);
// console.log("RESPONSE", response);
console.log(`${response.insertedCount} CSV Data Successfully loaded to MongoDB.`);
} catch (error) {
console.error('Error Connecting MongoDB', error);
}
await client.close();
};
extractData(csvDataPath)
.then((rawData) => {
const transformedData = transformData(rawData);
return loadData(transformedData, databaseName, collectionName, connectionString);
})
.catch((error) => {
console.error('Failed to extract or load data into MongoDB:', error);
});Top 6 JavaScript and NodeJs Open Source ETL Tools
Choosing the best JavaScript and NodeJs Open Source ETL Tool can be an exhausting task as each tool has its advantages and disadvantages.
Generally, companies opt for tools that are regularly updated and monitored by a large community and bring in new features too. Nodejs ETL is a powerful tool for managing data flows within your applications. Here is a comprehensive list of the best JavaScript and Nodejs Open Source ETL Tools:
1) Nextract
Nextract is an ETL Tool built on Node.js Streams, designed by Github contributor Chad Auld. It is suited for beginner and mid-level programmers.
The main goal of Nextract is to help developers make their work easier by using the flexible and asynchronous nature of the Node.js runtime environment as compared to other Java-based ETL Tools.
By using npm packages (JavaScript packages), you can extend Nextract’s capabilities. This Nodejs Open-Source ETL Tool supports multiple databases, including Postgres, MySQL, MSSQL(Microsoft SQL Server), MariaDB, Oracle, and many more.
It can extract data from database queries and reflect the results onto tables. It works best with CSV and JSON files and by adding plug-ins, you can perform additional ETL operations like Sorting, Filtering, and Math.
The only limitation of Nextract is that it cannot work with Big Data as it runs on the resources of a single machine.

2) Datapumps
Datapumps is a JavaScript and NodeJs Open Source ETL Tool that uses “pumps” to read inputs and write outputs. An example can include exporting data from MySQL to Excel using a single pump. In case you work with complex data, you can create groups of pumps to export data.
Datapumps supports ETL processes such as Data Transformation, Encapsulation, Error Handling & Debugging. One limitation of Datapumps is that they cannot perform the ETL processes on their own and can only pass data in a controlled manner.
You can add “mixins” to make it efficient. Mixins help import, export, and transfer your data. Currently, Datapumps support 10 types of mixins.

3) ETL
ETL is a JavaScript and NodeJs Open Source Tool that helps perform ETL processes from MySQL to PostgreSQL. Github contributor John Skillbeck developed it and is one of the first NodeJs Open Source ETL Tools created.

4) Empujar
Empujar is a NodeJs open-source ETL Tool that helps extract data and perform backup operations. It is developed by TaskRabbit and takes advantage of Node.js’s asynchronous behavior to run ETL data operations in series or parallel.
It uses a Book, Chapter, and Page format to represent data. Top-level objects are known as Books and they contain sequential Chapters with Pages that can run in parallel up to a limit that you can set.
This tool integrates with different types of databases, including MySQL, FTP, S3, Amazon Redshift, and many more.

5) Extraload
Extraload is a lightweight ETL Tool for Node.js that moves data from files into databases and between databases. Github contributor Alyaton Norgard developed it.
It processes ETL operations quickly as it uses JavaScript coding and Node.js’s time-saving non-blocking programming. Along with ETL operations, Extraload also updates search platform indexes like Apache Solr.
This tool also houses API reference pages that explain how to write scripts and create drivers.


6) Proc-that

Proc-that is one of the Nodejs ETL Framework tools. Although it allows JavaScript scripting, it is developed in TypeScript, a scalable JavaScript language. proc—which provides Node’s asynchronous task streaming. The greater capability of TypeScript to operate on sophisticated tools and functions was enhanced by js.
You may import proc, that’s an ETL tool, and add its integrated transformers and loaders by following the instructions on its GitHub page. The developers of proc-that welcome you to add your own extractors, transformers, and loaders to their list in the proc-that GitHub repository if you wish to use them in your own applications. Nodejs ETL tool, Proc-that has a build-status failing badge as of this writing, so you might want to check that before you begin.
Limitations of JavaScript & NodeJs Open Source ETL Tools
Although JavaScript and NodeJs open-source ETL Tools can provide a solid backbone for your ETL Pipeline, they have a few limitations, especially when it comes to providing support.
As these tools are work-in-progress tools, many of them are not fully developed and are not compatible with multiple data sources. Some of the limitations of these tools include:
- Enterprise Application Connectivity: Companies are not able to connect a few of their applications with NodeJs Open Source ETL Tools due to compatibility reasons.
- Management & Error Handling Capabilities: Many Open-Source ETL Tools, including Nodejs ETL, lack error-handling capabilities, making error handling difficult.
- Large Data Volumes & Small Batch Windows: Many NodeJs open-source ETL Tools need to analyze large data volumes but can process the data in small batches only. This is because many of these tools are Command-Line Interfaces and need both the power of Node.js and the ETL tool to function effectively.
- Complex Transformation Requirements: Companies that have complex ETL requirements cannot use NodeJs open-source ETL Tools. This is because they often lack support for performing complex transformations.
- Lack of Customer Support Teams: As Open-Source ETL Tools are managed by communities and developers all around the world, they do not have specific customer support teams to handle issues.
- Poor Security Features: Being Open-Source causes these tools to have poor security infrastructure and become prone to many cyber attacks.
In-Depth Analyses of Popular Open Source Tools
- Open Source ETL Tools
- PostgreSQL ETL Tools
- Python ETL Tools
- Top 12 Open-Source Ci/Cd Tools
- Top 10 Tableau Open Source
- 5 Best Open-Source Data Replication Tools
- 13 Best Data Ingestion Open Source
- MongoDB Open Source
- Snowflake Open Source
- NodeJS Open source ETL tools
Conclusion
This article gave a comprehensive list of the best JavaScript and NodeJs open-source ETL Tools. It also gave an introduction to the ETL Process and Node.js technology. It further explained the features of these tools.
Finally, it highlighted some of the limitations as well. Overall, JavaScript and NodeJs open-source ETL Tools provide all types of users to work with both technologies seamlessly. They efficiently interrelate both these technologies to help companies gather valuable & actionable insights.
In case you want to integrate data into your desired Database/destination, then Hevo Data is the right choice for you! It will help simplify the ETL and management process of both the data sources and the data destinations, making Nodejs ETL easy.
FAQ
Is Nodejs suitable for data processing?
Node.js is suitable for certain types of data processing, particularly those that involve I/O-bound operations, such as reading and writing files, streaming data, and handling network requests. Its non-blocking I/O model allows it to efficiently process multiple data streams concurrently.
2. Can u fetch it from Nodejs?
Yes, you can fetch data from Node.js. Node.js can request HTTP to external APIs, databases, or other data sources using modules like axios, node-fetch, or the built-in HTTP and HTTP modules.
3. Is JavaScript suitable for ETL?
JavaScript, the language on which Node.js is based, is also suitable for ETL tasks when used in the context of Node.js. JavaScript’s versatility and the availability of numerous libraries for data manipulation and integration make it a strong candidate for ETL processes.
4. Is node suitable for ETL?
Node.js is good for ETL (Extract, Transform, Load) tasks. Its event-driven, non-blocking architecture makes handling I/O-intensive operations like reading, transforming, and loading data efficiently. Node.js can manage concurrent processes effectively, making it suitable for large-scale ETL tasks, real-time data processing, and integration.
Want to take Hevo for a spin? Sign Up for a 14-day free trial and experience the feature-rich Hevo suite firsthand.
Share your experience of learning about the best JavaScript and NodeJs Open Source ETL Tools in the comments section below.
Share it with your connections.
-
 Share To LinkedIn
Share To LinkedIn
-
 Share To Facebook
Share To Facebook
-
 Share To X
Share To X
-
 Copy Link
Copy Link



